闪存进入堆叠高带宽新时代
现代AI模型推理需要海量参数,调度这些参数至运算位置既耗时又耗能。一项全新高带宽闪存标准化方案提出新思路:把模型参数就近存放,与GPU封装在同一封装内。
闪存素来具备大容量、无需刷新数据的特性,但性能始终难以适配高速计算场景。为解决这一痛点,Sandisk提出16颗存储裸片+基底裸片的闪存堆叠方案,整体尺寸与HBM保持一致,仅接口协议不同,这项新技术被命名为高带宽闪存(HBF)。
Synopsys应用工程执行董事Xi-Wei Lin表示:“HBF由Sandisk于2025年发布,旨在将闪存应用于高带宽、大容量内存场景,主打面向AI推理应用。”该技术有望把所有模型参数就近存放在GPU旁,无需传出封装外;同时通过读取速度优化,实现参数快速调取。
Rambus院士、杰出发明家Steven Woo称:“系统设计人员一直在寻求优化数据存储与访问的方案,例如在DRAM与传统NAND之间搭建全新内存层级,HBF因此备受行业关注。”
目前Sandisk正携手SK海力士,将这项技术提交至开放计算项目(OCP)推进标准化。Steven Woo透露:“Sandisk计划2026年下半年推出HBF工程样品,搭载HBF的首款推理设备预计2027年初出样。”
远端调取模型权重的行业痛点
AI运算涉及海量数据,大致可分为两类:一类是AI模型输入数据,以及每一层运算产生的中间结果。这类数据属于动态数据,外部输入实时产生,需要随时存储、调取,行业统称激活值。另一类是代表模型本身的权重(参数)。推理过程中这类数据固定不变,理论上可直接置入GPU或其他处理器内部常驻。但现实难题是模型参数量过于庞大,远超单颗处理芯片的容纳上限。
存内计算(IMC/CIM)技术利用非易失性存储阵列稍加改造,即可高效实现向量乘法运算。其核心思路是:一次性载入权重,便可反复运行模型,全程只需调度激活值数据。但单颗芯片存储容量存在上限,且现有存内计算方案仍无法适配当下大语言模型,根本原因就是参数量规模过大。这也印证了:大模型所需内存容量,早已超出单颗芯片、尤其是处理器芯片的承载能力。
处理器就近存储权重方案
海量模型权重该如何存放?对于超大模型而言,容量最大的非易失性存储方案,是机架式SSD。从算力调度视角来看,这已是机架范围内物理距离最远的存储形态;若存放在更远的网络附属存储设备中,时延挑战会更为严峻。
由此形成三层缓存架构:非易失性存储:承担长期数据存储;待使用权重从存储读出,缓存至DRAM(含HBM);权重调入处理器后,进一步缓存至SRAM。
这意味着权重首次调取时延极高,需历经存储→DRAM→SRAM全链路。即便完成缓存后访问速度提升,也无法全部纳入缓存;一旦被替换出局、后续再次需要,仍要重复完整传输链路。
HBF的设计思路与HBM一脉相承:高IO非易失性存储裸片堆叠,与处理器共封装。相比HBM,HBF价值更突出:普通DRAM内存距SSD物理距离更远,而HBM仅优化了DRAM访问时延;HBF则可让权重完全绕过DRAM层级,不过也会增加缓存架构设计复杂度。
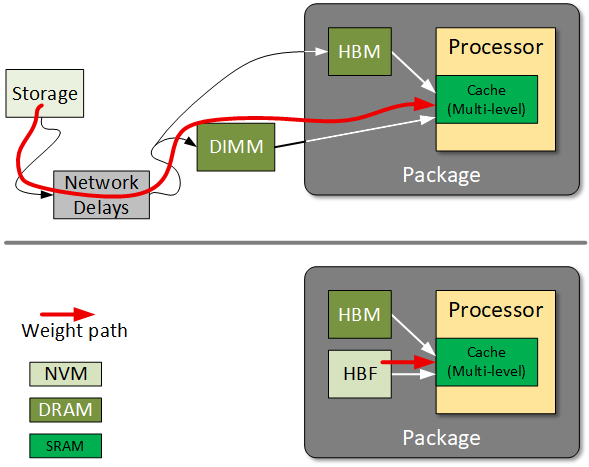
图1 HBF在AI架构中的定位:实现模型权重封装内存储,无需远端网络调取
Expedera首席科学家联合创始人Sharad Chole表示:“HBF填补了高带宽访问与大容量存储之间的架构空白。将这类闪存堆叠直接接入AI加速器,可像当前访问DDR内存一样便捷调用存储资源。未来设计将得以简化,存储不再受限于PCIe的速率与时延瓶颈。”
在该架构下,HBM仅用于存放运算过程中生成的动态变量(激活值),不再承载预存权重数据。
联电先进封装总监Pax Wang解释:“我们从HBF存储载入模型权重,在DRAM中完成运算上下文处理。”
闪存技术固有挑战
闪存最大优势在于容量。Rambus的Steven Woo表示:“HBF基于NAND架构设计,在保持与HBM同等读取带宽、同等成本的前提下,容量可达HBM的8~16倍。”
容量优势远超现有HBM产品。Siemens EDA内存研究总监Jongsin Yun指出:“最新HBM堆叠单栈最高容量192GB,下一代产品目标约400GB;而HBF单栈容量已可达3Tb。”
但闪存的短板在速度,尤其是写入速度。闪存写入受多重物理机制制约:为避免存储单元过编程,写入前必须先执行擦除;闪存采用块架构以缩减裸片面积,哪怕仅改写块内1比特数据,也需擦除整块;写入本身的物理过程耗时较长;被擦除的整块数据还需重新写入。
尽管闪存性能可渐进优化,但写入性能的先天短板无法彻底规避。这也决定HBF无法完全替代HBM——系统仍需要具备高速写入能力的内存,而现行架构下闪存难以满足这一需求。
Objective Analysis内存分析师Jim Handy表示:“闪存设计初衷就是极致压缩成本,为此牺牲了部分速度性能。闪存性能损耗主要集中在写入周期,受量子物理机制制约无法规避;但读取性能具备进一步提升空间。”
定位推理场景,不适用模型训练
受写入速度限制,HBF仅适配推理芯片这类权重固定不变的场景。Jim Handy称:“HBF定位AI推理而非模型训练。训练过程需要持续迭代更新权重,而推理阶段权重全程固定。”
Sandisk进一步优化闪存读取通路,在保持堆叠内各裸片完整单片架构的同时,进一步降低权重调取时延。Sandisk闪存设计高级总监Cynthia Hsu解释:“高带宽闪存(HBF)不只是接口与形态升级,更重构了内部读取通路,更智能地利用多阵列并行架构,依托NAND、控制器、固件系统性协同设计,实现更低有效时延、更稳定带宽的数据访问。”
闪存还有一大短板:擦写寿命有限,达到写入次数上限后单元会失效。目前HBF的耐久度指标尚未明确。Jongsin Yun表示:“普通闪存产品擦写寿命约万次级别,少数高端产品可达十万次,整体仍停留在数千至万次区间。”
行业还有MRAM、RRAM等其他非易失性存储技术,但均未成熟落地。MRAM进展相对领先,却存在固有取舍:存储单元只能偏向速度优化或数据留存优化,无法兼顾,难以同时满足大容量存储与低时延访问。虽可寻求折中方案,但NAND闪存技术成熟度遥遥领先,仍是当下最优选择。
RRAM历经多年研发仍差距明显。新型非易失性存储技术普遍面临起步难题:在无量产工艺积累的前提下,成本必须低于已高度成熟优化的闪存才有机会普及。即便推出高带宽版本(HBR),短期也难以在成本上形成竞争力;若初期无法放量,便无法通过工艺迭代持续降本。
Sandisk并未选择这类新型存储单元路线。Cynthia Hsu表示:“我们长期调研过各类非易失性存储技术,而高带宽闪存(HBF)立足NAND的固有优势——高集成密度、可扩展性与成本优势,基于当前成熟可用的技术底座重新架构设计,满足AI系统所需的高带宽需求。”
规格参数与量产规划
HBF单裸片容量256GB,16层堆叠版本单栈可达512GB,读取带宽1.6TB/s;整体尺寸、功耗、堆叠高度与HBM4完全对标。
Sandisk计划今年下半年推出样品,2027年落地商用系统,并公布三代技术迭代路线:

Sandisk长期深耕多形态非易失性存储领域,此次与同时布局非易失性存储、多品类DRAM的SK海力士达成合作,联合在OCP推动标准化进程。Xi-Wei Lin表示:“HBF无法直接替代HBM实现即插即用,二者接口不同,必须建立行业标准才能规模化普及。目前Sandisk与SK海力士已签署合作备忘录,后续还需时间吸引更多厂商加入共建生态。”
内存标准多由JEDEC制定,HBF选择OCP推进标准化略显意外。Sandisk的Cynthia Hsu解释:“标准化封闭工作组阶段选择OCP,因其目标导向性更强,可实时迭代规范版本,适配AI行业快速创新的节奏。”
HBM4支持定制基底裸片,被问及HBF是否会跟进这一设计时,Cynthia Hsu回应:“标准是加速技术落地的关键,可保障兼容性、可扩展性与生态协同路径。对于HBF这类新兴技术,全行业共建统一规范,是推动软硬件及系统生态对齐落地的核心,这也是我们当前的工作重点。”
目前暂无定制基底裸片规划,但未来不排除落地可能。
价值意义
HBF应用场景与定位十分明确,看似只为单一场景量身打造,但回顾HBM发展历程,初期同样场景受限,如今已证明自身核心价值。HBF适用的业务负载场景相对集中,主要聚焦AI推理,但这一赛道市场空间极为庞大,未来需求还会持续增长,AI模型权重的存储刚需将长期存在。
归根结底,HBF为芯片架构设计提供了全新选择。Sharad Chole表示:“我们认为HBF将重塑数据中心AI加速器的设计思路,为架构师开辟前所未有的设计维度。”
本文转自媒体报道或网络平台,系作者个人立场或观点。我方转载仅为分享,不代表我方赞成或认同。若来源标注错误或侵犯了您的合法权益,请及时联系客服,我们作为中立的平台服务者将及时更正、删除或依法处理。




联系电话:
010-61853490
新闻投稿:
server@icviews.cn
商务合作:
business@icviews.cn
问题反馈:
19800315212(微信同号)


半导纵横公众号

半导纵横小程序