随手一测:芯片组微基准表现
随着时间推移,主板芯片组承担的性能关键功能越来越少。在Athlon 64 时代,集成内存控制器将芯片组移出了 DRAM 访问路径。2010 年代初,英特尔酷睿 Sandy Bridge 等 CPU 将 PCIe 通道集成到 CPU 内部,让 GPU 可以不经过芯片组直接与 CPU 通信。如今的芯片组仍然提供大量重要的 I/O 能力,但在性能考量中已沦为次要角色。对芯片组做基准测试本身没什么实用价值,但一个话题不必有用才值得研究。而我确实觉得,测试芯片组延迟会很有趣。

芯片组测试
本文使用了 Nemes 基于 Vulkan 的 GPU 基准测试套件,但做了一些修改,允许使用VK_MEMORY_PROPERTY_HOST_COHERENT_BIT和VK_MEMORY_PROPERTY_DEVICE_LOCAL_BIT来分配内存。这样就能得到一块从主机内存中分配的缓冲区。然后,可以对主机内存运行 Vulkan 延迟测试,得到通过 PCIe 的 GPU 内存访问延迟。这里使用哪款 GPU 并不重要,因为我关心的是CPU 直连 PCIe 插槽与南桥 PCIe 插槽之间的延迟差异。这里选用英伟达 T1000,因为它是单槽卡,能插进多套测试平台的底部 PCIe 插槽。下面所有平台均运行 Windows 10,只有 FX-8350 平台运行 Windows Server 2016。这些操作系统使用了最新可用驱动:Windows 10 为 553.50,Windows Server 2016 为 475.14。
同时尝试了反向测试:让 CPU 访问 GPU 设备内存。Nemes 在 Vulkan 上行延迟测试中就是这么做的。然而,在不同测试尺寸范围内测试时,我遇到了无法解释的拐点。Windows 性能指标显示,在较大测试尺寸下出现大量页面错误,这或许暗示有驱动介入。深入研究这个问题会是个无底洞,我不想陷进去;而且我在 T1000 上观察到的 CPU 访问显存行为,在不同 GPU 上并不通用。因此我将专注于 GPU 访问主机内存的延迟,不过会在文末给 CPU 侧结果加一个注释。
缓存带宽与探测(Probe)
设置VK_MEMORY_PROPERTY_HOST_COHERENT_BIT意味着 CPU 与 GPU 之间的写操作可以互相可见,无需显式执行缓存刷新与无效化指令。在 T1000 上,这会产生一个奇怪的副作用:即使 GPU 命中自身缓存,也会引发大量探测流量。GPU 缓存命中带宽可能受平台配置限制,或许取决于探测吞吐量。AMD 老款Piledriver CPU 拥有可追踪探测结果的northbridge性能事件。这些事件显示,当测试数据尺寸小到能放进 T1000 缓存时,会出现大量探测。当测试尺寸变大、带宽受 PCIe 链路限制时,探测活动会下降。
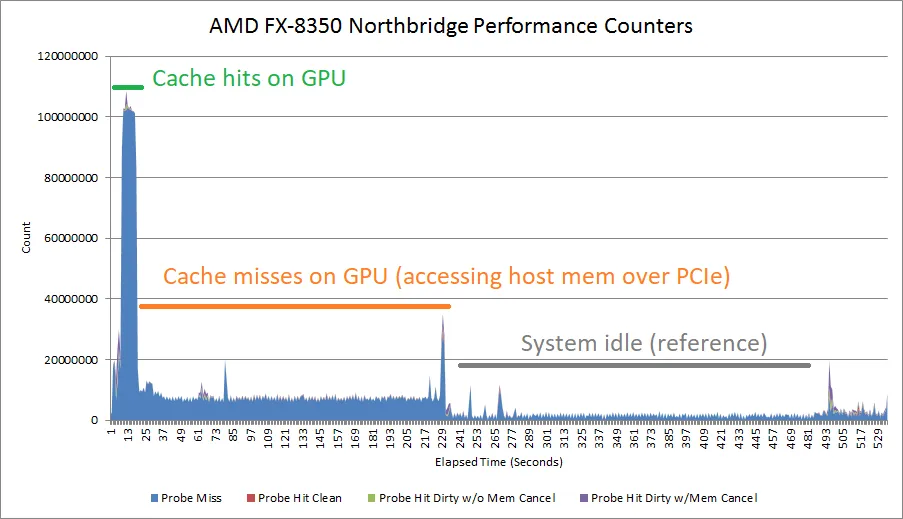
这里所说的northbridge,指的是集成在 CPU 内的northbridge,而非芯片组的northbridge。
探测以缓存行粒度工作,AMD 15h BKDG 文档已明确这一点。但探测速率表明,T1000 每 512 字节缓存命中就发起一次探测,而不是每 64 字节。另外,为什么缓存命中延迟看起来不受影响。

抛开这些不谈,当 GPU 缓存命中带宽似乎受平台影响时,我会做出标注。但我不会评论 GPU 缓存未命中带宽,这显然会受 PCIe 带宽限制。T1000 与主机之间是 PCIe 3.0 x16 接口,我测试的最新平台可支持 PCIe 4.0 或 5.0。我没有支持 PCIe 4.0/5.0 的单槽显卡。
AMD AM5 平台
AMD 最新桌面平台围绕 PROM21 芯片构建。PROM21 拥有 PCIe 4.0 x4 上行链路,并向外提供多种下游 I/O,包括更多 PCIe 4.0 通道。AMD X670E 芯片组将两颗 PROM21 级联,本质上给平台配备双南桥以获得更好扩展性。技嘉 X670E Aorus Master 有三个 PCIe 插槽:一个直连 CPU,另外两个连到下级 PROM21。与 CPU 直连的那颗 PROM21 不接任何 PCIe 插槽,只用于提供 M.2 插槽和部分 USB 接口。本次在华擎 B650 PG Lightning 上测试的 B650 芯片组只使用一颗 PROM21,并将其与 PCIe 插槽相连。
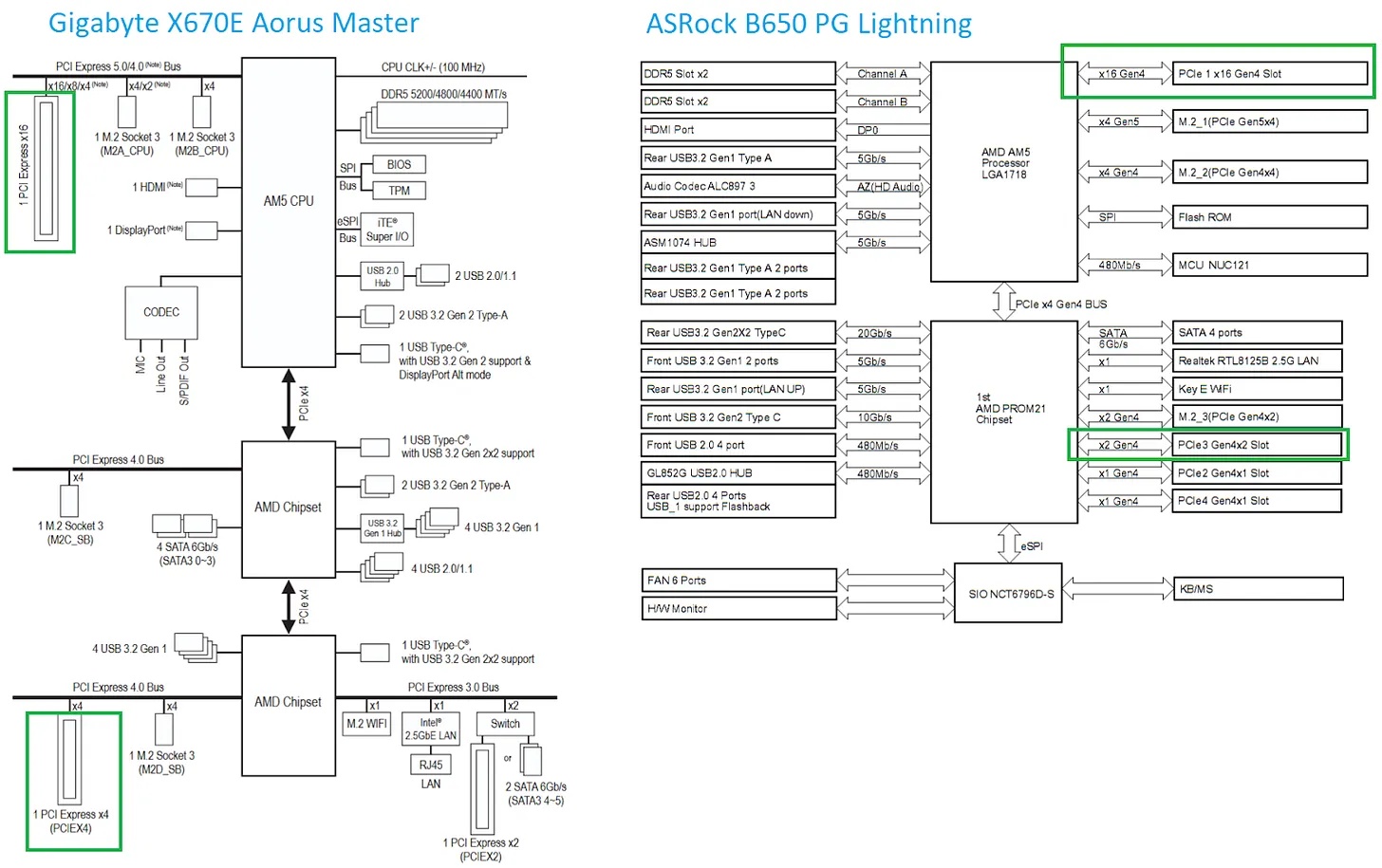
两款被测 AM5 主板的框图(来自各自手册),绿色框标注被测 PCIe 插槽
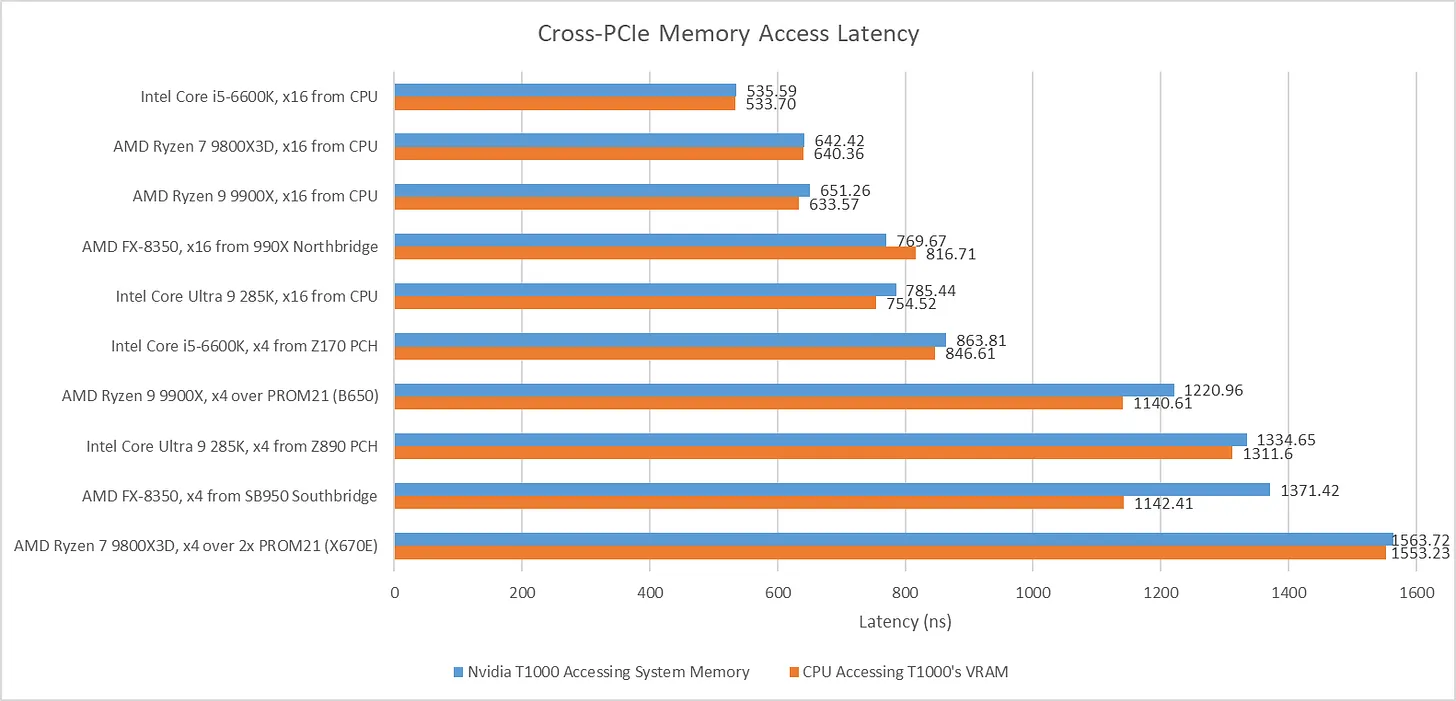
使用 CPU 直连 PCIe 通道时,基线延迟约为650 ns。经过 B650 芯片组的一颗 PROM21 后,延迟升至1221 ns,比基线高出 569.7 ns。在 X670E 上,经过两颗 PROM21 芯片后,延迟比基线高出921.3 ns。因此,走芯片组会带来显著延迟代价,多经过一颗 PROM21 会进一步增加延迟。
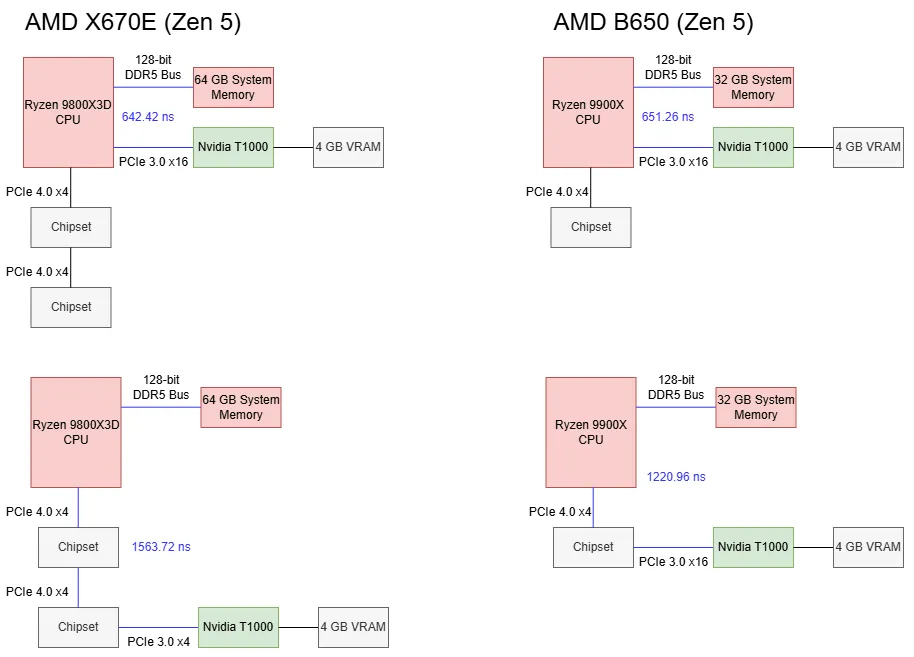
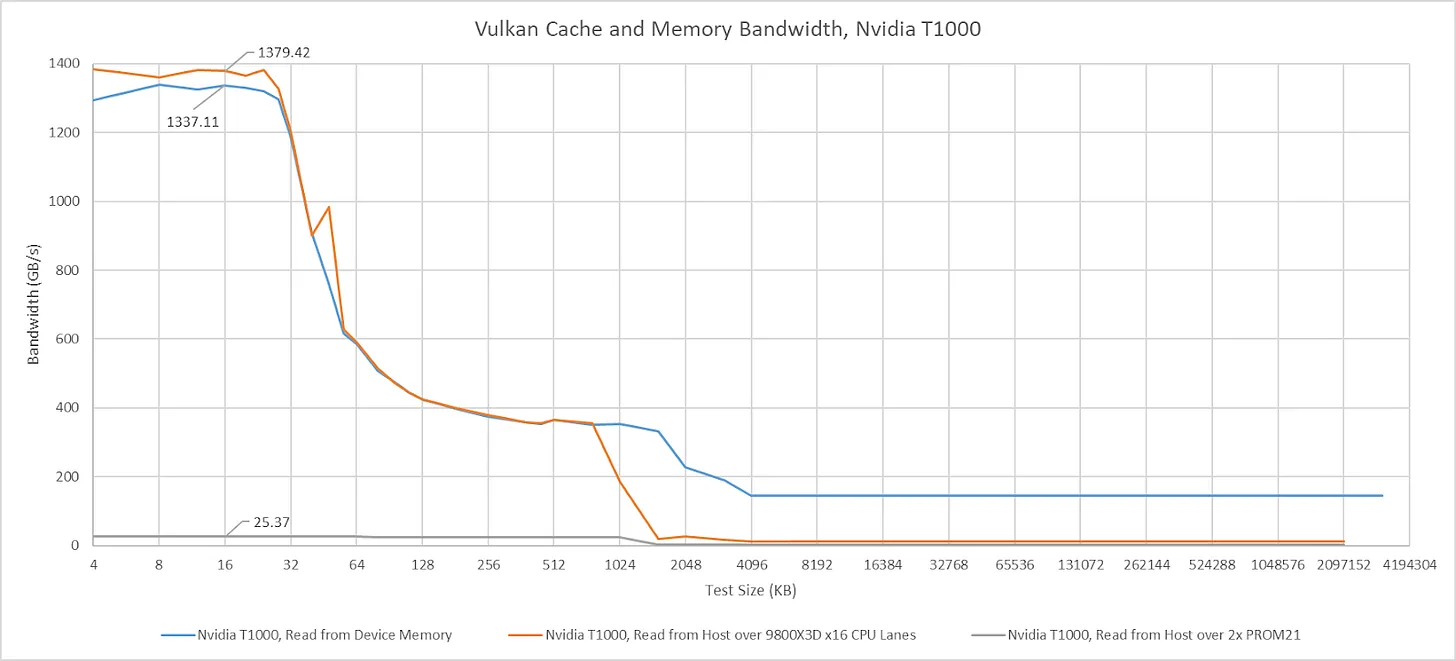
将 T1000 接到 Zen5 的 CPU 直连通道上时,我没有观察到 GPU 缓存命中带宽的差异。将 GPU 切到芯片组通道后,缓存命中带宽降至略高于 25 GB/s;无论 CPU 与 GPU 之间是一颗还是两颗 PROM21,该数值基本保持一致。
英特尔 Arrow Lake 平台
Arrow Lake 芯片组沿用了自 Sandy Bridge 以来英特尔一贯的拓扑结构:平台控制器中枢(PCH)承担南桥角色。PCH 通过直接媒体接口(DMI)与 CPU 相连,这是一种类 PCIe 接口。Z890 使用 DMI Gen 4,8 通道,最高传输速率 16 GT/s。我在微星 PRO Z890-A WIFI 上测试,该板提供三个 PCIe 插槽:第一个是直连 CPU 的 x16 插槽,另外两个是连到 PCH 的 x4 插槽。
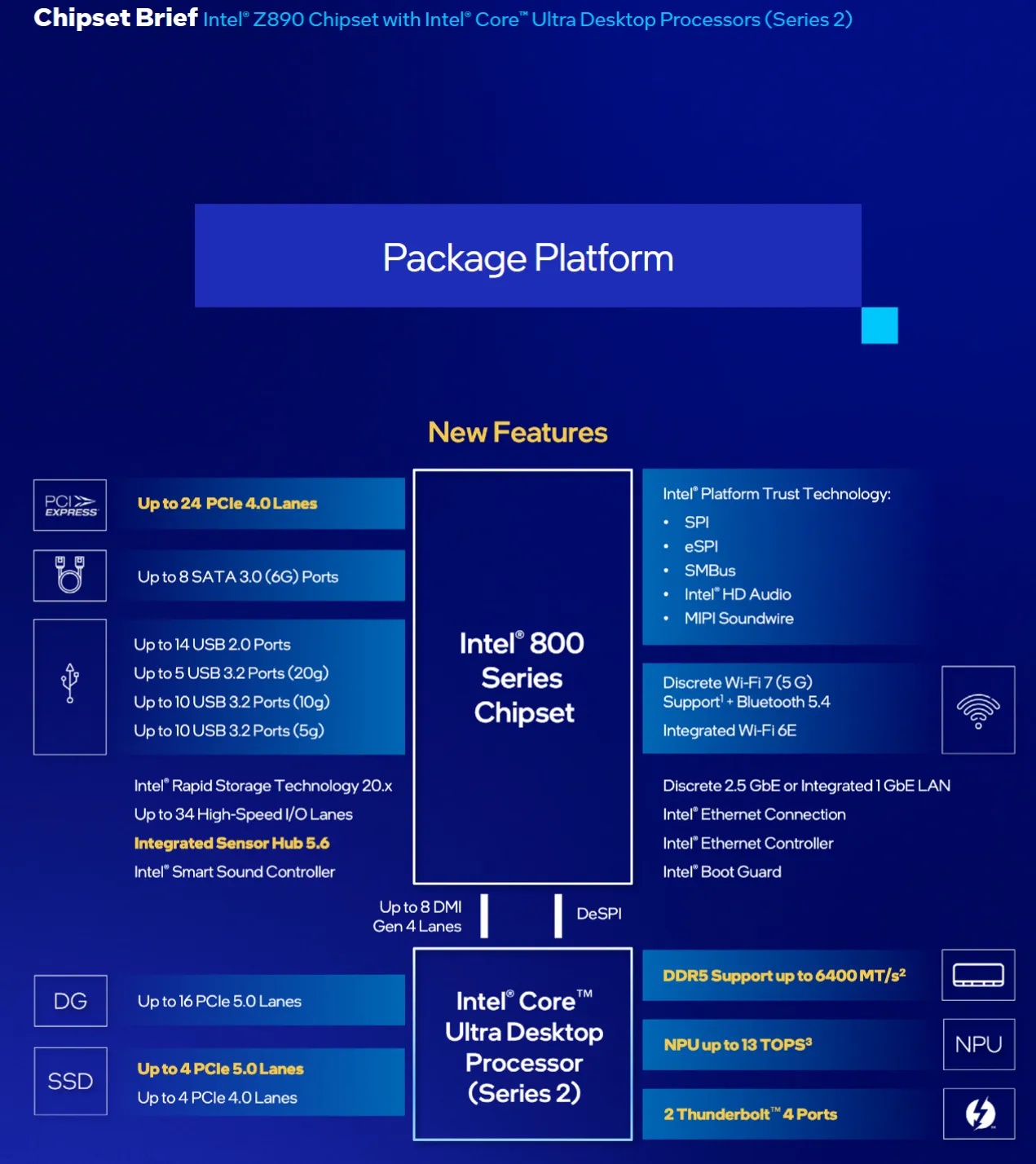
来自英特尔芯片组简介文档的 Arrow Lake 芯片组框图
Arrow Lake 的基线延迟高于 Zen5:GPU 从主机内存加载到使用的延迟为785 ns。经过 PCH 会增加约550 ns延迟,与 AM5 平台一颗 PROM21 带来的增量相当。
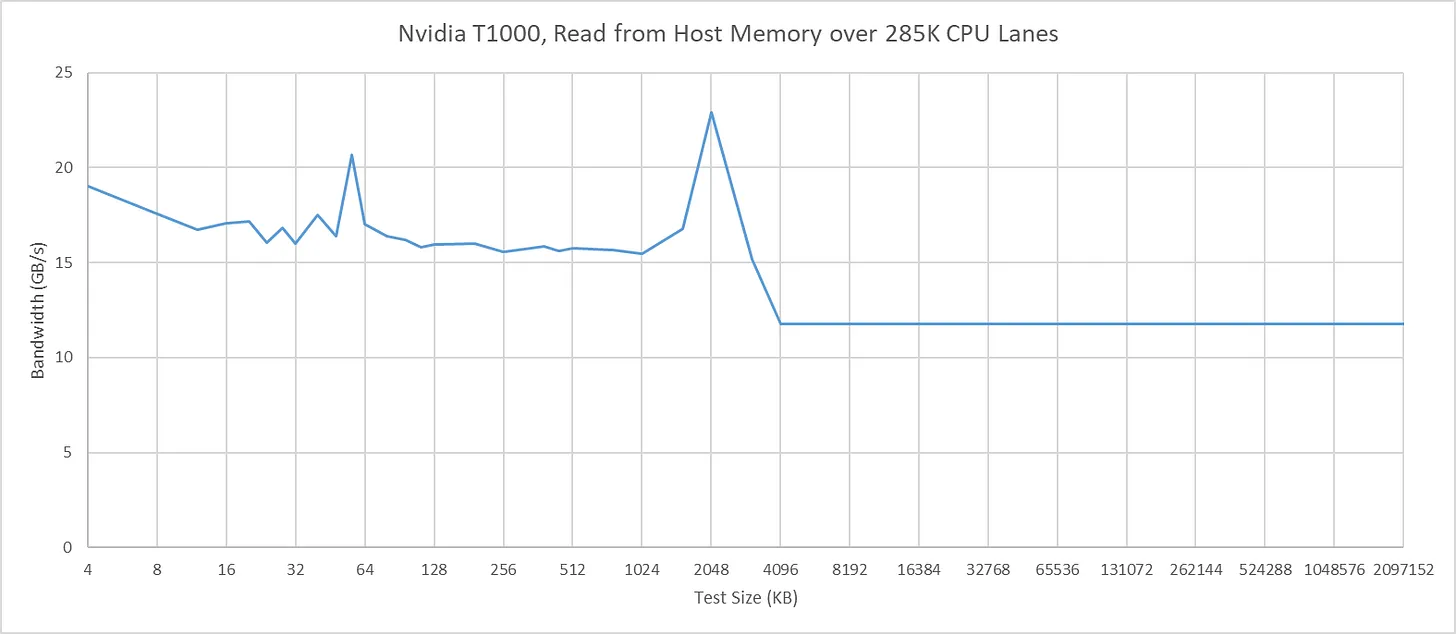
我将跳过对 Arrow Lake 上 T1000 缓存命中带宽的评论。即使接到 CPU 直连 PCIe 通道,它的表现也不符合预期。T1000 的缓存命中行为也与其他 GPU 不同。例如,英特尔 Arc B580 接到 Arrow Lake 平台时能保持满缓存命中带宽,不过奇怪的是它无法在 L2 中缓存主机内存。
英特尔 Skylake 平台
Skylake 的 Z170 芯片组采用与 Z890 类似的纯南桥拓扑,但扩展性更低、带宽更小。我在微星 Z170 Gaming Pro Carbon 上测试:顶部 PCIe x16 插槽直连 CPU;中间插槽也直连 CPU,可将 CPU 的 16 条 PCIe 通道拆分为两组 8 条;底部插槽连到 PCH。
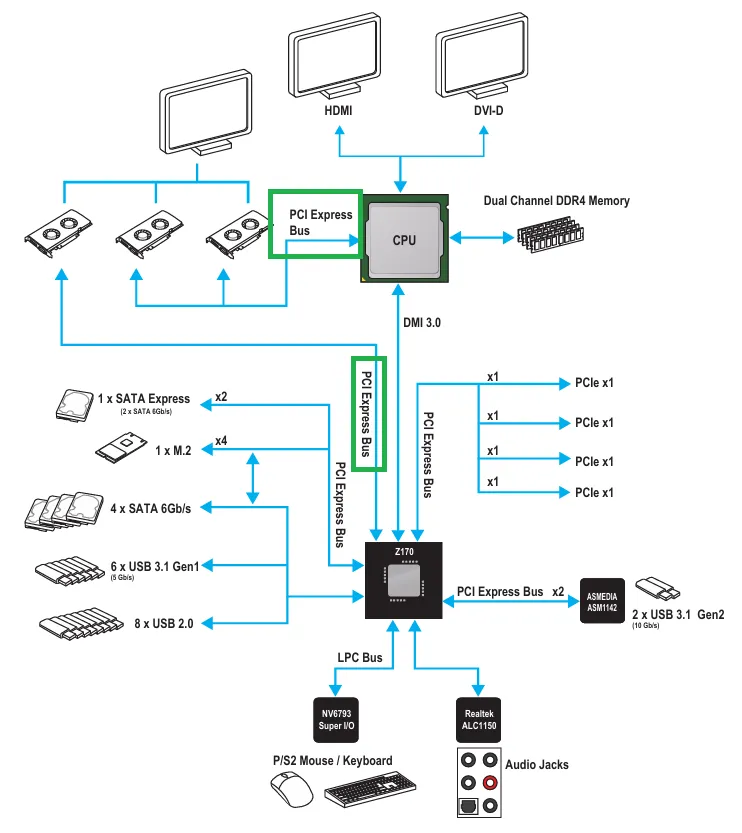
MSI Z170 Gaming Pro Carbon 手册中的 Z170 芯片组框图,绿色框标注被测 PCIe 插槽
Skylake 的 CPU 直连 PCIe 通道提供出色的基线延迟:535.59 ns。经过 Z170 PCH 则增加338 ns延迟。与常规 DRAM 访问延迟相比这一增量很高,但与当代桌面平台相比表现不错。
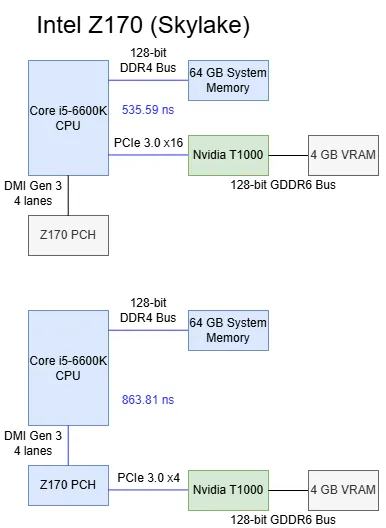
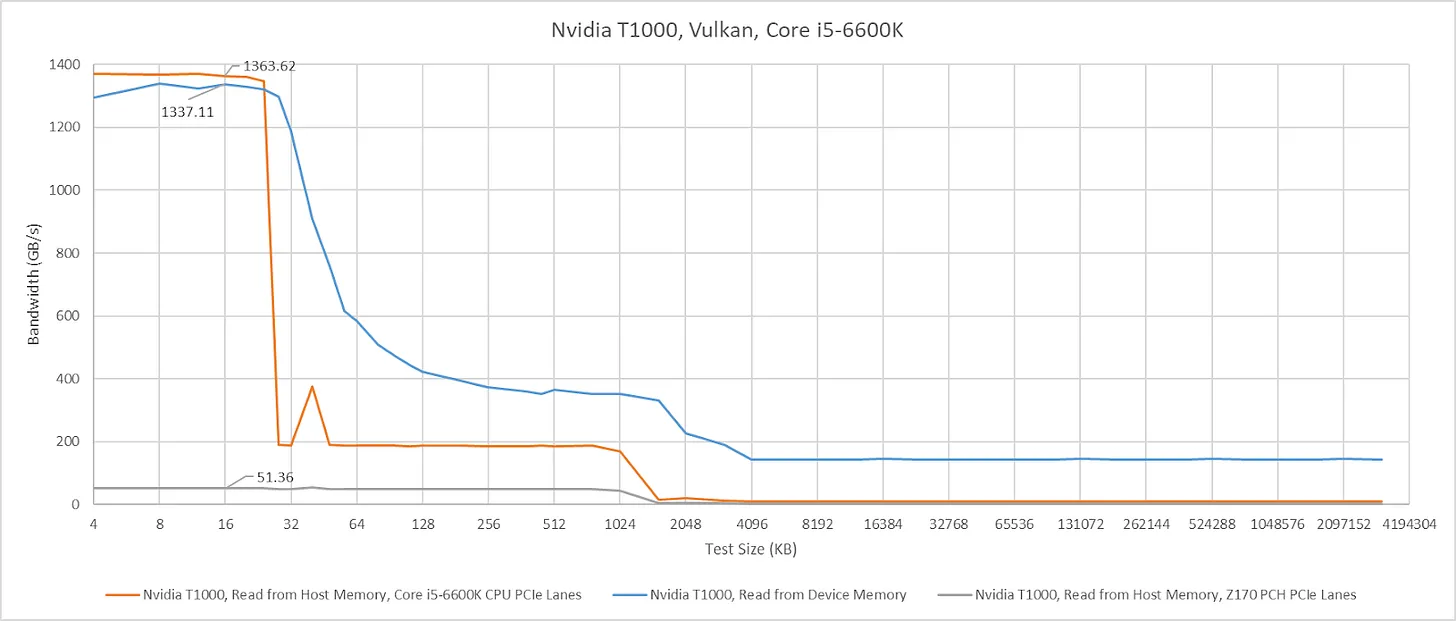
将 GPU 接到 CPU 直连 PCIe 通道时,T1000 的 L1 带宽不受影响,但 L2 命中带宽奇怪地偏低(不过仍远高于显存带宽)。将显卡切到 Z170 的 PCH 通道后,缓存命中带宽降至略高于 51 GB/s。
AMD AM3 + 平台
AMD Bulldozer 和 Piledriver架构芯片组采用较老的设计:CPU 集成内存控制器,但芯片组仍负责所有 PCIe 连接。我在华硕 M5A99X EVO R2.0 上测试,该板搭载 990X 芯片组。RD980(990X)northbridge通过 5.3 GT/s 的 HyperTransport 链路与 CPU 相连,我假定其运行在 16 位 “合并” 模式。M5A99X 上有两个 PCIe 插槽连到 RD980,可工作在单 x16 或双 x8 模式。x4 A-Link Express III 接口将northbridge与 SB950 南桥相连,南桥提供更多 PCIe 通道与低速 I/O。A-Link Express 基于 PCIe Gen 2,速率 5 GT/s。
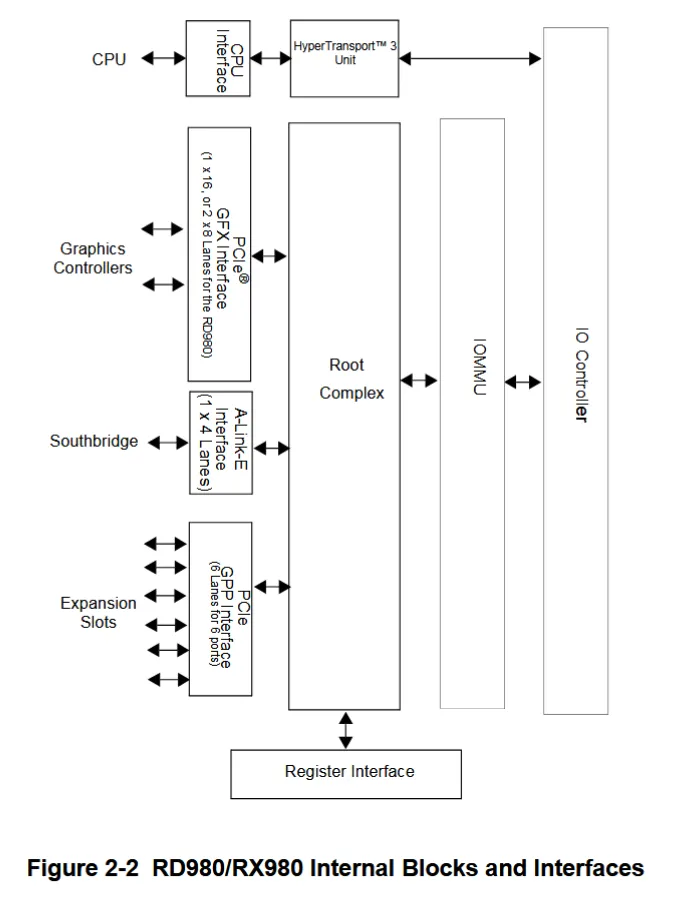
AMD数据手册中990X(RD980)北桥示意图
使用 990X northbridge的 PCIe 通道时,基线延迟为769.67 ns,表现非常不错,介于 AMD Zen5 和英特尔 Arrow Lake 之间。考虑到 AM3 + 平台最快的 PCIe 通道并非像现代平台那样直接来自 CPU,这一延迟成绩相当优秀。
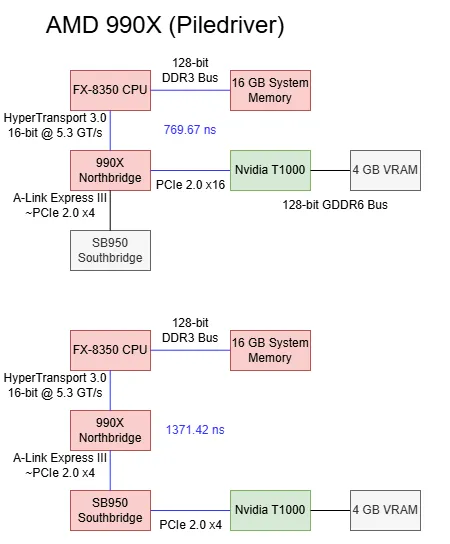
经过 SB950 南桥后,延迟增加 602 ns。这一增量高于 Arrow Lake 的 PCH 或 B650 的单颗 PROM21。不过,南桥延迟仍优于经过 X670E 两颗 PROM21 的情况。
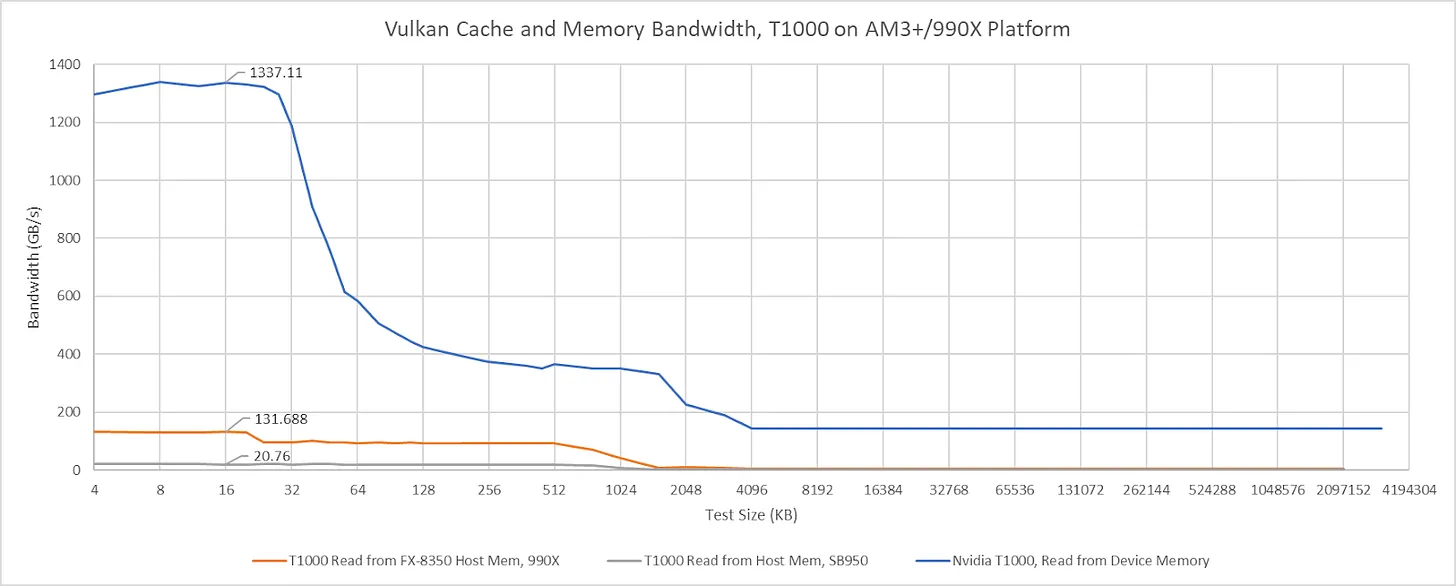
在 990X 平台上,T1000 接到northbridge PCIe 通道时,缓存命中带宽上限约为132 GB/s。接到南桥 PCIe 通道后,缓存命中带宽降至略高于 20 GB/s。两个数值都远超平台 I/O 带宽。990X 的 HyperTransport 通道单向只能提供 10.5 GB/s,而即使 T1000 接到南桥,缓存命中带宽也远高于此。如果 T1000 的缓存命中带宽受探测吞吐量限制,那么 990X 芯片组的探测吞吐量是使其 I/O 带宽饱和所需量的 10 倍以上。当然,这仍远不足以支撑 GPU 缓存命中带宽。
补充:CPU 侧延迟
如前所述,让 CPU 访问 GPU 显存是另一种测量 PCIe 延迟的方法。在 T1000 上分配的主机可见设备内存,从 CPU 侧是不可缓存的,这很可能是为了保证一致性。如果缓存不参与,那么小尺寸测试最能准确反映基线延迟,因为不会遇到地址转换开销或页面错误。这里我把 4 KB 测试尺寸下的 CPU→显存结果,与上面的 GPU→系统内存结果放在一起对比。两种测量方法存在一些差异,但不足以得出截然不同的结论。
结语
如今的芯片组不再承担性能关键角色,相应地也没有针对低延迟做优化。走芯片组 PCIe 通道会增加数百纳秒延迟,并带来带宽限制。芯片组还会影响缓存命中带宽,原因可能是探测吞吐量受限。

像 AMD 990X 这样的老芯片组表明,即使使用外置northbridge,也可以实现尚可的 PCIe 延迟。但我认为未来芯片组不会再做延迟优化。随着多 GPU 方案衰落,如今芯片组主要服务于 SSD、网卡等高延迟 I/O 设备。这些设备的延迟动辄微秒级甚至毫秒级,几百纳秒无关紧要。探测性能也是同理:对 GPU 而言,访问主机一致性内存只是小众场景,GPU 主要期望使用高速片上内存。不用说,基于显存的缓冲区发生缓存命中时,不需要向 CPU 发送探测。
预计未来芯片组设计会朝着降低成本、增强扩展性方向优化,同时跟上新一代 SSD 对更高带宽的需求。也许不会出现延迟或探测路径层面的优化,不过持续观察其行为是否会改变也会很有意思。
本文转自媒体报道或网络平台,系作者个人立场或观点。我方转载仅为分享,不代表我方赞成或认同。若来源标注错误或侵犯了您的合法权益,请及时联系客服,我们作为中立的平台服务者将及时更正、删除或依法处理。



联系电话:
010-61853490
新闻投稿:
server@icviews.cn
商务合作:
business@icviews.cn
问题反馈:
19800315212(微信同号)


半导纵横公众号

半导纵横小程序