AI SoC与芯粒普及,NoC一致性挑战陡增
随着各类计算单元需要处理、存储和访问的数据量持续暴涨,数据的传输、调度与管理正变得愈发棘手。
复杂SoC与多裸片架构(尤其是AI相关芯片)内部,往往集成大量片上网络(NoC)来调度和优先处理数据流转。这些NoC有的支持缓存一致性、有的为非一致性架构,还包含各类输入输出接口;也有的仅负责系统某一物理分区的数据交互。但如今,所有这些网络架构都必须在设计流程更早阶段完成规划,并在整个系统生命周期中持续管控调优。
Arteris产品营销副总裁Andy Nightingale表示:“从各AISoC团队反馈来看,训练与推理任务不仅推高了数据体量,更让数据传输本身成为制约系统性能的核心瓶颈。算力的增长速度早已超越摩尔定律,但数据流转拥堵、传输能效问题,正越来越决定这些算力能否真正被有效利用。”
评估特定场景最优NoC架构,可从数据流量与缓存一致性两大维度切入。Nightingale称:“芯片架构师需要理清这些问题:谁需要一致性能力、原因是什么;哪些节点会产生突发流量、哪些为平稳持续流量;哪些场景对延迟约束极其敏感;后续衍生芯片与芯粒架构需要多大的复用和扩展空间。CPU集群通常必须搭配一致性NoC,因其编程模型高度依赖缓存一致;而NPU一般采用非一致性架构,通过显式数据搬运搭配本地内存,能获得更优功耗与吞吐性能。”
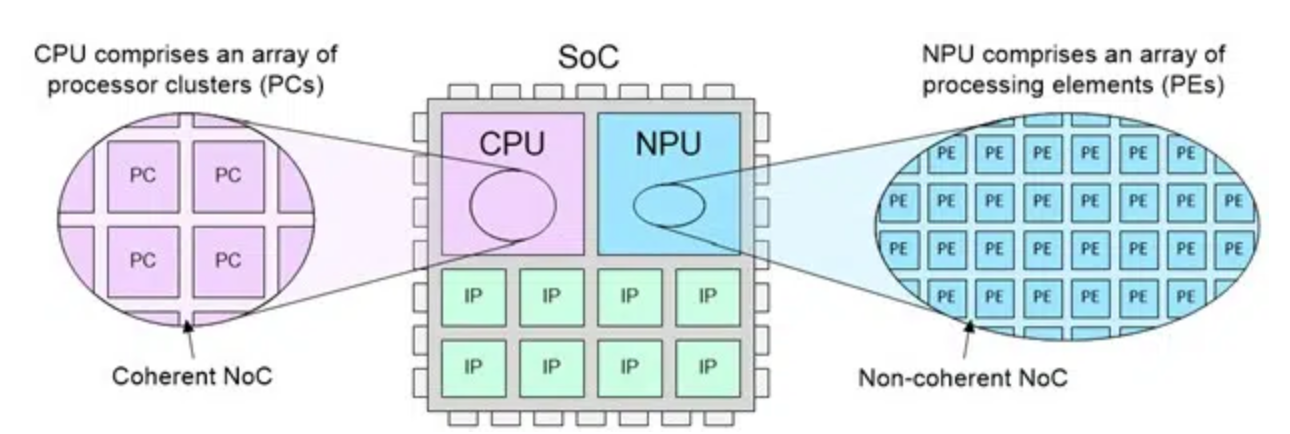
图1:CPU与NPU片上网络架构对比
业内其他人士也认同,缓存一致性是选型的首要出发点。ChipAgents首席执行官William Wang表示:“面向共享内存CPU集群、对数据一致性有强需求的场景,选用一致性NoC;面向NPU与硬件加速器、吞吐优先级高于严格一致性的场景,采用非一致性NoC更为合适。”
NoC分为多种架构类型:全缓存一致性、末级缓存一致性、I/O一致性(单向一致性)以及纯非一致性架构。
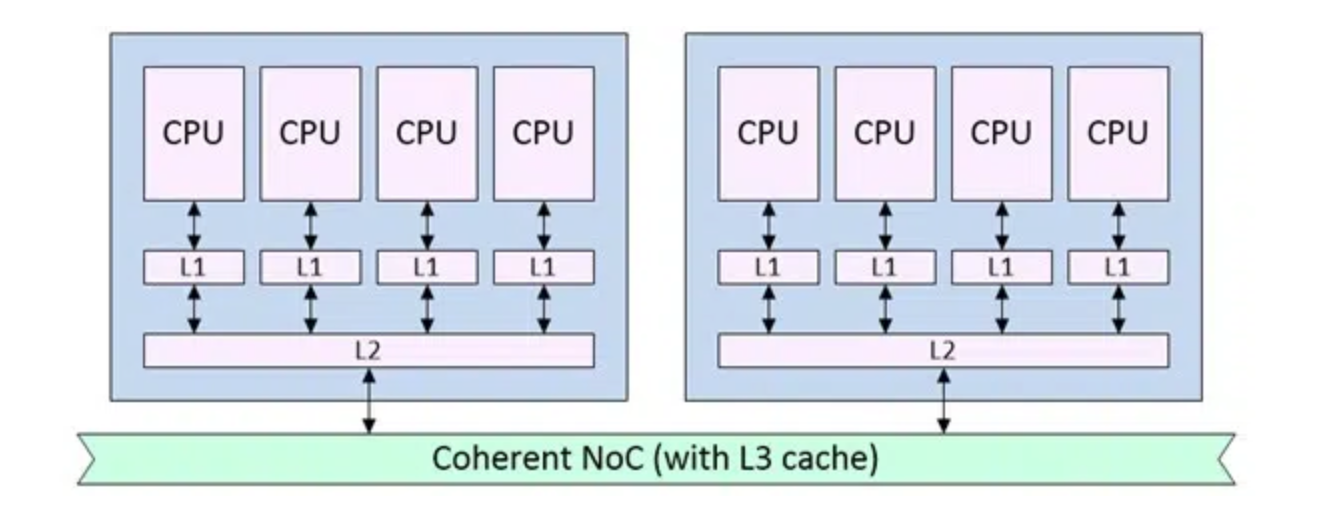
图2:一致性NoC典型部署案例
相比非一致性网络,一致性网络的设计成本与功耗开销通常更高。Baya Systems首席解决方案架构师Kent Orthner说:“行业普遍主流做法是:为搭载大容量缓存的高性能CPU搭建一致性互联域,同时尽量缩小一致性架构的覆盖范围。理想状态下,仅在内存、CPU以及AI加速器之间保留一致性通路,系统其余部分采用简单的普通读写协议即可。这类简易协议无需记录数据最新访问节点与归属权,只需直接访问内存、PCIe控制器等终端节点完成数据交互。SoC内部部署多NoC架构时,最常见的划分方式就是一致性域与非一致性域分离。”
过去大型芯片厂商大多自研结构相对简易的NoC。但随着数据流转复杂度飙升,行业已转向商用NoC IP方案。Synopsys战略项目与系统解决方案执行董事Frank Schirrmeister表示:“各家IP厂商的思路大同小异:基于用户输入需求,提供可配置的模块化NoC IP。用户只需定义所有流量源数量与类型,区分一致性、非一致性、缓存一致、仅I/O一致等类别,即可在配置环境中快速搭建NoC架构。工具可自动例化缓存、TLB(转译后备缓冲区)等组件,完成网络搭建。非一致性部分重点保障可实现性,结合版图布局评估时序、模块位置。如今动辄数十亿门级的超大规模芯片,模块布局规划、数据通路布线难度极大,架构挑战十分突出。”
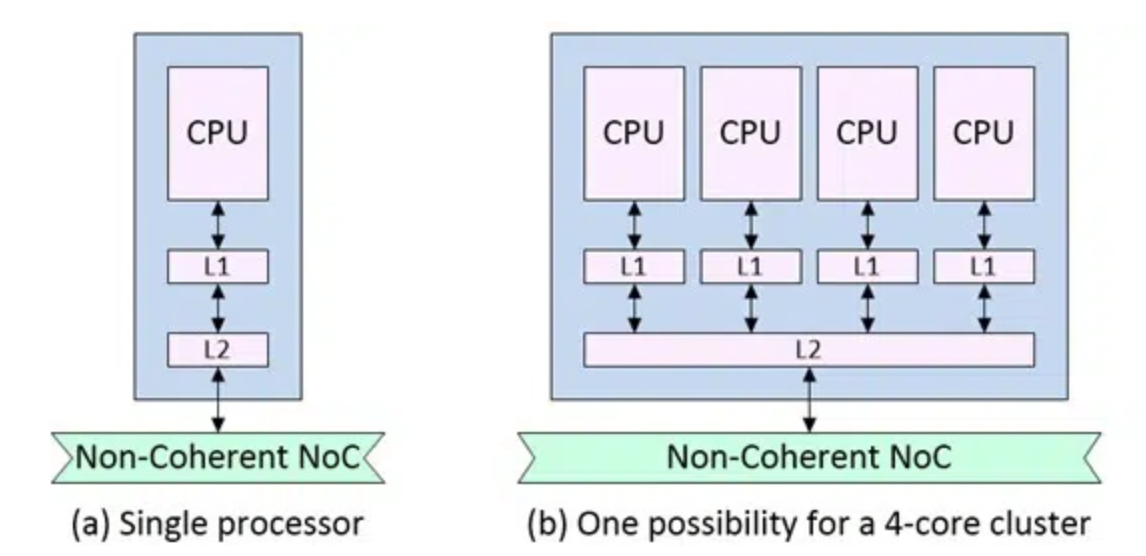
图3:非一致性NoC典型部署案例
缓存一致性的设计难度远高于I/O一致性。Schirrmeister解释:“I/O一致性的设计空间相对宽松,通常是GPU、网卡等外设读取CPU缓存数据,反向无需同步。而缓存一致性需要保证多核CPU共享内存视图完全统一,交互组合场景更多,逻辑复杂度大幅提升。”
缓存的作用是在处理器近邻位置临时存放数据。Orthner介绍:“处理器无需每次都访问外部内存(动辄百纳秒延迟),借助缓存就能快速读取数据。但超大型系统中往往包含成百上千个处理器核心,共享内存场景下,若某核心读取数据时,不知道其他核心已在本地缓存存有副本,就可能读到错误数值。缓存一致性的核心,就是确保所有处理器看到的数据缓存视图完全一致。”
事实上,每颗计算核心都拥有私有数据缓存。必须实时记录各核心的数据占用状态,并实现高效数据共享,这正是缓存一致性协议的设计初衷。一款集成500个处理器的SoC,在流片前就已完成所有核心的互联拓扑与通信规则定义。
芯粒、多裸片与3D堆叠架构
多裸片封装架构,需要对一致性与非一致性NoC做额外的分层管理。Cadence芯粒与IP解决方案资深产品营销总监Mick Posner表示:“我们的物理AI芯粒平台最少由三颗芯粒组成:中间为系统芯粒,一侧是CPU芯粒,另一侧为AI加速器芯粒。这是基础标配架构。中间系统芯粒必须同时具备一致性与非一致性接口:和CPU互联需保持缓存一致,承担内存管理职责;而与AI加速器之间仅需I/O一致性,无需缓存一致。加速器可自带本地内存,也可共享系统内存,但不需要全局缓存同步机制。”
这类架构必须部署多套独立NoC。Posner称:“面向一致性设计的NoC,硬件开销远高于非一致性网络。不同网络之间虽可互联,但默认采用非一致性链路,因为其中一侧本身不具备一致性能力。”
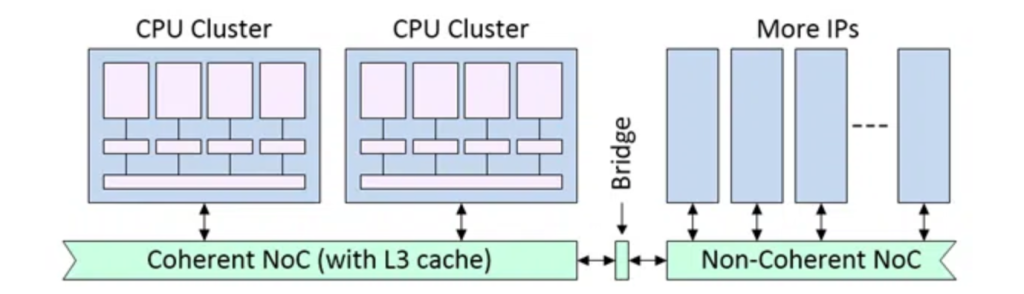
图4:SoC可同时集成一致性与非一致性多套NoC
一致性、可编程性与集成度的平衡
多裸片架构下的数据流转调度,对网络可编程性与系统拓扑自发现能力提出了更高要求。
NoC可帮助封装内各芯粒实现相互识别与拓扑发现。Baya的Orthner表示:“同一颗裸片的芯粒,既可以单独封装,也可以与另外四颗芯粒阵列封装,还能垂直堆叠异构封装。这就带来一个关键问题:上电初始化时,芯粒如何互相识别、确认自身在封装中的拓扑位置、定位其他芯粒。这要求NoC具备极高的可编程配置能力。”
系统上电后需要管理控制单元介入调度。Orthner解释:“管控单元会自动分配流量路由规则,例如指定某类业务流量北向传输、北向芯粒则反向南向转发。系统完成上电唤醒、拓扑发现后,会重新配置网络路由,让不同芯粒可访问同一目标地址、却走不同最优通路。”
裸片堆叠架构进一步增加了网络设计难度。Keysight EDA高速数字设计负责人Hee Soo Lee指出:“异构厂商裸片集成,需要解决器件兼容与系统融合适配难题,让网络与I/O设计愈发复杂。堆叠架构下,散热与机械应力问题的优先级,甚至高于电气互联设计。所有需求都由市场驱动,尤其是数据中心AI负载对数据吞吐的持续激增需求。”
面向PPA的架构优化
无论一致性还是非一致性架构,多NoC设计都应采用自上而下的芯片设计思路。Cadence的Posner认为:“顶层部署两套主干NoC,负责连接所有子系统;下层再部署本地化NoC。甚至可细分多套专用网络:低带宽外设独立一套、高带宽高速外设单独一套。需根据互联对象定制NoC架构,针对性做功耗、性能、面积(PPA)优化。同时要理清网络层级关系,实现全局统一管控。”
AI赋能的EDA技术,正在辅助设计者做PPA取舍权衡。ChipAgents的Wang表示:“EDA工具正朝着全自主多智能体工作流系统演进,可从规格定义到流片全程推理优化,实时反馈设计质量、完成PPA调优与跨领域协同设计。”
大型高端SoC通常会设计多套独立网络配置。Baya的Orthner说:“配置管理网络需要与一致性、主数据通路物理隔离,自身吞吐需求很低,属于控制平面。主要用于寄存器读写、系统性能监控、功耗域上下电管理。协议可复用数据通路标准,但规模更小、带宽占用极低,避免挤占主业务流量。”
芯片地理分区与拓扑差异,也催生了多NoC部署需求。例如芯片西侧为一组计算核阵列、东侧为另一组,两类核心无互通需求,可分别部署西域、东域独立网络,再增设一套全局网络完成跨域互联。
内存架构演进也倒逼网络设计革新,支撑高性能系统落地。Orthner举例:“即便物理位置相邻,也可将内存对半拆分,分别划归偶数网络、奇数网络,成倍提升系统并发数据吞吐,避免通路冲突。逻辑网络划分方式十分灵活。芯片架构定义好NoC边界与面积后,物理设计团队需在限定区域内布局所有模块并收敛时序。若不同NoC采用分散工具、分散项目设计,会造成逻辑层级错乱、版图重叠,极大增加物理实现难度。”
多样的网络架构方案,凸显了现代芯片设计的复杂度,尤其物理约束与逻辑需求日渐分化。为应对挑战、保持设计效率,行业愈发倾向统一NoC解决方案,在单个项目中无缝集成多套异构NoC。
统一NoC软件平台,核心是实现多NoC项目全局管控,而非把所有数据流量汇聚到单一网络。Orthner解释:“统一网络的含义是:一套顶层设计、一个工程项目,统一规划路由器、逻辑通路、布线资源与物理布局;同时保留各子网络的独立性。可在逻辑上隔离一致性与非一致性流量,共享底层布线资源,实现面积与成本最优。只需一次工具运行,即可并行管理多套异构网络,在系统设计者管控下实现资源复用。”
随着芯片复杂度持续攀升,统一NoC架构向大型系统的延伸适配愈发重要。设计者还要打通NoC与上层基础设施,实现架构向数据中心层级的规模化扩展。
数据中心层级架构
从数据中心视角审视NoC,会衍生出一系列底层架构问题:机架之间如何通信?机架内板卡如何互联?板卡上多颗芯片如何交互?最终,芯粒之间的跨裸片通信如何实现?
理清这些问题,就能建立自上而下的数据中心层级视图,为多NoC架构划分层级依据。Baya Systems首席解决方案架构师Saurabh Gayen表示:“顶层视角从数据中心切入,整个数据中心可视为一台超级计算机。先要理清机架组织方式、横向与纵向流量流转逻辑,再逐层下沉到封装层级、芯粒层级。必须建立自上而下的层级规划,以此定义多NoC的架构分组与互联规则。”
零散松散的模块化拼接看似简单,却并非最优方案。Gayen称:“行业需要更高集成度、高密度、扁平化、高性能的紧耦合层级架构,不能无限制堆砌独立网络。传统数据中心粗放式架构已无法适配AI模型算力需求。如今行业已达成共识,主动扁平化架构、提升性能密度,适配AI大负载。”
这套层级化设计理念,同样适用于封装与芯粒内部架构。Gayen强调:“必须坚持自上而下规划,摒弃零散堆叠式的自下而上拼接思路。先定义整体系统架构,再拆解为子模块。同时要区分芯粒内部NoC与裸片间互联NoC的设计差异。性能规划自上而下落地,工程实现自下而上推进,需要在层级设计中做好双向平衡。”
数据高效管理的关键,在于子NoC的层级划分。Orthner表示:“芯片内部如何搭建子网络、网络之间如何互联、边界如何界定至关重要。从架构规划到物理版图晶体管布局,都要遵循预先设计的层级逻辑,最大限度降低后端实现工作量。层级化是NoC架构设计的首要核心考量。”
性能分析同样要立足全局顶层视角。Orthner认为:“不必局限于单一内存接口带宽,要从全局数据流切入:谁与谁需要通信、业务目的是什么、数据流转路径如何规划。实际系统往往多流量源并发,必须评估相互干扰与性能影响。”
总结
过去,NoC往往是芯片设计后期的补全环节,等到物理版图基本定型才着手设计。如今,设计者必须将NoC纳入开发早期流程,让互联架构与计算单元同步优化。这种设计思路可全面提升性能、功耗与可扩展性,助力复杂系统实现更优整体指标。
Arteris的Nightingale总结:“行业真正的变化,是设计优先级的重构。数据传输已与算力、内存并列,成为芯片三大核心设计维度。尤其从单裸片向芯粒、分布式架构演进过程中,头部团队都在架构早期投入布局,保障网络可视性、服务质量与长期可扩展性,不再把互联架构当成后期优化项。”
伴随系统架构持续迭代,行业必须优先构建完善、标准化的安全协议,从设计早期布局可扩展互联方案。供应链跨企业协作至关重要,保障芯粒与多裸片集成普及下的互联兼容性、可靠性与安全韧性。未来,持续技术研发、跨厂商生态合作、自适应网络拓扑落地,将成为满足下一代高性能、高安全数据传输需求的核心支撑。
本文转自媒体报道或网络平台,系作者个人立场或观点。我方转载仅为分享,不代表我方赞成或认同。若来源标注错误或侵犯了您的合法权益,请及时联系客服,我们作为中立的平台服务者将及时更正、删除或依法处理。




联系电话:
010-61853490
新闻投稿:
server@icviews.cn
商务合作:
business@icviews.cn
问题反馈:
19800315212(微信同号)


半导纵横公众号

半导纵横小程序