芯片优化,救活车载AI

汽车行业正迎来一场前所未有的整车电子架构变革。车辆已从单纯的机械总成,进化为依托智能网络、具备强大数据处理能力的软件定义系统。当下高阶驾驶辅助系统(ADAS)、L3及以上级别自动驾驶方案、沉浸式车载座舱影音系统,都要求各类运算在车辆本地完成。受制于带宽上限、数据隐私风险与通信时延等硬性约束,把实时计算全部交由云端服务器处理并不现实。为保障整车运行安全可靠,车载智能化方案高度依赖分布式边缘AI架构,深度学习神经网络直接在数据采集端本地运行。但在车载供电系统功率资源有限的硬件环境中部署复杂AI模型,催生了尖锐的工程矛盾:既要满足海量算力需求,又必须严守功耗与散热的硬性限制。想要化解这一矛盾,行业必须从硬件硅片设计、内存架构、软硬件协同压缩等多个维度落地车载边缘AI半导体优化,依靠架构创新破解痛点。
一、车载架构向边缘AI全面转型
传统车载电子采用分散式电子控制单元(ECU)方案,各个控制器独立负责刹车、转向、车窗控制等单一功能。而机器视觉、雷达摄像头融合感知、座舱监测系统的落地,彻底打破了这种碎片化硬件布局。新一代车载感知系统需要大规模并行运算,推动整车电气架构向中央域控/分区集中式架构演进,边缘计算成为车载算力的核心载体。
依托本地边缘AI,车载端可无延迟处理超高分辨率影像、激光雷达点云数据;数据留存车内也能守护用户隐私,即便车辆驶入无蜂窝网络的偏远区域,整套智能系统仍可正常工作。
不过,在车端部署大规模深度学习网络(DNN),也带来巨大硬件资源压力。主动安全系统对确定性时延要求严苛:目标检测模型需在毫秒级输出推理结果,才能及时触发避障动作。为达标严苛指标,车载芯片设计思路必须彻底革新,面向边缘AI的半导体优化成为下一代智能汽车硬件研发的核心课题。
二、车载芯片陷入性能与功耗的两难瓶颈
汽车环境对半导体器件提出了极其严苛的运行要求。与配备主动式液冷系统和千瓦级电力的超大规模数据中心不同,汽车系统级芯片(SoC)必须安装在标准的、散热性能尚可的密封外壳内,同时还要尽可能减少从车辆电气系统中汲取的电力。
过高的功耗构成了一项重大挑战。在电动汽车(EV)中,人工智能加速器消耗的每一瓦功率都会减少车辆的续航里程。此外,高功耗还会产生大量热量。由于汽车计算模块通常采用密封设计以防止灰尘、振动和潮湿,因此如何在不使用噪音大且容易发生故障的机械风扇的情况下散发这些热负荷是一项极其复杂的工作。
为了控制热负荷,车辆的主AI处理器通常需要在严格的功耗预算内运行,功耗往往限制在几十瓦以内。然而,在如此有限的功耗下,处理器必须同时实现每秒数千亿次的运算(TOPS)。这种严峻的工程挑战凸显了传统通用处理器的不足,也使得针对边缘AI的半导体优化成为现代汽车设计中至关重要的环节。
三、NPU与ASIC:专用芯片破解算力功耗矛盾
为了克服性能与功耗之间的瓶颈,汽车芯片设计人员已将目光从通用CPU和GPU转向专用芯片解决方案。虽然通用CPU可以进行顺序计算,但它们无法像深度学习计算那样进行并行计算。GPU虽然可以很好地进行并行计算,但它们的功耗过高。
正是由于这种结构上的不匹配,才促成了专门为人工智能相关任务定制的神经网络处理器(NPU)和专用集成电路(ASIC)的开发。这是因为这类处理器采用了特殊的硬件架构,能够实现快速的矩阵乘法和卷积运算--而这正是神经网络背后的基本数学运算。
通过针对边缘人工智能的半导体优化,硅工程师将大量的乘加运算(MAC)单元直接集成到硬件中。这些组件每个时钟周期执行数千次矩阵运算。由于避免了普通CPU中不必要的指令解码、分支预测和缓存开销,这些专用加速器能够实现卓越的能效,提供高达数TOPSW 的性能。这种基础硬件定制使得边缘人工智能模块能够在标准的汽车功耗预算内轻松处理多摄像头、高帧率的计算机视觉数据流。
四、突破内存墙:存储架构优化
深度学习硬件领域存在公认的内存墙瓶颈:数据在片外DRAM与片内运算单元间的传输功耗,远高于数据本身运算功耗。想要削减数据搬移开销,内存架构优化成为边缘AI半导体优化的重中之重,优化思路分为三点:
- 片上缓存优化:在处理器裸片内置大容量高速SRAM缓存,尽可能将神经网络全部参数存入片内,减少反复访问片外内存;
- 高速内存互联:必须调用外部存储时,选用LPDDR5X等新一代低功耗内存,或依托3D先进封装搭载HBM高带宽内存;
- 数据流复用设计:优化硬件流水线排布,单次从内存调取的权重、像素数据,尽可能复用在多轮运算中,减少重复读写。
经过系统化半导体优化,内存接口能耗最高可降低50%,为车载安全系统提供低时延、稳输出的硬件底座。
五、软硬件协同设计+模型压缩
单靠硅架构优化无法解决效率难题。真正提升汽车效率需要软硬件协同设计策略,其中深度学习网络需要进行压缩和优化,以匹配底层硬件架构。这种从模型到芯片的适配依赖于三种主要的软件优化技术:
- 量化压缩:神经网络原始训练多采用FP32(32位浮点)精度,边缘端浮点运算功耗极高;量化将模型参数转为INT8/INT4低位整数格式,在几乎不损失精度的前提下,内存占用最高节省75%,硬件改用低成本整数运算单元即可完成推理;
- 网络剪枝与稀疏优化:深度学习网络存在大量冗余权重,剪枝算法剔除不影响精度的无效连接;搭配原生支持稀疏运算的硬件,芯片自动跳过零值乘法,节约时钟周期、降低功耗;
- 硬件感知编译:借助自动化编译器,将神经网络代码定向编译适配芯片硬件资源,合理分配指令与内存空间,规避运算卡顿。
六、实时确定性与ISO 26262功能安全合规
车载芯片可靠性标准远严于消费电子:手机芯片故障顶多造成APP闪退,自动驾驶芯片失效却可能引发重大行车事故。面向边缘AI的半导体优化,必须在高性能、低功耗之外,兼顾ISO 26262车规功能安全规范,核心落地要求见下表:
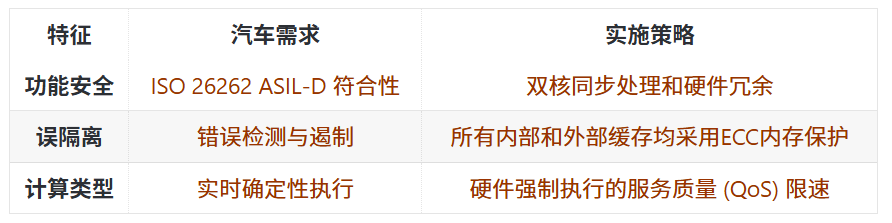
为满足安全标准,芯片需要预留冗余电路、纠错模块,占用硅片面积同时小幅抬升功耗;在严苛安全认证、低功耗、高性能三者间取得平衡,是车载边缘AI芯片设计的顶尖工程难点。
七、前沿技术趋势:存内计算与芯粒架构
伴随自动驾驶算法向大参数视觉语言模型迭代,传统单片SoC架构逐步逼近物理性能上限,两大前沿架构成为下一代半导体优化核心方向:
- 存内计算(IMC):打破存储与计算分离的传统架构,直接在存储单元内部完成矩阵运算,从根源省去数据跨模块搬运的功耗与时延;
- 芯粒(Chiplet)模块化架构:摒弃超大尺寸单片裸片设计,把复杂处理器拆分为多个功能独立芯粒,再通过先进封装集成整合成一颗芯片。算力核心芯粒采用3nm先进制程,IO与模拟外设选用5nm成熟工艺,既能压缩制造成本、提升芯片良率,又可灵活按需拓展算力,成为未来车载AI芯片的主流设计路线。
结语
在车辆本地部署高阶智能驾驶系统,是当下电子产业难度最高的工程课题之一。严苛的安全规范、确定性时延约束、受限的散热功耗,决定了单靠软件算法优化无法填平性能缺口,全链路底层硅片创新不可或缺。
通过整套边缘AI半导体优化方案:专用NPU硬件+革新内存架构+软硬件协同压缩,芯片厂商得以打造高能效车载算力芯片,大幅削减数据传输开销、破解散热瓶颈,在固定功耗上限内拉满芯片运算吞吐。
展望未来,随着自动驾驶算法持续迭代升级,软硬件协同优化仍将是行业主流方向;存内计算、芯粒等新技术落地成熟后,会进一步驱动车载边缘硬件革新,为全场景落地下一代自动驾驶铺平硬件道路。
本文转自媒体报道或网络平台,系作者个人立场或观点。我方转载仅为分享,不代表我方赞成或认同。若来源标注错误或侵犯了您的合法权益,请及时联系客服,我们作为中立的平台服务者将及时更正、删除或依法处理。




联系电话:
010-61853490
新闻投稿:
server@icviews.cn
商务合作:
business@icviews.cn
问题反馈:
19800315212(微信同号)


半导纵横公众号

半导纵横小程序