NVIDIA Blackwell实测:性能提升2倍,速度提升3倍
人工智能创新的持续推进,由三大扩展定律驱动:预训练扩展、训练后扩展以及推理阶段扩展。训练是构建更智能模型的基础,而训练后阶段涵盖微调、强化学习及其他技术,不仅有助于进一步提升模型在特定任务中的准确率,还能赋予模型推理等全新能力。
随着基础模型的规模不断扩大、复杂度持续提升,其训练过程所需的算力性能也相应增加。这意味着,若要达到固定的性能水准,模型训练将耗费更长时间与更高成本。此外,人工智能研究人员为实现下一代模型架构的突破性进展,仍需开展大量实验探索,在最终完成预训练任务之前,还将消耗更多训练算力。因此,行业亟需技术创新,大幅提升算力供给水平,以支撑更复杂模型的训练,同时降低单位算力成本。
而这正是英伟达极致协同设计技术的用武之地。英伟达通过在GPU、CPU、NVLink Switches、NIC、DPU、Quantum InfiniBand、Spectrum-X、系统架构及海量软件层面的全方位创新,实现了训练性能的大幅跃升,且提升幅度远超摩尔定律的极限。这种性能提升不仅意味着更短的训练周期,帮助模型开发者更快部署模型并创造收益,还能降低模型训练成本,提升投资回报率。这也正是当前全球领先的人工智能模型均基于英伟达技术完成训练的原因。
在本文中,我们将深入探讨新一代芯片,以及基于同架构持续迭代的软件栈,如何大幅缩短模型训练周期、显著降低训练成本。
英伟达GB200 NVL72性能较Hopper架构实现跨越式提升
在上一轮机器学习性能基准测试中,英伟达率先采用FP4提交测试结果,且是该基准测试套件中所有大语言模型(LLM)唯一采用这一精度的厂商。这些突破得益于英伟达Blackwell架构在硬件层面实现的NVFP4精度加速、全新训练方案,以及软件栈的全面优化。测试结果显示,在使用同等数量GPU的情况下,针对 Llama 3.1 405B 模型的训练,GB200 NVL72 的性能较采用FP8的英伟达Hopper架构优化方案,最高提升3.2 倍。
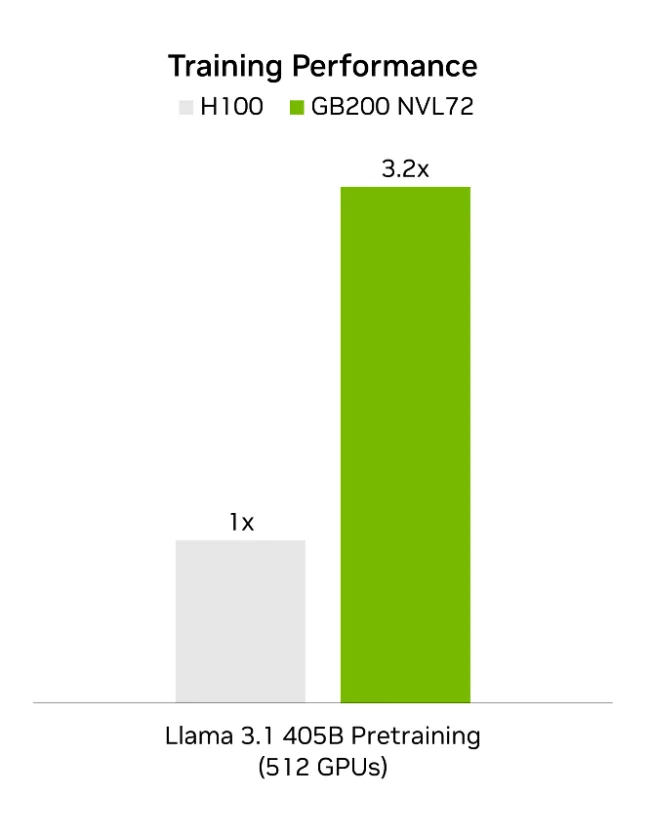
训练周期的缩短,能够帮助模型开发者更快将产品推向市场,加速实现技术变现。同时,性能的提升幅度远超每小时实例租赁价格的涨幅,最终转化为单位成本性能的显著优化。
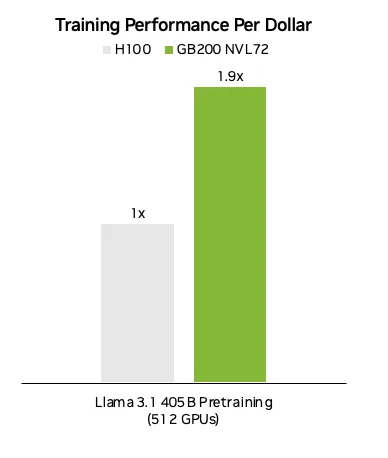
基于英伟达 H100 与 GB200 NVL72 在 Llama 3.1 405B 模型上的最新 MLPerf Training 提交数据,并结合公开的图形处理器租赁价格计算得出:GB200 NVL72 的单位成本性能较 H100 提升近2 倍。
基于同代Blackwell架构GPU,NVFP4训练更具性价比
除了按照年度技术路线图,通过新一代架构与平台实现性能跃升外,英伟达工程师还在持续探索算法与软件创新,致力于在现有架构基础上挖掘更大性能潜力。
Blackwell架构在硬件层面原生支持FP4加速,不仅兼容行业通用 FP4 格式,还搭载了英伟达自研的NVFP4格式,相较其他 FP4 格式,该格式能有效提升性能表现。在最新一轮 MLPerf Training v5.1 测试中,基于同规格 GB200 NVL72 机柜级架构,采用 NVFP4 训练方案的性能较上一轮采用 FP8 方案的性能,最高提升1.4 倍。
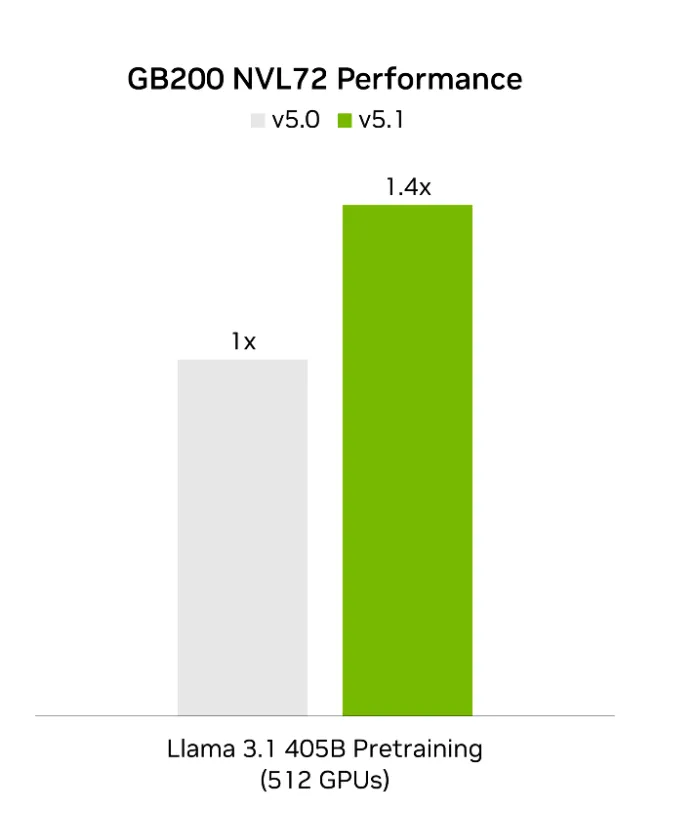
这种性能提升不仅大幅缩短了训练周期,更重要的是,该提升基于现有GPU架构实现,因此能够直接转化为更高的单位成本性能。
Blackwell Ultra 架构实现性能再突破
搭载升级款英伟达Blackwell Ultra GPU的英伟达 GB300 NVL72,凭借其大幅提升的 FP4 算力与更大容量的HBM,在 MLPerf Training 测试中展现出更卓越的训练速度。在 512 块GPU的测试规模下,GB300 NVL72 完成 Llama 3.1 405B 模型训练的速度,较上一轮同规模测试中的 GB200 NVL72 提升1.9 倍,相较Hopper架构的累计性能提升幅度高达4.2 倍。
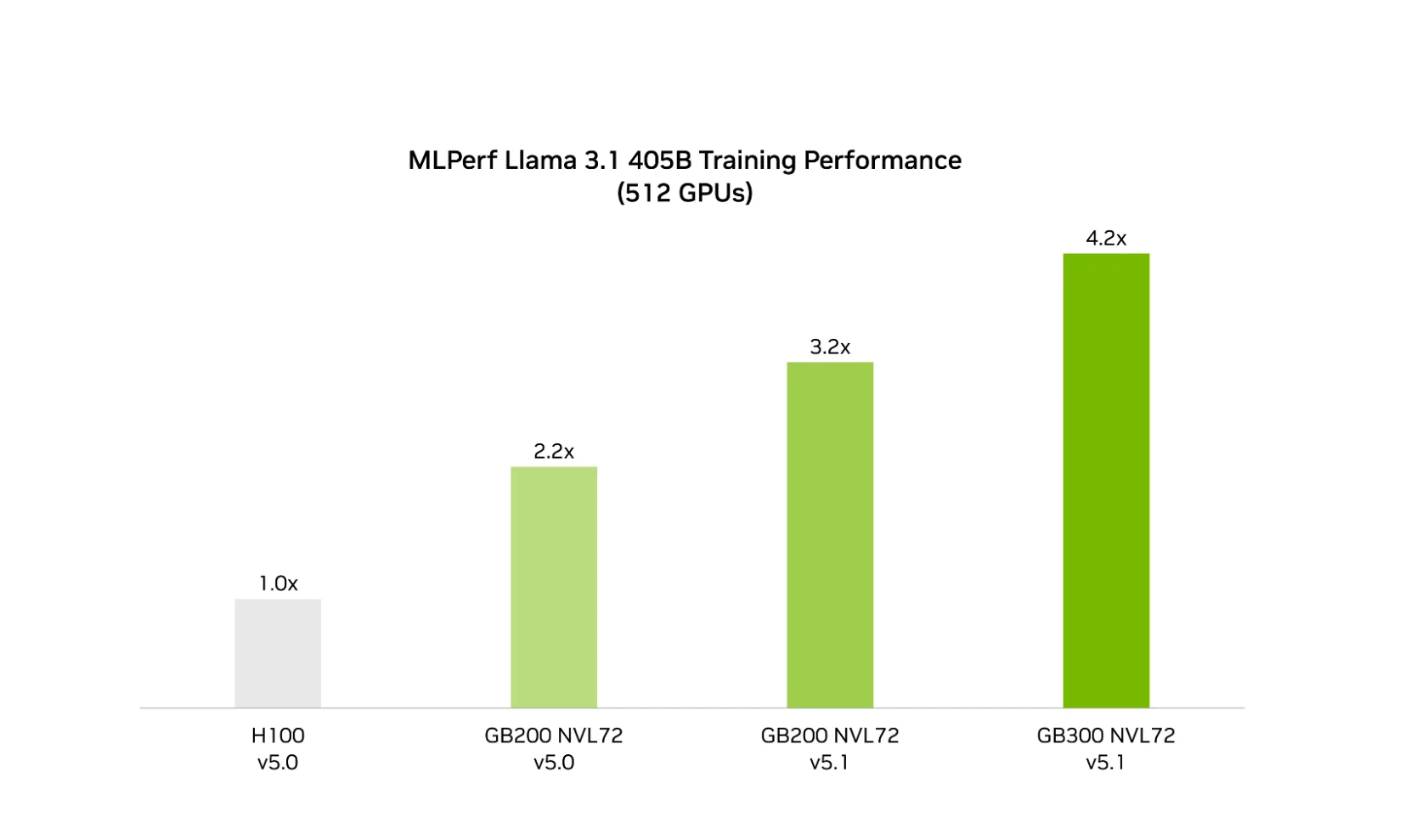
随着 NVFP4 数据格式的应用范围持续扩大,与上一代 GB200 NVL72 相比,GB300 NVL72 在 MLPerf Training 与 MLPerf Inference 两大基准测试中均实现了性能的大幅提升。这意味着,借助 GB300 NVL72,模型开发者不仅能更快完成下一代模型的训练与上市,还能以更高的吞吐量实现模型推理服务,进一步提升推理业务的收益潜力。
英伟达极致协同设计技术实现性能跃升
通过在在GPU、CPU、scale-up fabric、scale-out and scale-across networking、系统架构及软件领域的不懈创新,英伟达极致协同设计技术实现了性能的年度量级跃升。这些性能突破,不仅将为更大规模、更智能的下一代人工智能模型训练提供支撑,还能推动模型推理服务实现高速、低成本运行,为更广阔的人工智能生态创造更多价值。
本文转自媒体报道或网络平台,系作者个人立场或观点。我方转载仅为分享,不代表我方赞成或认同。若来源标注错误或侵犯了您的合法权益,请及时联系客服,我们作为中立的平台服务者将及时更正、删除或依法处理。




联系电话:
010-61853490
新闻投稿:
server@icviews.cn
商务合作:
business@icviews.cn
问题反馈:
19800315212(微信同号)


半导纵横公众号

半导纵横小程序