铠侠332层NAND,开始出样
铠侠已启动采用第十代BiCS FLASH 3D闪存技术打造的1Tb三级单元(TLC)存储芯片样品出货。当前高端存储需求持续攀升,全球厂商争相为人工智能系统、数据中心及企业客户供应更大容量、更低功耗的存储产品,铠侠此举也凸显了这场行业竞争。
该款芯片主要面向企业级与数据中心固态硬盘(SSD)市场,铠侠表示,其能够提升设备性能、扩容存储容量并降低功耗。芯片目前在日本岩手县北上市工厂第二厂区完成生产。
铠侠介绍,第十代产品搭载CMOS直连阵列技术、栅极漏极同节距选择门技术,两项技术自第八代BiCS FLASH平台起便已投入使用。该代闪存的NAND接口速率可达4.8吉比特每秒,较第八代提升33%。通过堆叠332层存储单元并优化横向存储密度,芯片位密度提升59%;写入功耗效率优化18%,读取功耗效率提升30%,有助于降低数据中心与企业基础设施的整体能耗。
铠侠采用双线并行研发策略:第九代产品主打以较低制造成本实现高性能;第十代技术则依托先进多层堆叠工艺,主攻超大容量与更强综合性能。目前送出的样品仅用于功能验证,量产版本的规格参数或将存在调整。
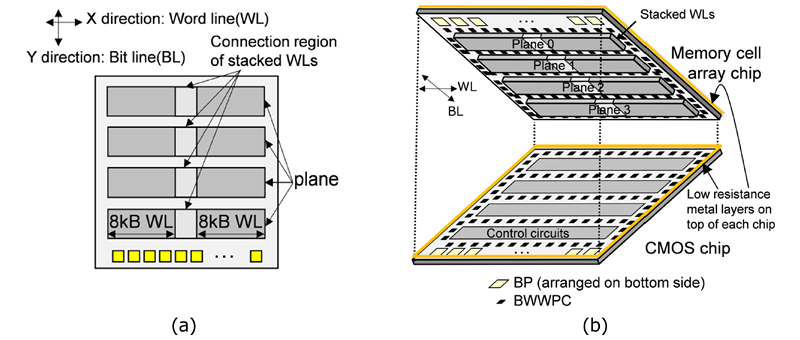
铠侠第十代BiCS闪存:CBA架构与读取性能优化
随着尺寸微缩的难度持续攀升,铠侠不再单纯依靠堆叠层数,而是将键合技术作为下一代NAND闪存的核心差异化竞争力。
性能提升的核心依托铠侠CBA(CMOS直连存储阵列)架构。该工艺对晶圆对位精度、互连集成度要求极高,但能效提升效果显著。据日经新闻消息,铠侠这款NAND闪存的读写速度相比竞品高出约20%至30%。
CBA架构将存储单元与外围电路分制于两片晶圆后再完成键合,实现更高效的电路布局与更高存储密度。该思路与三星晶圆对晶圆(W2W)键合技术大体相似,但铠侠自218层闪存世代起,便将CBA列为自家NAND技术路线图的核心方案。
除存储密度提升外,第十代BiCS闪存读取延迟缩短4微秒,读取功耗降低29%,单位容量读取能耗从约100毫焦/GB降至75毫焦/GB左右。性能大幅优化主要源于对连续读取过程中未选字线的调控优化。在332层超高堆叠结构中,大部分延迟与功耗损耗都来自长字线链路反复在地电位(VSS)与读取电压(VREAD)之间充放电。
铠侠并未在每个读写周期内将字线电压在地电位与读取电压间完全放电、重新充电,而是仅把电压降至中间档位,再回升至读取电压开启下一轮读取,大幅提升高堆叠层数NAND闪存的工作能效。
铠侠敲定2027年第二季度赴美上市
近日,全球NAND闪存领军企业铠侠在年度股东大会上正式官宣上市规划,铠侠首席财务官河村芳彦表示,公司计划于2027财年第二季度登陆美国主板市场,通过发行美国存托股份(ADS)完成正式挂牌,并且同步考量日本本土股票拆分事宜。
行业资料显示,铠侠目前仅以场外交易(OTC)形式流通美股存托凭证,交易流动性、市场关注度与主流主板标的存在明显差距。本次赴美主板上市,意味着铠侠将打通美国核心资本市场,无需依托场外交易体系,可直接对接全球机构投资者,大幅提升资本运作能力与国际品牌影响力。目前,公司已启动承销商筛选工作,各项上市筹备工作有序推进。
铠侠此番冲刺美股,目的是结合行业周期、产业趋势与自身战略的深度布局,核心动因聚焦三大维度。首先,借力美股高估值赛道拓宽融资渠道,为3D NAND先进制程研发、产能扩建及技术迭代提供资金支撑,稳固自身在高端存储领域的技术壁垒。其次,适配AI算力存储爆发的产业趋势,存储行业正进入AI驱动的新一轮增长周期。铠侠深耕3D堆叠闪存技术,赴美上市可精准对接北美AI产业链核心资源,深化与全球云厂商、算力企业的合作,抢占AI存储增量市场。最后,推进独立化、国际化战略落地。长期以来,铠侠背靠日系产业体系,此次赴美上市是其脱离传统日系资本框架、走向全球化独立运营的关键一步。
本文转自媒体报道或网络平台,系作者个人立场或观点。我方转载仅为分享,不代表我方赞成或认同。若来源标注错误或侵犯了您的合法权益,请及时联系客服,我们作为中立的平台服务者将及时更正、删除或依法处理。




联系电话:
010-61853490
新闻投稿:
server@icviews.cn
商务合作:
business@icviews.cn
问题反馈:
19800315212(微信同号)


半导纵横公众号

半导纵横小程序