RDNA4的“乱序”内存访问
AMD 的 RDNA 4 带来了多种内存子系统的改进。其中一张幻灯片尤为引人注目,因为它涉及乱序内存访问。根据幻灯片内容,RDNA 4 允许来自不同着色器的请求以乱序方式完成,并为内存请求新增了乱序队列。
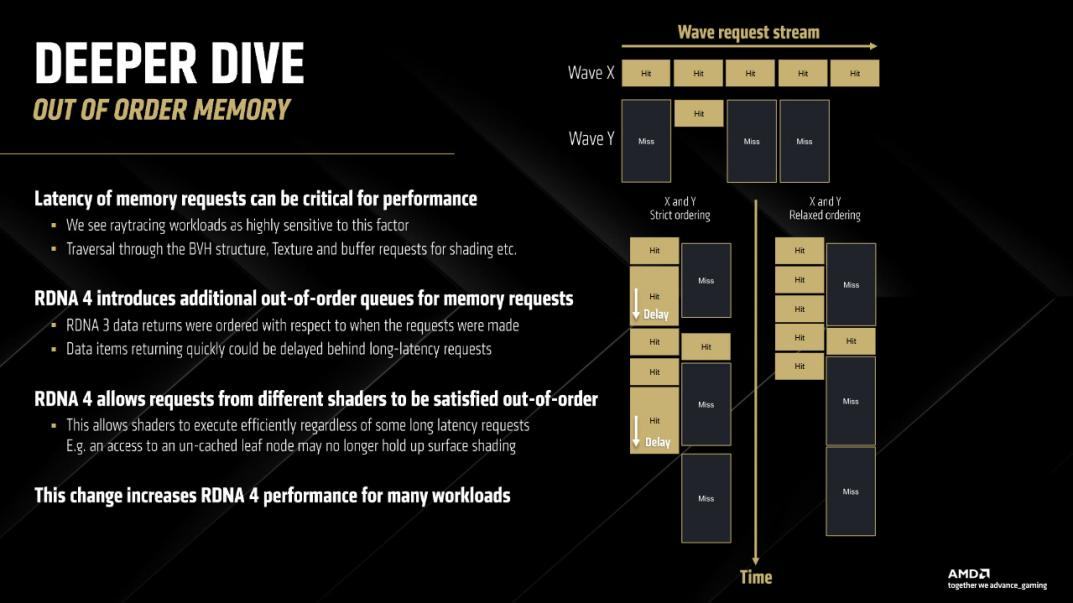
跨波前的乱序内存访问
在 RDNA 4 之前,AMD 的内存子系统显然存在一种错误的依赖情况。一个 “波”(wave)可能会等待另一个 “波” 发出的内存加载操作完成。在 GPU 中,“波前”(wavefront)、“波” 或 “线程束”(warp)大致相当于 CPU 线程。它有自己的寄存器状态,并且可以与其他 “波” 不同步运行。每个 “波” 的指令除了极少数情况(如原子操作)外,都与其他 “波” 的指令相互独立。
在 RDNA 3 中,数据返回有严格的顺序规定,以至于实际上后发出的请求不允许超越先发出的请求,即使后发出请求的数据更早准备好。(《Navi 4 架构深度剖析》,AMD 硅设计工程部门的副总裁安德鲁・波米亚诺夫斯基)
多线程编程的一个基本准则是,除非通过锁或其他机制来实现,否则线程之间不存在执行顺序的保证。这就是多线程性能得以扩展的原理。AMD 的幻灯片内容令人感到惊讶,因为内存读取没有理由成为例外情况。在反复回看相关视频、幻灯片内容后,他们在表明RDNA 4中“例外”发生了,于是为了验证它,下面的测试出现了。
测试过程
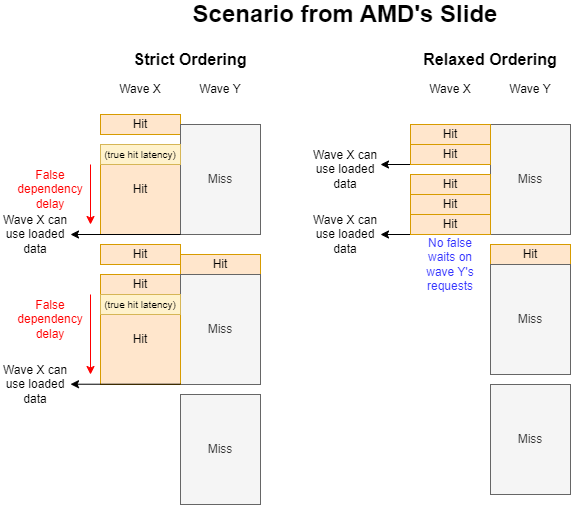
AMD 的幻灯片描述了这样一种场景:一个波(wave)的缓存未命中会阻碍另一个波快速使用缓存命中的数据。造成缓存未命中很容易,可以通过随机模式在一个大型数组中进行指针追踪(“波 Y”)。同样地,也可以将访问操作限制在一个较小的内存区域内,从而实现缓存命中(“波 X”)。但同时进行这两种操作会有问题,波 Y 可能会逐出波 X 使用的数据,导致波 X 出现缓存未命中的情况。
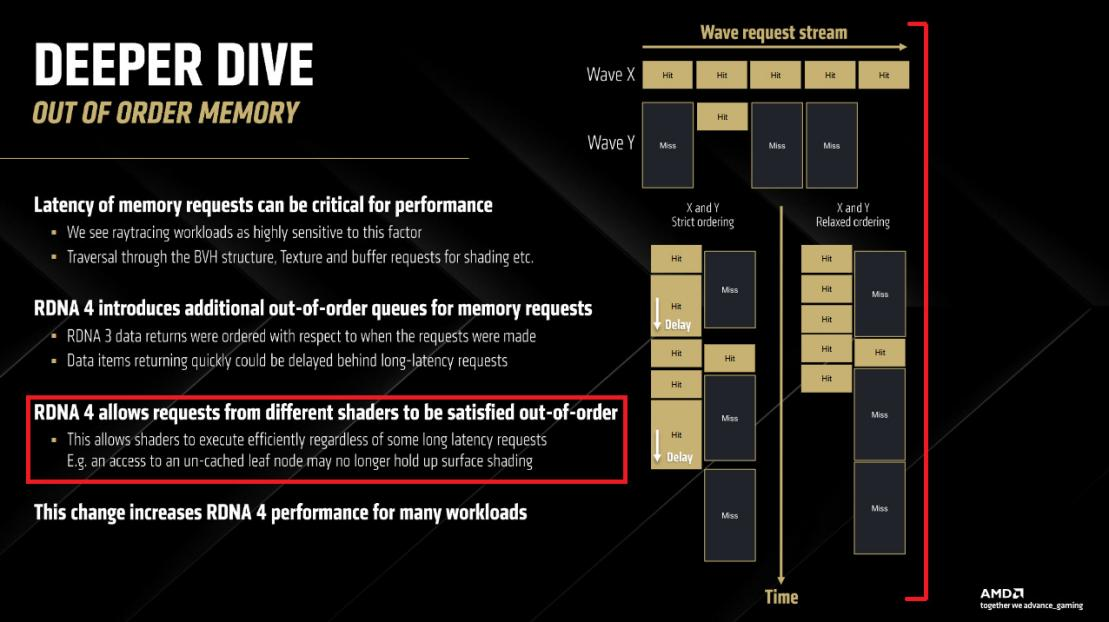
聚焦于这种情况,尝试创建可能会相互阻碍的波 X 和波 Y。
并且不去关注缓存命中和未命中的情况,而是测试一个波在等待内存访问时,是否会错误地等待另一个波的内存访问。测试中,“波 Y” 基本上是一个内存延迟测试,它进行固定次数的访问。每次访问都依赖于前一次访问的结果,并且我们让这个波通过指针追踪一个 1GB 的数组,以确保出现缓存未命中的情况。“波 X” 在每次循环迭代中进行四次独立的内存访问,然后使用加载的数据,这意味着它要等待数据从内存中返回。
一旦波 Y 完成所有访问,它会在本地内存中设置一个标志。波 X 会尽可能多地进行内存访问,直到它检测到该标志被设置,然后输出其 “得分” 并终止。将两个波放在同一工作组中运行,以确保它们共享一个工作负载组处理器(WGP),从而尽可能多地共享内存子系统。将两个波放在同一工作组中,还把 “完成” 标志置于本地内存中。波 X 每次迭代都必须检查该标志,而且最好确保标志检查不会经过波 Y 正在频繁访问(可能导致缓存污染)的相同缓存。
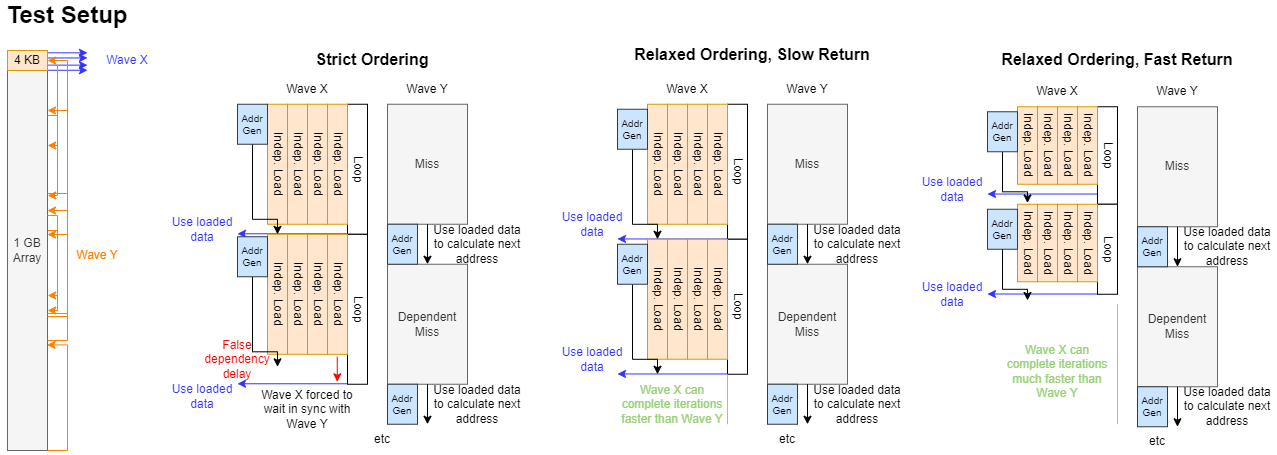
如果波 X 的每次访问都被波 Y 延迟,那么我们应该看到两者的访问次数大致相同。然而在 RDNA 3 上,波 X 的访问次数比波 Y 多,多出的数量恰好是波 X 的循环展开因子。AMD 的编译器会静态调度指令,在等待数据前先发出全部四次访问请求,然后使用 “s_waitcnt vmcnt (...)” 指令等待加载完成。
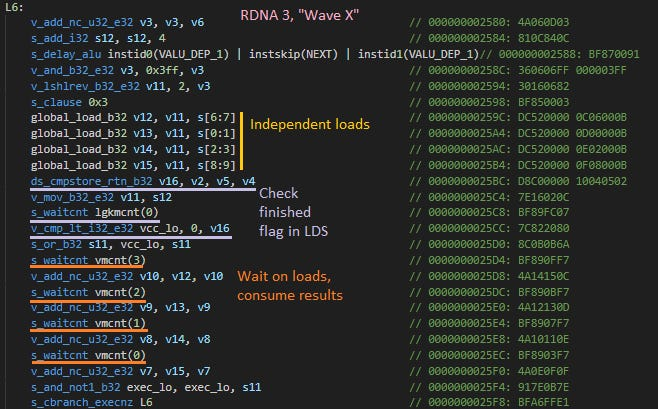
AMD 编译器为波 X 生成的 RDNA 3 汇编代码注释。
注意:通过展开循环,使每次迭代进行四次内存访问,编译器就能在等待数据前先发出这四次访问请求。
由 vmcnt 跟踪的访问总是按顺序返回,这使得编译器可以通过等待 vmcnt 递减到某个值或更低,来等待特定的访问完成。在波 Y 中,通过让所有访问都具有依赖性,这样编译器就只需等待 vmcnt 变为 0。
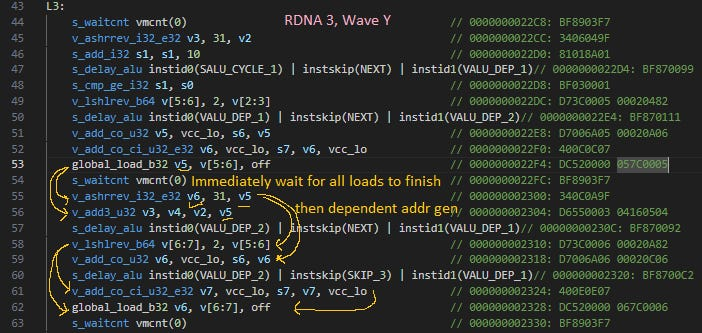
为完整起见,此处给出AMD编译器为波Y生成的RDNA 3汇编代码注释。
在RDNA 3上,“s_waitcnt vmcnt(...)”指令看上去不仅会等待自身波的请求完成,还会等待其他波的请求完成。这就解释了为什么波X每进行一次访问,波Y恰好会进行四次访问。如果进一步展开循环,让编译器在等待前安排更多独立访问,那么这个比例会上升,与循环展开因子相匹配。
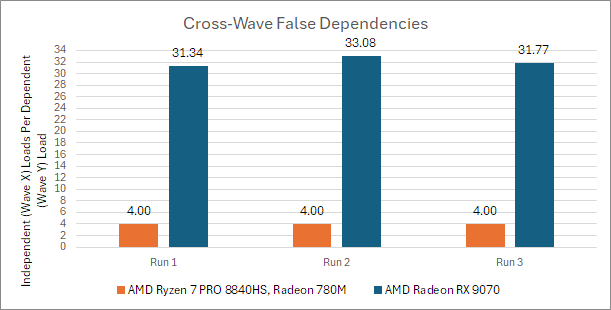
在 RDNA 4 架构下,两个波互不干扰对方的操作,这才是正常的情况。RDNA 4 在每次运行时的结果差异也更大,这是预料之中的,因为在这个测试中缓存的表现具有很强的不可预测性。测试结果出人意料,但这有力地证明了 AMD 的 RDNA 3 及更老的 GPU 架构确实存在跨波内存访问的错误延迟问题。我们还在雷诺阿(Renoir)的 Vega 集成显卡上进行了测试,发现其表现与 RDNA 3 一致。
简单来说,你可以想象着色器发出的请求会进入一个队列等待处理,而且很多请求都处于待处理状态。(《Navi 4 架构深度剖析》,AMD 硅设计工程部门副总裁安德鲁・波米亚诺夫斯基)
AMD 的展示内容暗示,RDNA 3 及更老的 GPU 存在多个波共享一个内存访问队列的情况。如上文所述,自 GCN 架构以来,AMD 的 GPU 通过硬件计数器来处理内存依赖关系,软件会等待这些计数器的信号。通过让 vmcnt(向量内存计数器)按顺序返回数据,编译器可以等待特定的加载操作完成,该加载操作产生的正是下一条指令所需的数据,而无需等待波中所有其他未完成的加载操作。RDNA 3 及更早的 AMD GPU 可能采用了共享内存访问队列,队列中的每个条目都标记了所属波的 ID。每次内存访问按顺序离开队列时,硬件会递减对应波的计数器。
也许 RDNA 4 将共享队列拆分成了每个线程独有的队列。这与 AMD 幻灯片中提到的 RDNA 4 为内存请求引入 “额外的乱序队列” 相吻合。又或许 RDNA 4 保留了共享队列,但能够以乱序方式处理队列中的条目。这就需要跟踪额外的信息,比如某个内存访问是否是其所属波中最早发出的。
其他公司的产品有类似情况吗?
共享内存访问队列并按顺序返回数据似乎是一种常见的硬件简化设计。这就引出了一个问题:英特尔(Intel)和英伟达(Nvidia)的 GPU 架构是否也存在类似的限制。
英特尔的 Xe - LPG 架构不存在跨波内存访问的错误依赖问题。在英特尔 13 代酷睿(Meteor Lake)的集成显卡上进行相同的测试时,结果会因两个波最终运行的位置而有所不同。如果波 X 和波 Y 在共享指令控制逻辑的 XVE(执行单元)上运行,波 X 的性能会比在其他情况下更低。不过,很明显 Xe - LPG 不会强制一个波等待另一个波的访问完成。英特尔后续的战法师(Battlemage,Xe2)架构也有类似的表现,英特尔较早前的第九代酷睿(Skylake)核显也是如此。
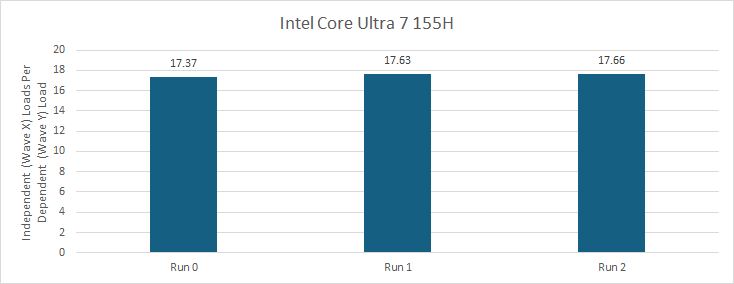
通过检查生成的汇编代码,以确保英特尔的编译器没有进一步展开循环。
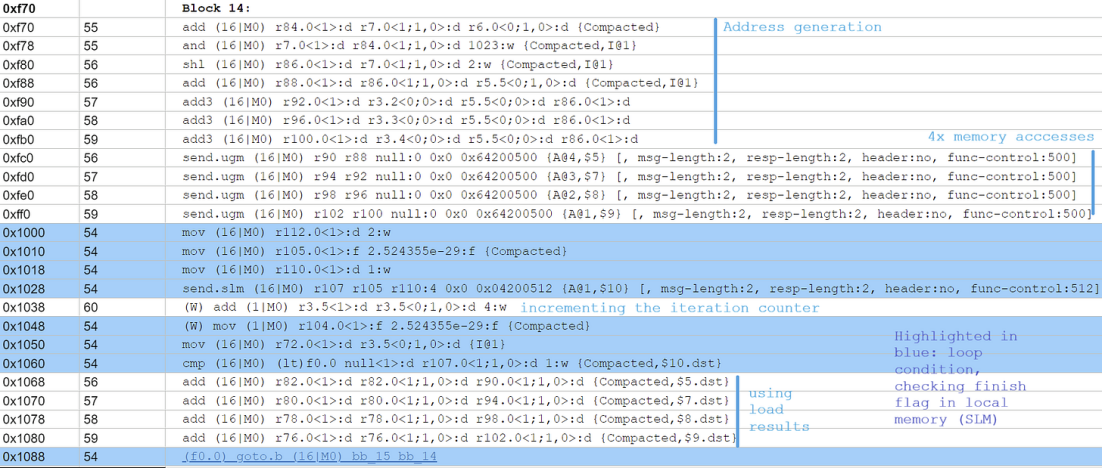
英特尔 13 代酷睿(Meteor Lake)核显为波 X 生成的汇编代码。
UGM 代表无类型全局内存,SLM 代表共享本地内存。其余的内容并不重要,只要记住英特尔的 GPU 拥有大量嵌套寄存器就好......其它没关系的。
英伟达的帕斯卡(Pascal)架构表现出的情况会因波在流多处理器(SM)中的位置不同而有所差异。每个帕斯卡 SM 有四个分区,这些分区两两配对,每对共享一个纹理单元和一个 24KB 的纹理缓存。波首先被分配到同一对分区内。就好像分区编号为 [0,1]→纹理单元,[2,3]→纹理单元。同一子分区对中的波存在错误的依赖问题。显然,除了纹理单元外,它们还共享一些通用的加载 / 存储逻辑,因为这个测试中并没有涉及纹理操作。
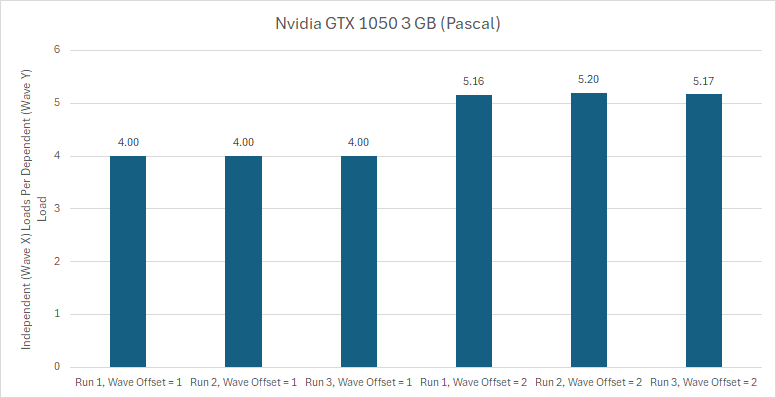
如果一个波与另一个波的偏移量不是 4 的倍数,也不是 4 的倍数加 1,那么就不会存在错误的依赖问题。在 GTX 1660 Ti 上测试发现,图灵(Turing)架构也不存在这个问题。
更出色的非阻塞加载
除了消除跨波的错误延迟,AMD 还改进了波内的内存请求处理。就像采用顺序执行的 CPU 核
心(如 ARM 的 Cortex A510)一样,GPU 可以在等待内存访问时执行独立的指令。只有当线程试图使用内存访问的结果时才会暂停。几十年来 GPU 一直都具备这种能力,不过具体实现细节有所不同。英特尔和英伟达的 GPU 采用软件管理的计分板机制,而 AMD 自 GCN 架构起就使用未完成请求计数器。
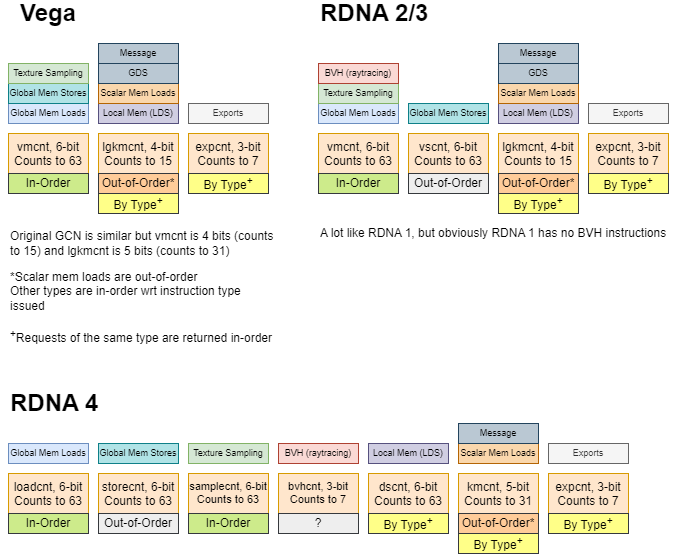
RDNA 4 采用了相同的方案,但将 vmcnt 类别拆分为多个计数器。一个线程可以交错发出全局内存、纹理采样和光线追踪相交测试请求,并分别等待这些请求完成。这让编译器在等待内存访问完成之前,能更灵活地安排工作。对 AMD 幻灯片的另一种解读是,每个计数器对应一个单独的队列,每个队列在不同波之间具有乱序行为(但在一个波内可能是有序行为)。
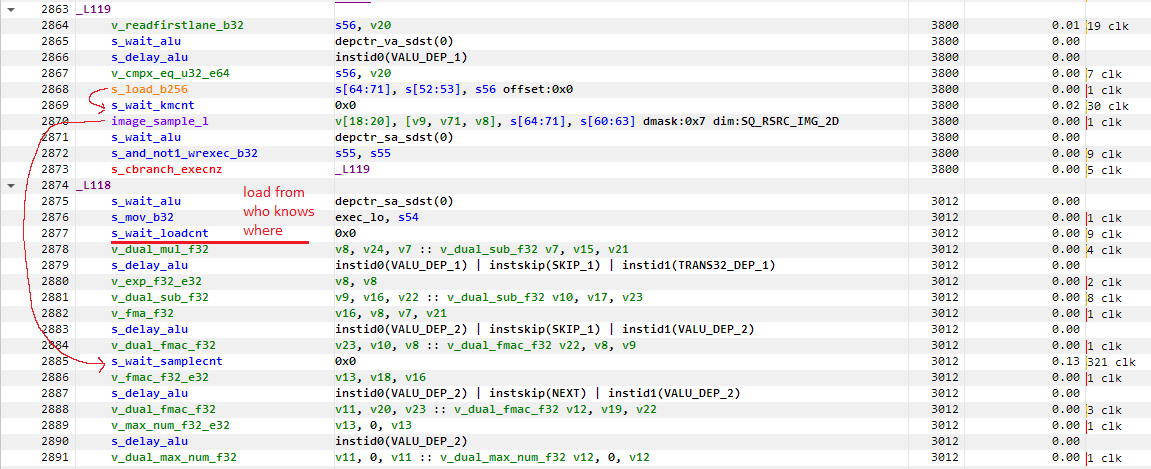
3DMark 光线追踪功能测试中 RDNA 4 汇编代码的示例,
展示了一个基本代码块分别等待其他基本代码块发出的全局内存加载和纹理采样请求。
同样,lgkmcnt 被拆分为用于标量内存加载的 kmcnt 和用于本地数据共享(LDS)访问的 dscnt。标量内存加载是乱序的,这意味着编译器必须等待所有标量内存加载完成(kmcnt = 0 或 lgmkcnt = 0),才能使用任何未完成的标量内存加载结果。在 RDNA 4 上,编译器可以交错进行标量内存和 LDS 访问,而无需等待 lgkmcnt = 0。
英特尔(Intel)和英伟达(Nvidia)的 GPU 使用软件管理的计分板。计分板中的条目可以由任何指令设置或等待,而与内存访问类型无关。因此,RDNA 4 的优化不适用于其他这些 GPU 架构。英特尔 / 英伟达方法的一个缺点是,使用大型内存请求队列需要相应较大的计分板。而 AMD 可以将一个计数器扩展一位,使一个波可以使用的队列条目数量翻倍。
结语
RDNA 4 的内存子系统增强功能令人兴奋,与 RDNA 3 相比,它在各种工作负载下都提升了性能。AMD 特别指出了在光线追踪工作负载中的优势,在这种情况下,同一工作负载组处理器(WGP)上可能会同时进行遍历和结果处理。遍历涉及指针追踪,而结果处理可能涉及更多利于缓存的数据查找和纹理采样。打破跨波内存依赖关系,将防止这些任务中不同的内存访问模式相互造成延迟。
对于光栅化来说,这可能不是个问题,因为分配到一个 WGP 的波可能处理的是相邻的像素。这些波可能会采样相同的纹理,甚至在同一纹理中彼此相邻地进行采样。如果一个波出现缓存未命中,其他波很可能也会如此。
拆分 vmcnt 和 lgmkcnt 可能对光线追踪也有帮助。光线追踪着色器在遍历过程中会发出边界体积层次结构(BVH)相交和本地数据共享(LDS)堆栈管理请求。然后,在结果处理阶段,它们可能会采样纹理或访问全局内存缓冲区。让编译器能够灵活地交错这些请求类型,同时还能等待特定请求的完成,这是一件好事。
不过,RDNA 4 处理内存依赖关系的方案与多年前的 GCN 架构在根本上并没有区别。尽管实现细节有所不同,但 RDNA 4、GCN 以及英特尔和英伟达的 GPU 都能够在缓存未命中时不立即暂停线程。每家 GPU 制造商都提升了自身在这方面的能力,无论是通过增加计分板令牌数量还是使用更多计数器。RDNA 4 确实能够实现类似 Cortex A510 风格的非阻塞加载,但这在 GPU 领域远非一项新特性。
解决跨波错误依赖关系也并非新事物。英伟达的图灵(Turing)架构就有 “乱序” 的跨波内存访问处理机制,想必他们更新的架构也是如此。英特尔至少从第九代(酷睿 Skylake)核显开始就有相同的处理机制。因此,RDNA 4 的 “乱序” 内存子系统增强功能,最好被视为是迭代性的优化调整,而不是能带来根本性变革的新技术。
尽管如此,AMD 的工程师们还是值得称赞的,因为是他们实现了这些改进。可以说,自 2019 年 RDNA 架构推出以来,RDNA 4 对 AMD 的 GPU 内存子系统做出了最重大的改变。很令人高兴的是看到该公司持续改进其 GPU 架构,使其更适合像光线追踪这样的新兴工作负载。
本文转自媒体报道或网络平台,系作者个人立场或观点。我方转载仅为分享,不代表我方赞成或认同。若来源标注错误或侵犯了您的合法权益,请及时联系客服,我们作为中立的平台服务者将及时更正、删除或依法处理。




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
联系电话:
010-61853490
新闻投稿:
server@icviews.cn
商务合作:
business@icviews.cn
问题反馈:
19800315212(微信同号)


半导纵横公众号

半导纵横小程序