评估AMD MI300A GPU
AMD的Instinct MI300A是一款大型加速处理单元(APU),它通过将两个GPU小芯片(XCD)换成三个CPU小芯片(CCD)打造而成。尽管MI300A集成了类似锐龙线程撕裂者(Threadripper)的CPU性能,但该芯片的主要吸引力仍然在于其强大的GPU计算能力。本文将评估MI300A的GPU性能,并通过与包括MI300X在内的其他几款GPU的对比数据,来了解它的性能水平。
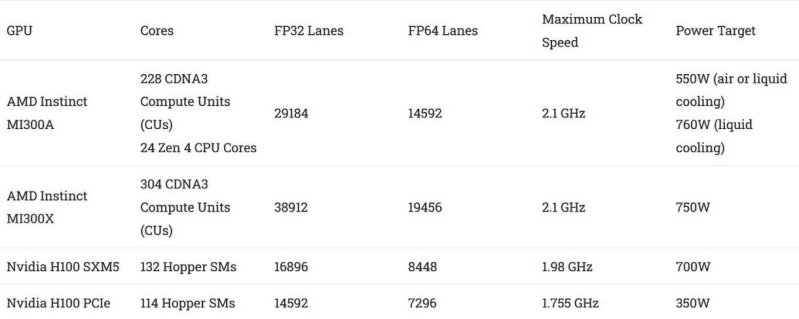
OpenCL计算吞吐量
与纯GPU版本的同类产品相比,MI300A可能减少了几个GPU小芯片(XCD),但它的计算吞吐量依然强劲。在几乎所有主要的32位或64位运算类别中,它都远远领先于英伟达的H100 PCIe版本。由于H100 SXM5版本的流式多处理器(SM)数量更多,其计算吞吐量应该会略有提升。但SM数量增加16% 可能不足以大幅缩小H100与两款MI300产品之间的差距。
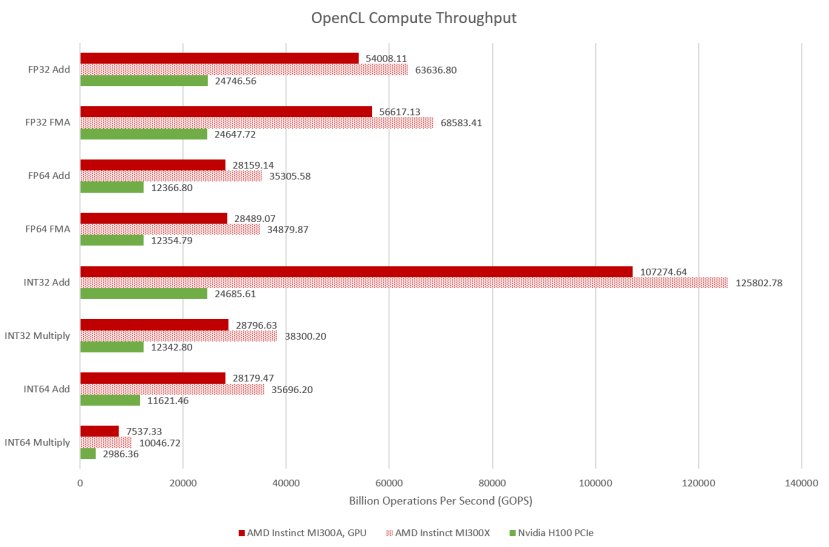
MI300A的FP32吞吐量可达113.2万亿次浮点运算(TFLOPS),每个融合乘加运算(FMA)计为两次浮点运算。相比之下,H100 PCIe在相同测试中达到49.3 TFLOPS。
尽管GPU在向量吞吐量方面表现强大,但现代CPU也能具备相当可观的向量吞吐量。借助AVX - 512指令集,MI300A的24个Zen 4核心可维持2.8 TFLOPS的吞吐量。与一些较旧的消费级GPU相比,这已经相当不错了。但MI300A的GPU性能过于强大,以至于CPU端的吞吐量与之相比只是一个可忽略不计的小数。
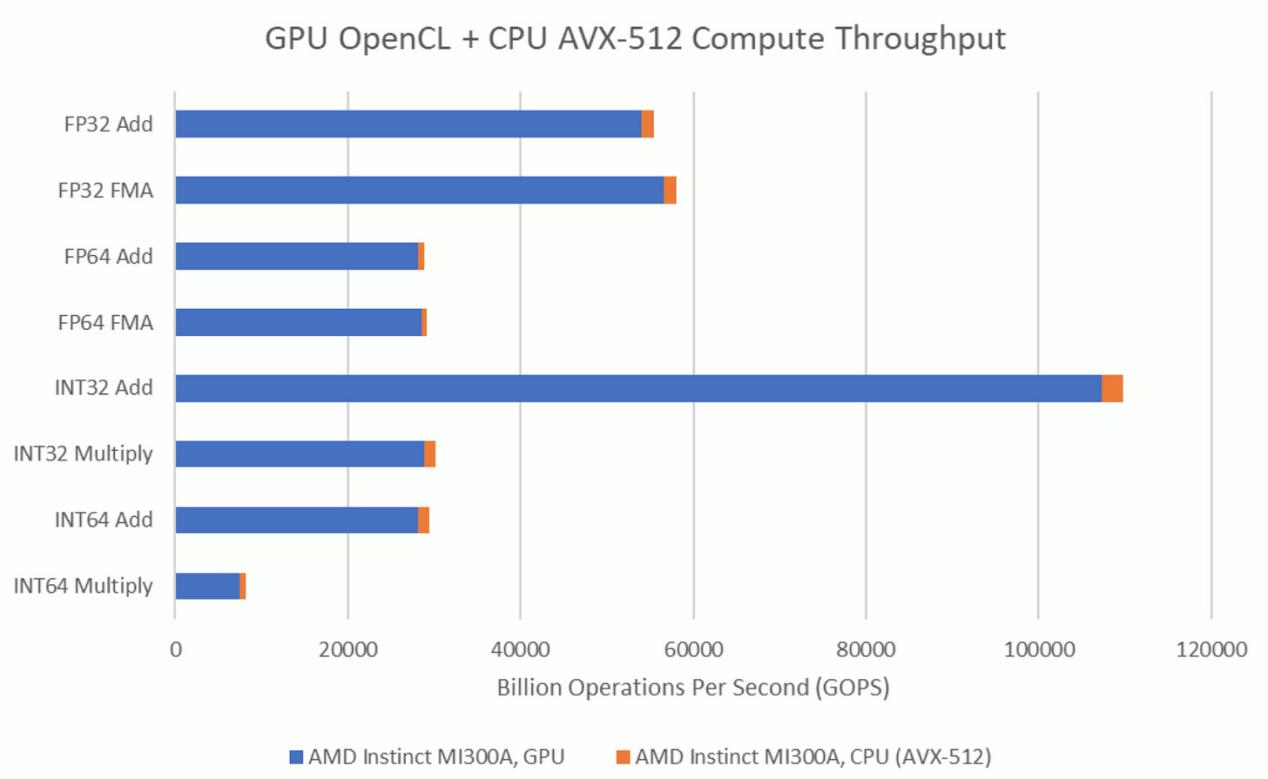
因此,与AMD的Hawk Point这类典型的消费级集成显卡解决方案相比,MI300A在CPU和GPU规模之间实现了截然不同的平衡。锐龙7 PRO 8840HS的Radeon 780M集成显卡在基本的32位运算方面表现不俗,但CPU端的向量吞吐量仍然不可忽视。
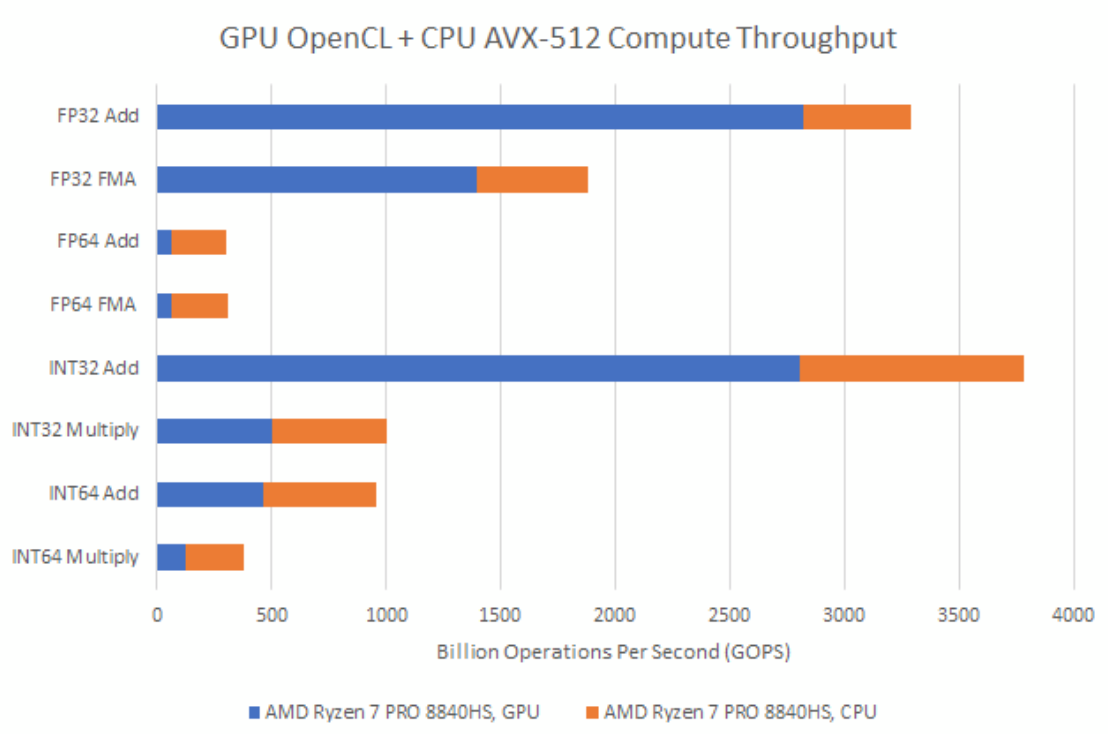
消费级GPU架构不太重视FP64吞吐量,因此8840HS的8个Zen 4核心能提供比GPU端更高的吞吐量。在整数乘法方面,Zen 4也具有优势,尽管不像在FP64方面那么明显。从计算吞吐量的角度来看,MI300A更像是一款恰好集成了CPU的GPU。
一级缓存带宽
测量缓存带宽是评估MI300A的另一种方式。在此,通过一个1KB的小数组来测试加载吞吐量,这个数组在任何GPU的一级缓存(L1)中都能容纳。
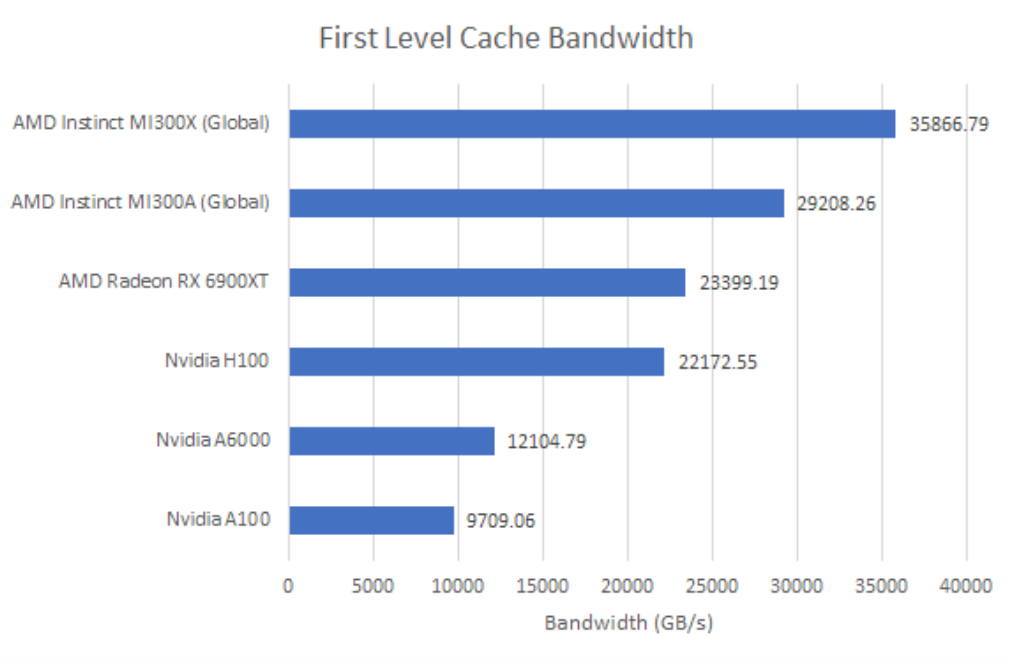
此处测试的H100 PCIe
一级缓存带宽的情况与计算吞吐量类似。MI300A的GPU相当于稍小版本的MI300X,有点类似于AMD的HD 7950是稍小版本的HD 7970。同样,AMD的MI300平台规模庞大,即便为24个CPU核心留出空间,仍能将英伟达的H100远远甩在身后。面向消费级市场的RX 6900 XT表现也不错,因为它拥有非常高的一级缓存带宽、一级向量缓存,且运行时钟频率更高。
除了缓存,GPU还提供了一个仅在线程工作组内可见的本地内存空间。AMD的GPU通过每个计算单元内的本地数据共享(Local Data Share)来支持这一点,而英伟达近期的GPU则从其一级缓存中划分出本地内存。
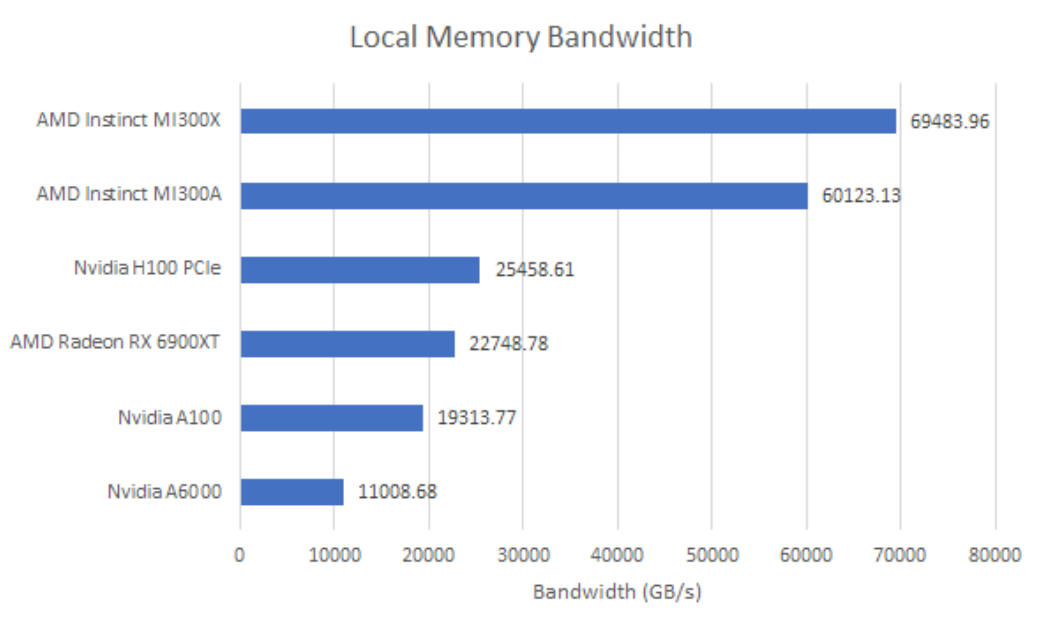
MI300系列GPU拥有极为充裕的本地内存带宽,两个版本的带宽均超过60TB/s,其他产品则望尘莫及。
原子操作吞吐量
原子操作在多线程应用中很有用,因为它能让一个线程确保一系列底层操作不受其他任何线程干扰地执行。例如,向一个内存地址增加一个值,这涉及从内存中读取旧值、执行加法运算,然后将结果写回。如果在这些操作之间有其他任何线程访问该值,就会得到过时的数据,更糟糕的是,可能会覆盖结果。
GPU通过L2切片中的特殊执行单元来处理全局内存原子操作。相比之下,CPU核心通过在操作完成前保留对缓存行的所有权来处理原子操作。这意味着,即使没有竞争,GPU的原子操作吞吐量也可能受到L2层执行单元的限制。MI300A对全局内存的原子加法操作吞吐量尚可,但未达到我的预期。自GCN架构以来,AMD的GPU每个L2切片就有16个原子算术逻辑单元(ALU)。在RX 6900 XT上能接近这个水平,但在MI300A上却不行。
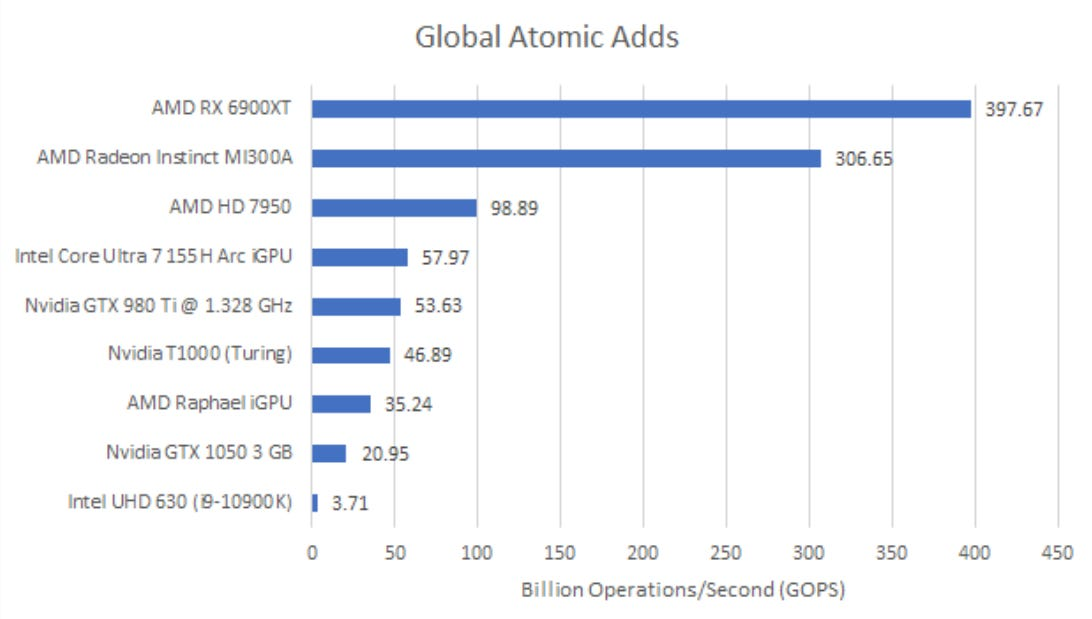
由于原子加法是一种读取 - 修改 - 写入操作,每秒3066.5亿次对INT32值的操作,换算成L2带宽就是2.45TB/s。在6900XT上,每秒3976.7亿次操作(GOPS)相当于3.2TB/s。或许MI300A必须采取一些特殊措施,以确保在如此大规模的GPU上原子操作能正常进行。与6900XT这类消费级GPU相比,MI300A的L2切片并不独占某一块地址空间。一个地址可能会被缓存到不同XCD的L2中。执行原子操作的L2切片必须确保没有其他L2缓存了该地址。
OpenCL也允许对本地内存进行原子操作,当然,本地内存原子操作仅在一个工作组内可见,作用范围有限。但这也意味着计算单元无需担心在整个GPU范围内确保一致性,所以原子操作可以在本地数据共享区内执行。这使得提升吞吐量要容易得多。
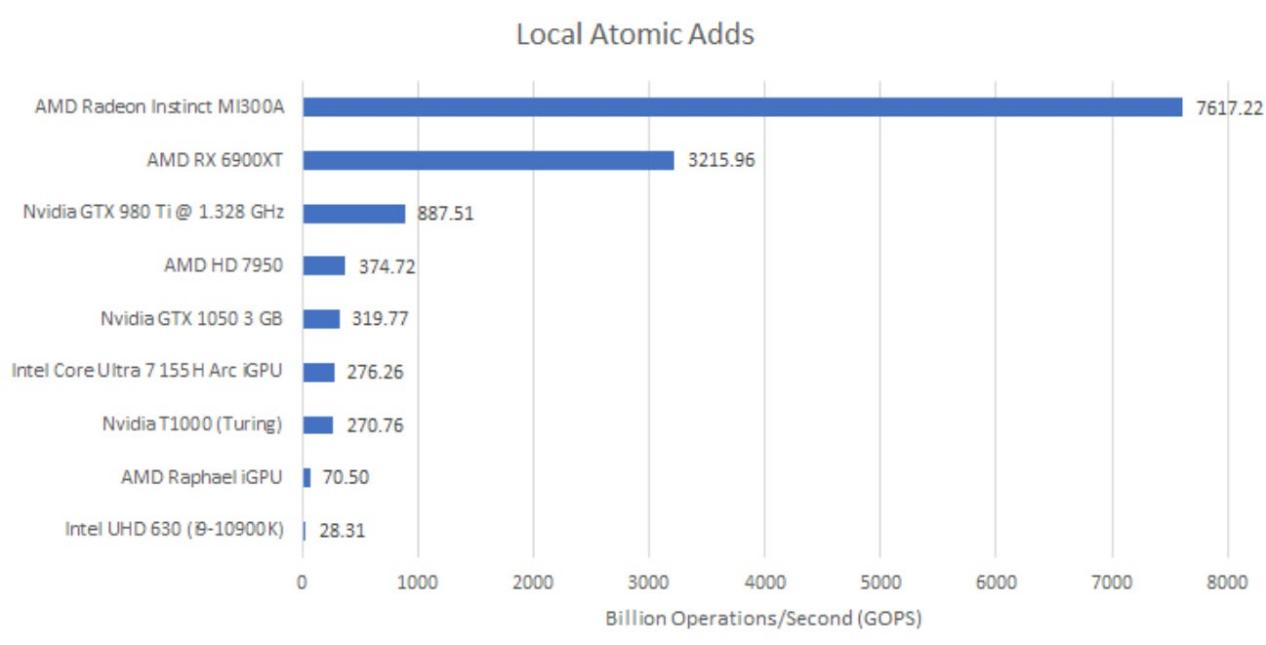
现在,MI300本地数据共享(LDS)实例内的算术逻辑单元(ALU)限制了原子操作吞吐量。这意味着其原子操作吞吐量极高,将RX 6900XT远远甩在身后。
FluidX3D
FluidX3D采用格子玻尔兹曼方法(LBM)来模拟流体行为。它经过特殊优化,在“除极端边缘情况外的所有情况”下,都能使用单精度浮点数(FP32)而非双精度浮点数(FP64),同时仍能保证较高的精度。在FluidX3D的内置基准测试中,MI300A的GPU表现,比微观基准测试和规格参数所显示的,更接近其性能更强的同类产品MI300X。测试的MI300A服务器采用风冷散热,因此每个GPU的默认功率目标为550瓦。在该功率设置下,MI300A仅比MI300X慢1%。若将功率目标提高到760瓦,MI300A的性能比名义上规模更大的纯GPU产品MI300X领先4.5%。
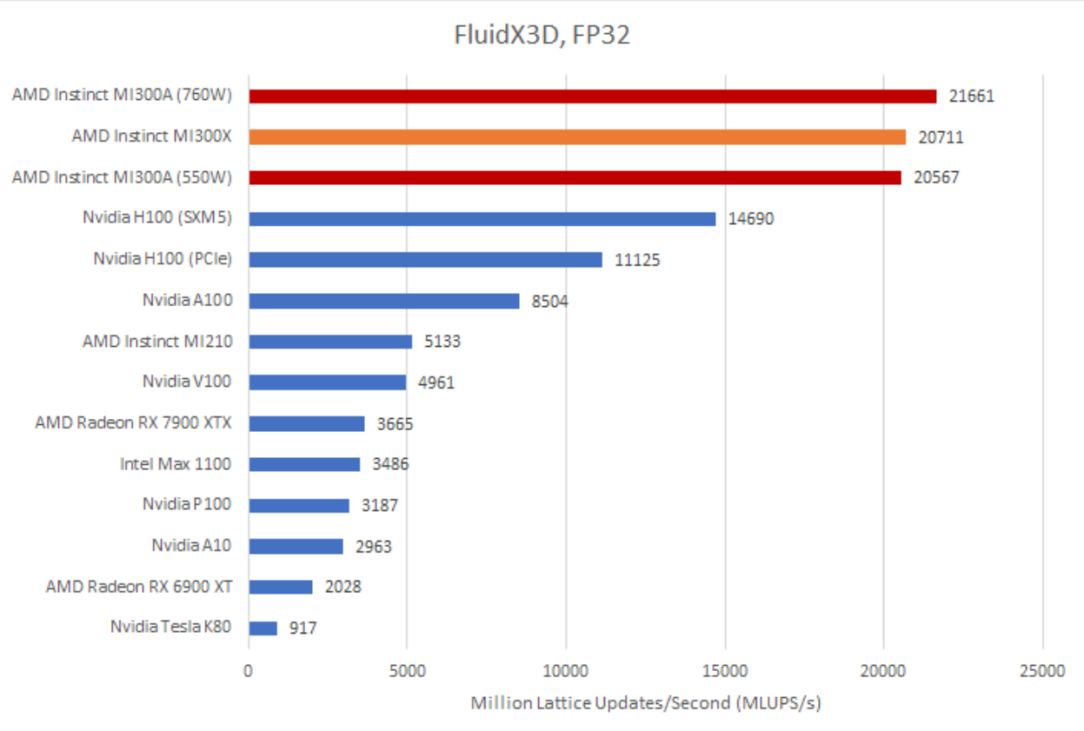
测试FluidX3D很复杂,因为该软件在不断更新。MI300A的部分领先优势,可能归因于我们6月份测试MI300X之后软件所做的优化。使用FP32时,FluidX3D往往还非常受内存限制,所以出现类似的测试结果并不意外。两款MI300产品依旧大幅领先于英伟达的H100,不过H100的SXM5版本确实在一定程度上缩小了差距。H100的SXM5版本使用HBM3,其DRAM带宽达到3.9TB/s,而使用HBM2e的H100 PCIe版本带宽为3.35TB/s。
由于FluidX3D严重受限于内存带宽,该程序可以使用16位格式来存储数据。其FP16S模式使用IEEE - 754的FP16格式进行存储。为了将精度最大化,它会在计算前将FP16值转换为FP32。GPU通常具备对FP16到FP32转换的硬件支持,这将因使用FP16S存储而产生的计算开销降至最低。
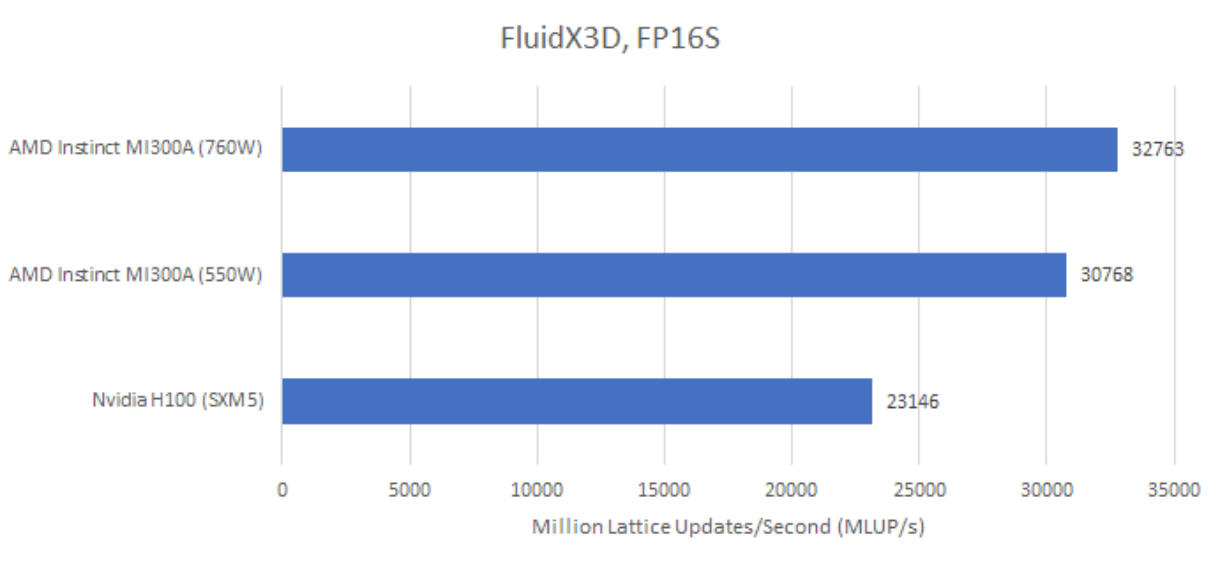
在FP16S模式下,MI300A和H100的性能都有所提升,且MI300A仍保持较大优势。
FluidX3D还有一种FP16C模式,它采用一种自定义的FP16格式。尾数部分多了一位,这一位是从指数部分截取而来。这样在使用与FP16S模式相同内存带宽的情况下提高了精度。然而,GPU没有将自定义FP16格式转换为FP32的硬件支持。因此,与FP16S模式相比,转换需要更多指令,从而增加了计算需求。
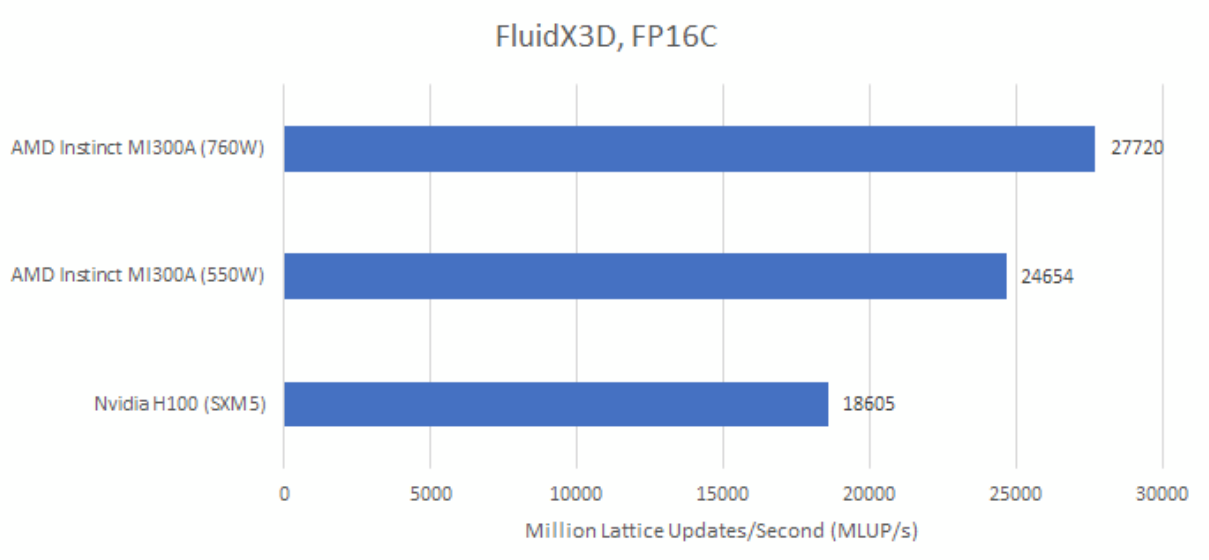
在FP16C模式下,MI300A依旧领先于H100。从计算能力和内存带宽两方面来看,AMD打造的GPU规模要大得多,所以无论FluidX3D更需要计算能力还是内存带宽,MI300A都具有优势。
在FP16C模式下,功率目标也更为关键。功率从550瓦提升到760瓦,FP16C模式下性能提升12.4%。而在FP32或FP16S模式下,功率提升到760瓦时,性能分别仅提升5.3%和6.5%。很可能是因为FP16C模式对计算能力有更高要求,同时对内存带宽需求也相当大,从而导致更高的功率需求。
计算引力势(FP64)
像MI300和H100这类大型计算GPU,与消费级GPU的区别在于它们能提供可观的FP64吞吐量。消费级GPU不重视FP64,因为图形渲染不需要那么高的精度。
这是由Clam(切斯特)自行编写的工作负载,基于他高中实习时一个长期运行的任务。该程序读取赫歇尔空间望远镜拍摄的包含柱密度值的FITS图像,并进行暴力引力势计算。2010年编写的原始程序在四核Nehalem系统上需要整整一个周末才能运行完,且是用Java编写的。
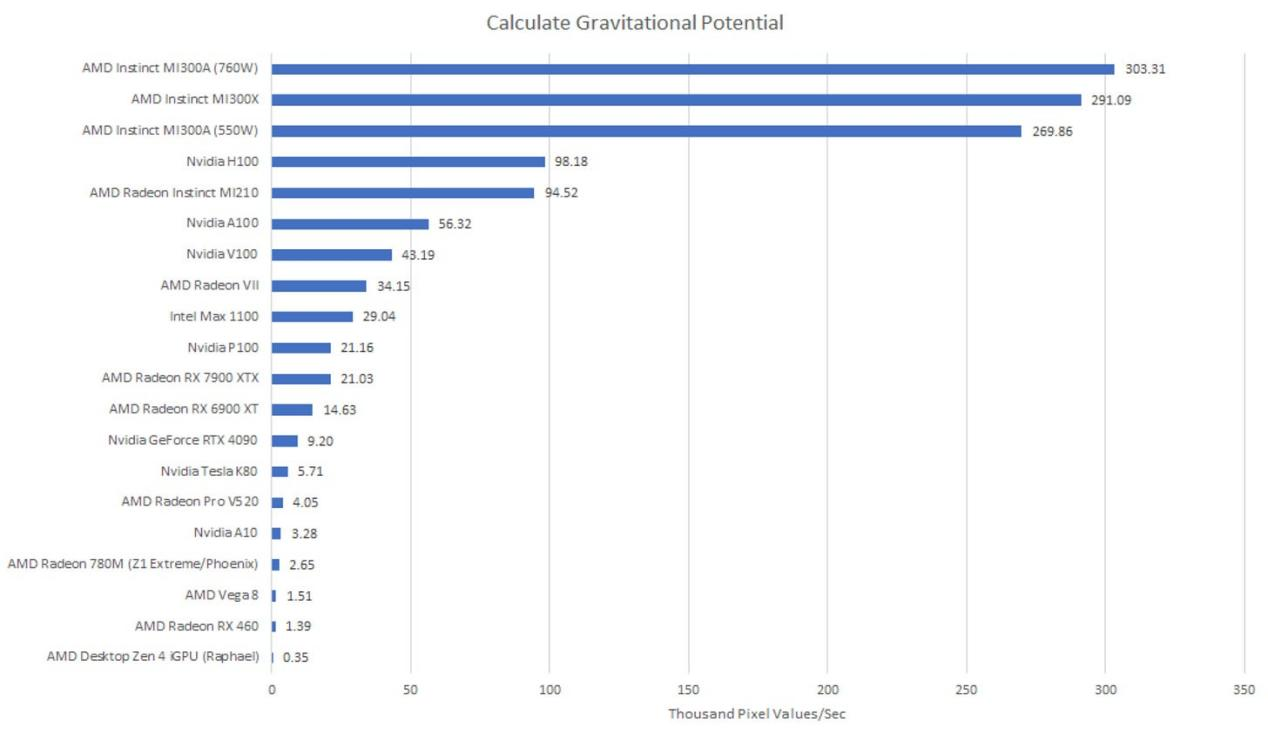
AMD的MI300A仅需17.5秒就能完成这项任务,这可比一个周末的时间短多了。真希望2010年我就能有这样的计算能力。英伟达的H100 PCIe则需54秒完成。虽然比不上MI300A,但速度依然很快。这两款数据中心GPU都比锐龙9 7950X3D的集成显卡快,后者完成这项任务需要四个多小时。
测试在GPU 3上运行。即使将功率目标设定为760瓦,MI300A也无法维持2.1GHz的频率。
对比三款MI300产品的测试结果也很有意思。MI300A的GPU比MI300X小,这在FP64综合测试中表现得很明显。在测量计算吞吐量时,将所有数值都保留在寄存器中。但像这样的工作负载也会用到缓存子系统,而且数据移动会消耗功率。由于我2010年的输入数据能存放在无限缓存(Infinity Cache)中,所以几乎不会用到动态随机存取存储器(DRAM)。不过,代码还是让MI300A尽可能地发挥出其功率。将功率目标从550瓦提升到760瓦,性能提升了12.4%,奇怪的是,这使得MI300A的性能超过了MI300X。
一方面,功率目标的差异能带来如此大的影响,令我印象深刻。另一方面,功率目标提高38%,性能却仅提升12.4%。很难确定这是否是一笔划算的交易。为了让程序从19.7秒跑完缩短到17.5秒,要额外消耗大量的功率。
GROMACS
GROMACS用于模拟分子动力学。在这方面,Cheese/Neggles在STMV基准测试系统上对MI300A和H100 SXM5进行了测试。同样,与英伟达的H100相比,两款MI300产品处于不同的性能区间。
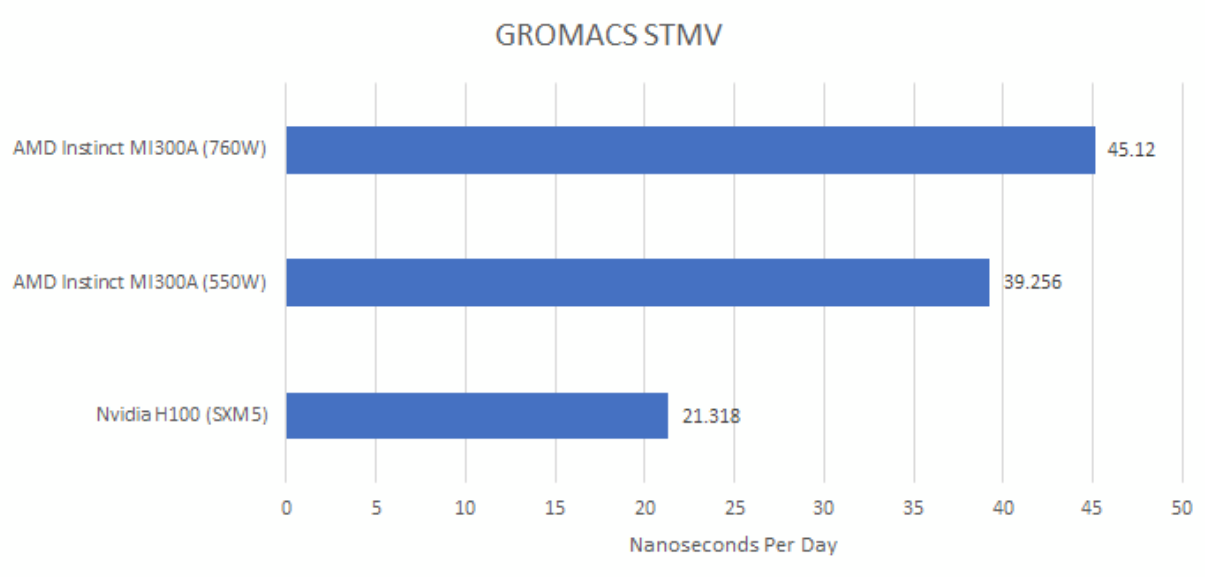
同样,更高的功率目标意味着更高的性能。在GROMACS测试中,MI300A在760瓦模式下性能提升了15%,这一提升幅度甚至比引力势计算工作负载,或FluidX3D的FP16C模式下还要大。
总结
AMD为了打造MI300A,缩减了MI300X的GPU规模。24个Zen 4核心提供了强大的CPU算力,占据了MI300芯片的四分之一区域。但MI300的主要吸引力仍然在GPU。AMD在个人电脑领域的集成显卡芯片,依旧是以CPU优先的解决方案,配备的集成GPU足以处理图形任务或偶尔的并行计算。相比之下,MI300A是一款大型GPU,只不过恰好集成了CPU。那24个Zen 4核心旨在为GPU提供支持,并处理那些不适合GPU架构的代码部分。看到一个24核心的CPU扮演这样的角色,感觉挺有趣,但这就是MI300A的规模。
在GPU方面,MI300A的表现超出预期。综合测试清楚表明,它的GPU规模比MI300X小,但在实际工作负载中,MI300A表现出色。部分原因在于,GPU工作负载往往对带宽需求巨大,而两款MI300产品拥有相同的内存子系统。大型GPU通常也受功率限制,MI300A可能通过提高时钟频率来弥补一些差距。
从更高层面来看,AMD凭借MI300平台打造出如此强大的产品,即便牺牲部分GPU算力来集成CPU,也能轻松超越H100。这一表现令人印象深刻,因为H100绝非小算力的GPU。像MI300A和MI300X这样的产品表明,AMD如今掌握了构建大型集成解决方案所需的互连和封装技术。这使该公司成为一个不容小觑的竞争对手。
本文转自媒体报道或网络平台,系作者个人立场或观点。我方转载仅为分享,不代表我方赞成或认同。若来源标注错误或侵犯了您的合法权益,请及时联系客服,我们作为中立的平台服务者将及时更正、删除或依法处理。




联系电话:
010-61853490
新闻投稿:
server@icviews.cn
商务合作:
business@icviews.cn
问题反馈:
19800315212(微信同号)


半导纵横公众号

半导纵横小程序