堆叠DRAM热阻难题:HBM4如何破局?
随着HBM向12芯片堆叠发展,主机处理器功耗接近1000瓦,工程解决方案——例如热通孔、集成微流控和单通道限流——对于系统的可行性而言变得至关重要。
为什么堆叠式DRAM存在结构热阻问题?
HBM 中的垂直芯片堆叠会产生与平面 2D 存储器截然不同的热阻问题:每一层 DRAM 都对下方的层起到部分绝缘作用,同时在读写操作过程中也会产生热量。其结果是形成渐进式的温度梯度,在堆叠底部最为严重——而底部也是整个器件中功率密度最高的位置。
根据美光科技(2025)的记录,位于堆叠底部的HBM接口芯片由于其高运行速度,在整个器件中拥有最高的功率密度,但同时也是距离传统散热介质最远的芯片。在一个12芯片的HBM3堆叠中,接口芯片必须将热量通过上方所有DRAM芯片才能到达顶部的散热器,从而产生随着堆叠高度增加而增大的芯片间热阻。
根据华为技术有限公司 2024 年关于 HBM DRAM 热管理的专利披露,在四层 HBM2 堆叠中,仅底部芯片上最热点和最冷点之间的局部温差即可达到 24°C。
采用DRAM工艺制造的HBM芯片的结温规格仅为95°C,远低于华为在2024年披露的外围CMOS逻辑芯片允许的105°C。这种热点不均匀性并非仅仅是稳态问题;在高温下,它会导致时序裕量下降和误码率增加。英特尔的测试发现,在高温下从HBM堆栈读取数据时,60%的样本芯片出现了误码。
北京超弦存储器研究所(2025)提交的文件指出,这种热阻的结构性来源是:堆叠结构中每个芯片间的间隙都由填充有底部填充聚合物的微凸点阵列连接,而这种聚合物本身具有低导热性。因此,从底部芯片到封装盖的累积串联热阻主要由这些填充聚合物的界面以及每个中间芯片的硅本体决定,而非互连线本身。传统的仅针对堆叠顶部进行散热的盖板加散热器冷却方式,在结构上与热量产生的位置不匹配。
HBM 堆叠与高功率主机处理器距离过近,进一步加剧了散热问题。据 ND-HI Technologies Lab (2024) 的数据,目前 GPU 单芯片功耗高达 700 W,CPU 单芯片功耗高达 400 W,预计未来功耗将超过 1000 W。处理器产生的横向热耦合与堆叠内部的垂直热积累相结合,使得被动式单侧散热对于日益增长的堆叠高度而言根本不够用——包括制定 HBM 规范的JEDEC在内的标准组织也强调了这一点。
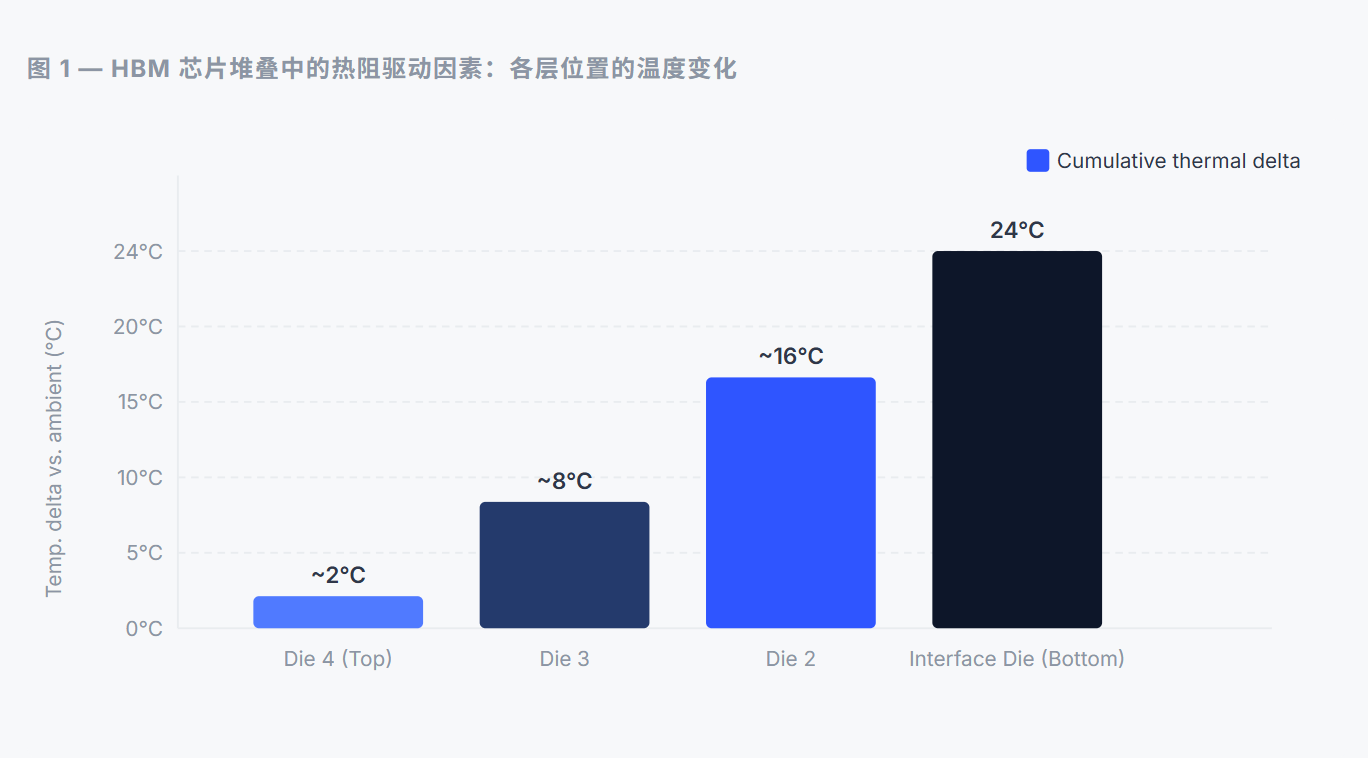
图示为四层 HBM2 堆叠结构中的温差。
热硅通孔、导电层和集成微流体冷却
解决芯片堆叠热阻的主要结构性措施是创建专用导热通道,绕过高阻底部填充材料和硅芯片路径。多家机构已达成共识,采用垂直贯穿芯片堆叠的导热结构,从功率最高的底部区域延伸至顶部芯片上方或顶部的散热表面。
美光科技对这种方法的公开披露最为详尽。在其2025年获得的美国专利中,美光描述了一种HBM器件,其中导热层位于基体芯片的特定散热区域内,冷却TSV从该层向上延伸穿过整个存储芯片堆叠,直至到达或高于顶部芯片表面。关键在于,这些散热TSV是电被动的——它们仅用作热传导通道——并且位于与信号布线区域相同的空间内,以避免增加芯片面积。
扬子存储技术有限公司 2025 年 PCT 专利描述了一种堆叠式 DRAM 架构,其中第一接触结构(“第一通道”)垂直贯穿所有堆叠芯片,每个通道的第一端与基芯片接触,第二端与沉积在最上层芯片顶面上的导热层接触,从而允许来自任何层(包括基芯片)的热量通过专用通道向上传递。
华为技术有限公司针对芯片平面内热点问题(2024年)提出了一种解决方案:在芯片底部引入导热层,以改善轴向传导前的横向散热。其关键在于,现有方法(例如高密度虚拟焊球、增加接触面积的混合键合)虽然可以降低层间热阻,但无法解决导致局部热点的平面内热阻问题。在芯片堆叠底部引入平面导热层,可以将点源热点转化为更均匀的热流,然后再引导热量流向冷却路径。
“从底部芯片到封装盖的累积串联热阻主要来自聚合物填充的芯片间界面和硅体,而不是互连线本身。传统的盖板加散热器冷却方式只能解决堆叠顶部的问题。”
最具突破性的热耦合概念源自美光公司2025年向美国和PCT提交的关于硅通孔沟槽冷却的专利申请。在堆叠芯片中,两个或多个存储芯片内部形成硅通孔沟槽,并通过流体耦合连接到冷却液供应系统,从而实现对芯片内部的直接液冷。这些基于沟槽的冷却系统通过中间芯片中的连接通道相互连接,在芯片堆叠内部形成一个完全集成的微流体冷却回路——无需依赖外部散热器进行堆叠中层的热管理。如果该方案能够量产,将代表着对传统半导体封装热架构最根本的突破,这也是IEEE等组织在其先进封装路线图工作中关注的方向。
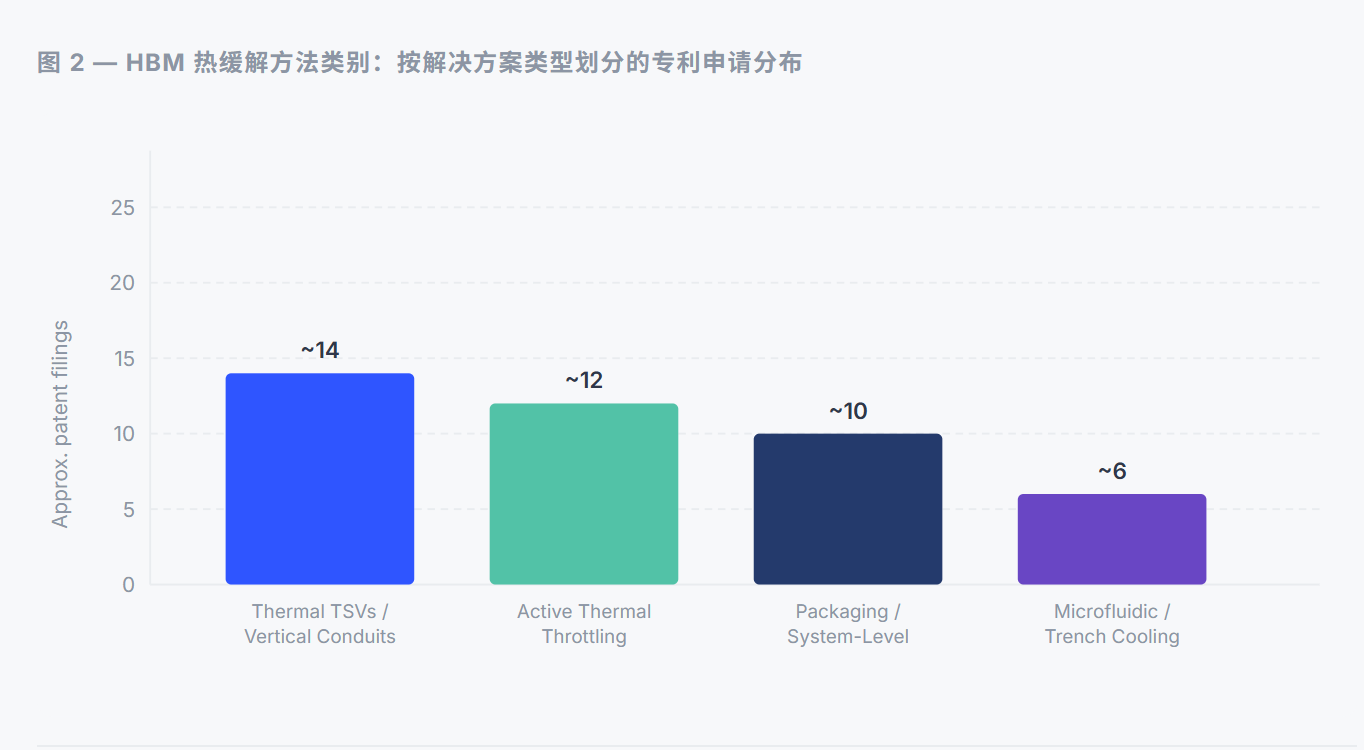
在所审查的40多项专利申请中,四大主要解决方案类别的大致分布情况如下:热式TSV和垂直导管结构占比最大,其次是主动节流方法。微流控沟槽冷却是占比最小但增长最快的类别。数值为基于所分析数据集的近似值。
HBM堆叠的封装和系统级热管理
当主机处理器功耗超过 1000 瓦时,仅靠芯片级结构创新无法解决 HBM 的热阻问题。需要协调的封装架构和主动控制机制,而传统的单面冷却拓扑结构(其中散热器仅与 DRAM 堆叠的顶部接触)现在已被多个组织认定为不足以应对深堆叠结构。
ND-HI Technologies Lab在其2025年中国台湾专利申请和2024年中国大陆专利申请中提出了一种截然不同的封装拓扑结构。该方案集成了置于芯片之间或芯片旁的高导热(HTC)互连线、带有内部液流腔的基板以及与最上层芯片直接热接触的冷却板。第二个内部腔体通过液压系统与第一个腔体相连,使液体能够从封装底部循环到顶部。这实现了双面散热:堆叠结构的底部通过基板液流腔进行冷却,而顶部则通过冷却板进行冷却——直接解决了仅顶部冷却固有的不对称性问题。
ND-HI Technologies Lab 的 2025 年专利表明,当主机处理器的单芯片功耗超过 1000 瓦时,仅冷却 HBM 堆叠的顶部是不够的;必须集成底部基板液体通道,以便直接从下部芯片带走热量,从而实现双面散热管理。
上海先方半导体针对传统盖板加散热器冷却方式的局限性,开发了一种新型水冷系统。该系统在盖板上方布置了三维蜂窝状微通道,并结合贯穿水冷系统和盖板的热管,直接将热量传递至芯片表面。这种设计构建了三维热流网络,而非传统方案的纯平面热传导,从而显著提升了高密度三维集成结构的冷却能力。
英特尔公司在其2023年提交给中国市场的文件中解决了倒置堆叠散热问题。文件指出,在传统的HBM封装中,产生大部分功率的基础芯片距离导热界面材料(TIM)和散热器最远。英特尔的倒置堆叠概念将功率最高的逻辑芯片放置在最靠近外部散热表面的位置,从而缩短了主要热源的散热路径。在传统的封装中,逻辑芯片的高功率密度外围区域超出DRAM堆叠的面积,主要散热路径必须穿过整个DRAM堆叠才能到达顶盖,导致最高温度(Tmax)升高30°C;而英特尔的阶梯式顶盖设计通过第一导热界面直接与逻辑芯片外围区域接触,从而完全绕过DRAM堆叠,将逻辑芯片的大部分热量散发出去。
英特尔还公开了封装级主动散热管理技术(2021 年),该技术采用智能交叉开关,可根据芯片温度信息路由内存访问命令。通过将流量从过热的芯片转移开,这种方法可以防止热能积累,否则就需要进行硬性降频——这种软硬件协同设计方法已被JEDEC等组织认定为对 AI 加速器内存子系统日益重要。
主动式热节流:芯片级和通道级粒度
主动式热控制方法能够实时管理结构解决方案无法完全消除的温度梯度。业界已从整体式的全堆限流转向精细化的逐通道和逐单元组控制——这一转变源于人们认识到粗放式限流会不必要地浪费性能。
台积电在中国台湾和韩国提交的多司法管辖区专利族(2023-2024年)提出了一种差异化动态电压和频率调节(DDVFS)技术,该技术引入了一种架构,其中HBM中的每个存储单元组都拥有自己的传感单元,用于生成与局部晶体管状态相对应的环境信号。DDVFS器件能够根据每个存储单元组自身的环境信号独立调节晶体管温度影响(TTA)参数,而不是对所有单元进行统一的降频。这避免了芯片中一小部分过热而整个堆叠却被降频的情况——这种情况既浪费资源又会限制性能。
台积电2022年提交给中国的文件明确指出了单芯片动态电压频率调节(DVFS)的缺陷:由于通常只有少数核心芯片的温度超过允许阈值,因此单芯片级别的降频会不必要地降低大多数单元以及堆叠中所有其他芯片的性能。而逐组动态电压频率调节(DDVFS)方法则可以精准地降低受影响区域的性能。
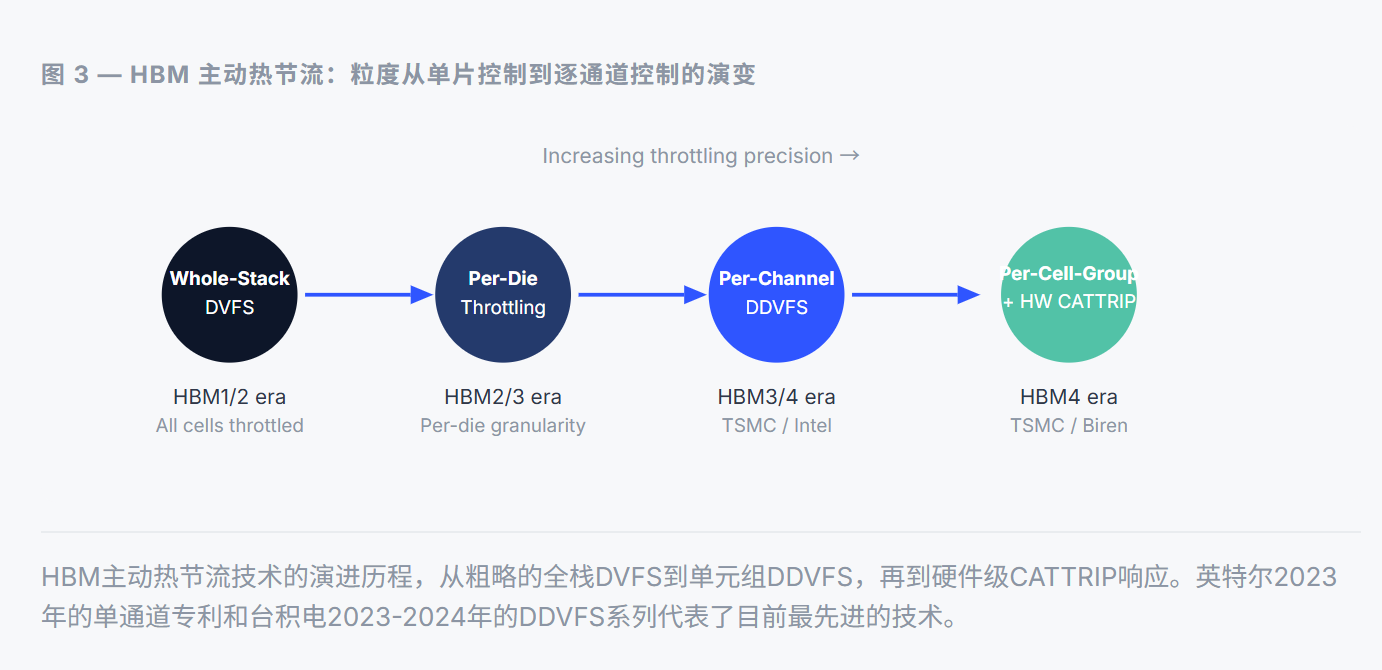
英特尔2023年在中国申请的单通道散热管理专利进一步细化了控制粒度,使其达到通道级别。该专利使内存控制器能够根据单通道温度遥测数据,独立地对各个通道内的行命令和列命令进行降频。行命令降频和列命令降频可以以不同的速率进行,并且降频信号可以在通道和伪通道之间交错发送,从而在降低热峰值的同时保持总带宽。这对于HBM4一代接口尤为重要,因为每个堆叠都暴露了16个或更多伪通道。
清华大学提出了一种互补的方法:根据每个分区的热特性,将数据工作负载映射到物理分区,然后根据每个分区的运行温度优化DRAM刷新频率。温度较高的区域需要更频繁的刷新来抵消增加的漏电;通过显式地检测这些区域,可以消除对温度较低区域的不必要刷新操作,从而降低刷新功耗以及这些刷新周期产生的二次发热。随着人工智能训练和推理工作负载产生高度不均匀的内存访问模式,这种工作负载感知方法的重要性日益凸显——世界知识产权组织(WIPO)在其关于半导体创新的年度技术趋势报告中也记录了这一挑战。
本文转自媒体报道或网络平台,系作者个人立场或观点。我方转载仅为分享,不代表我方赞成或认同。若来源标注错误或侵犯了您的合法权益,请及时联系客服,我们作为中立的平台服务者将及时更正、删除或依法处理。




联系电话:
010-61853490
新闻投稿:
server@icviews.cn
商务合作:
business@icviews.cn
问题反馈:
19800315212(微信同号)


半导纵横公众号

半导纵横小程序