GPU并行光栅化,加速计算光刻
随着半导体制造不断向更先进的纳米节点推进,计算光刻已从辅助环节,演变为先进芯片设计的核心支柱。掩模合成、光刻仿真以及光学邻近校正(OPC)如今对精度和计算吞吐量提出了前所未有的要求。在这些工作流程的核心,正是光栅化(rasterization),即将复杂的几何版图转换为超高分辨率像素网格的过程。
为何光栅化在光刻中愈发重要
光栅化常与计算机图形学关联,但在EDA领域,它的作用要关键得多。在计算光刻中,经过光栅化的版图用于模拟光线如何透过掩模传播,以及光刻胶在纳米尺度下的响应。与图形应用不同,在图形领域像素可简单视为亮或灭,光刻则需要精确的像素 fractional覆盖度(fractional coverage),并严格保证极细微图形之间的连接性。光栅化过程中引入的微小误差,会在仿真与 OPC 迭代中不断放大,最终影响良率与可制造性。
随着工艺节点缩小至几纳米以下,光栅化所需的分辨率急剧提升,且在迭代式 OPC 流程中,同一操作必须重复执行无数次。即便高度优化的基于 CPU 的光栅化器也难以跟上,光栅化由此成为 runtime(运行时)的主要瓶颈。
传统光栅化方案的局限
大多数传统光栅化技术采用二元覆盖模型,这类方法适用于可视化场景,但在光刻场景中会失效。它们无法捕捉细微的光强变化,在处理细线或高密度图形时,常会引入连接性异常。同时,现代版图规模庞大,包含数十亿个多边形和万亿次像素计算,对内存带宽与计算资源带来巨大压力。
这正是 GPU 的优势所在。其超高并行度非常适合数据密集型任务,但 GPU 也存在挑战,包括不规则的内存访问模式与对数值精度的敏感性。要在光刻光栅化中成功使用 GPU,需要专门为精度优先、大规模并行执行设计的算法。
面向GPU的光栅化重构
面向计算光刻的 GPU 优化光栅化器,从底层思路上就截然不同。它不再按顺序处理多边形,而是将版图在空间上拆分为多个独立区域,实现并行光栅化。每个区域映射到 GPU 线程块,让数千个线程同时计算像素覆盖度。
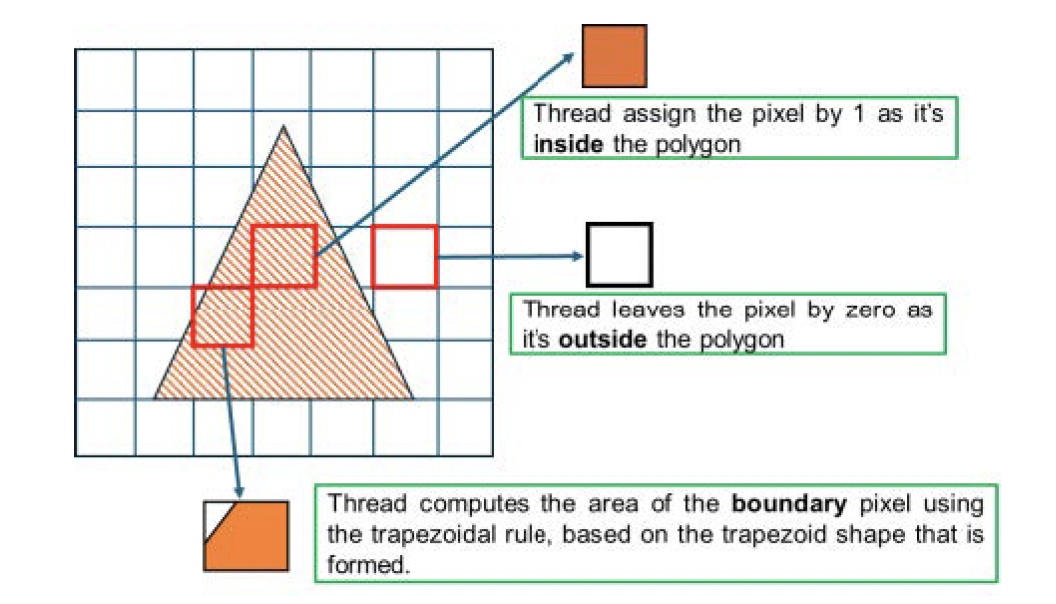
系统采用浮点运算计算像素 fractional 覆盖度,而非近似估算,确保以纳米级精度处理边界交互。设计中特别注重保留亚像素级连接性,避免细线结构在光栅化中意外断裂。曼哈顿(Manhattan)几何图形可通过简化计算路径提速,曲线图形则采用更通用、但仍对并行友好的方法处理。
GPU光栅化流水线工作原理
光栅化流水线从 CPU 侧预处理开始:版图数据被解析并分箱到空间瓦片(tile)中。这些瓦片以优化为连续访问的内存格式传输至 GPU。在 GPU 上,每个瓦片独立处理:几何数据缓存到共享内存中,线程被分配到像素或像素小组,每个线程判断其对应像素位于多边形内部、外部还是边界上。
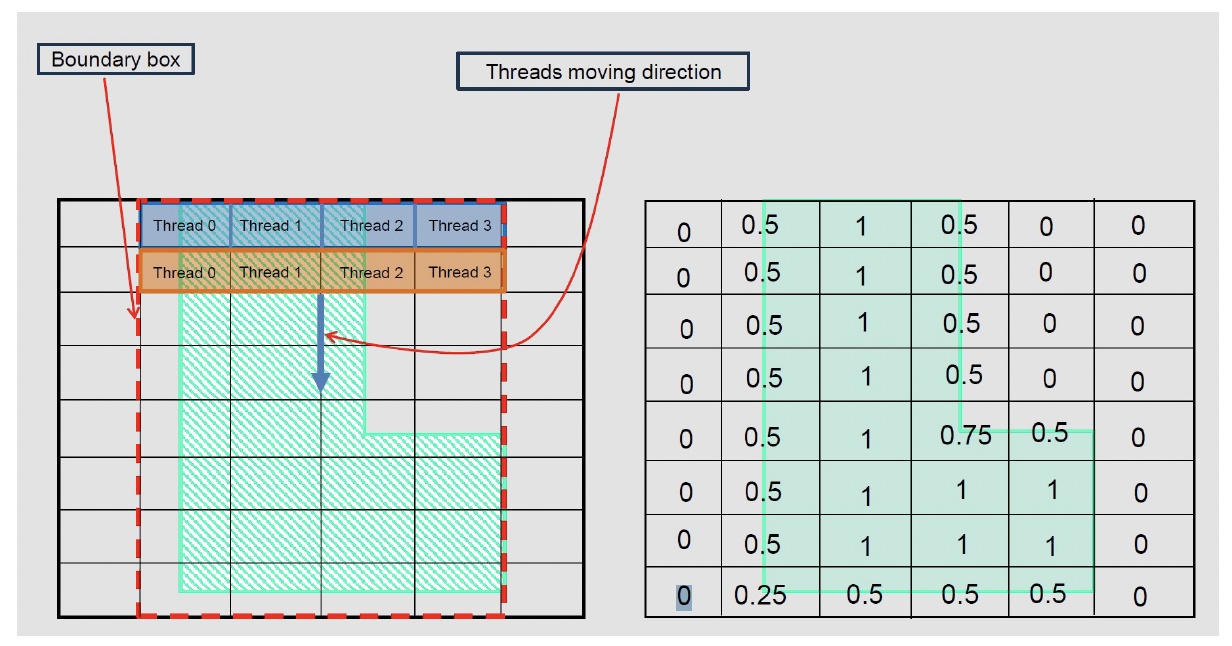
边界像素会被特殊处理。与像素相交的多边形边会被解析计算,并精确得出覆盖的 fractional 面积。原子操作保证多个多边形影响同一像素时的正确累加。该设计同时实现了高性能与确定性精度,这两个特性在大规模并行系统中很难同时兼顾。
该实现基于 CUDA 编程模型,在 NVIDIA 现代数据中心 GPU 上效果尤为突出,这类 GPU 能提供超高分辨率光栅化所需的内存带宽与并发能力。
基于 Nvidia H100 GPU 的实际性能结果。性能测试结果极具说服力。与高度优化的 CPU 光栅化器相比,GPU 方案在各类版图中均实现了大幅加速。在以曼哈顿几何为主的设计中,加速比最高可达 290 倍。即便在难度更高的曲线版图中,GPU 光栅化器也能实现最高 45 倍的加速。
关键在于,这些性能提升并未牺牲精度。在所有测试用例中,绝对误差相对于 CPU 参考计算均低于 1%。这一精度水平满足计算光刻的严苛要求,也证实了大规模并行与纳米级精度可以兼得。
对EDA与制造的重要意义
GPU 加速光栅化的意义远不止原始性能指标。更快的光栅化可缩短 OPC 与掩模合成周期,在相同设计周期内支持更多次迭代,从而带来更优的校正质量、更高的良率与更快的上市时间。高精度与连接性保证,则确保这些提升不会给制造流程带来新风险。
随着设计越来越多地采用复杂的非曼哈顿几何,且仿真保真度持续提升,基于 GPU 的光栅化的可扩展性价值将更加凸显。曾经的瓶颈,将变成光刻流水线中可扩展、面向未来的关键组件。
大规模并行 GPU 光栅化,标志着计算光刻负载处理方式的重大转变。随着 GPU 架构持续演进,提供更多核心与更高内存带宽,该方案的性能优势还将进一步扩大。未来工作将聚焦于与现有 EDA 平台的深度集成、支持 CPU–GPU 异构流程,以及扩展到更先进的光刻模型与三维效应。
本文转自媒体报道或网络平台,系作者个人立场或观点。我方转载仅为分享,不代表我方赞成或认同。若来源标注错误或侵犯了您的合法权益,请及时联系客服,我们作为中立的平台服务者将及时更正、删除或依法处理。




联系电话:
010-61853490
新闻投稿:
server@icviews.cn
商务合作:
business@icviews.cn
问题反馈:
19800315212(微信同号)


半导纵横公众号

半导纵横小程序