企业级GPU集群平均利用率仅为5%
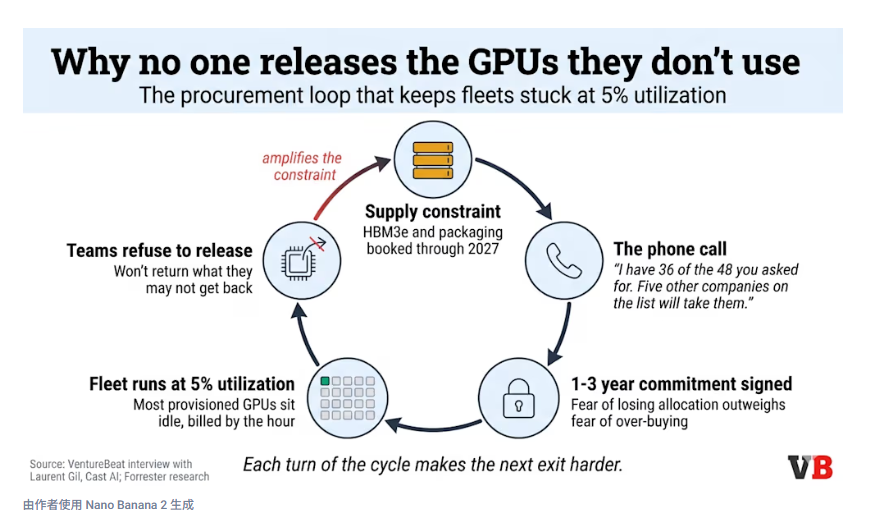
企业无法解决GPU浪费问题,因为任何解决方案都会使问题更加严重。释放闲置容量可以提高利用率,但正是由于GPU短缺推高了价格,才导致团队不愿意归还闲置容量。因此,GPU利用率仅为5%左右,按小时计费,而且这种模式还在不断恶化。
过去两年里,数千家企业都面临着同样的压力。根据Cast AI发布的《2026年Kubernetes优化现状报告》(该报告测量了实际生产集群,而非仅进行调查),正是这种压力导致大多数公司目前的GPU集群利用率仅为5%左右。这也是为什么没有人释放闲置容量的原因。Cast AI联合创始人兼总裁Laurent Gil已经追踪这一动态两年了。
5% 的效率比不采取任何措施的基准水平还要糟糕大约六倍。Gil认为,考虑到每日周期、周末和正常的业务模式,合理的人工管理目标应该在 30% 左右。5% 意味着企业运行其最昂贵的基础设施的成本仅为不采取任何措施所能达到的收益的一小部分。而与此同时,云计算定价也打破了其 20 年来的稳定模式。
此前,AWS悄然将其预留的H200 GPU价格上调了约15%,并未发布任何正式公告。内存供应商也宣布,2026年HBM3e的价格将上涨20%。这是自AWS于2006年推出EC2以来,超大规模云服务商首次大幅提高预留GPU的价格,而非像以往那样下调。目前,大多数企业AI预算中普遍存在的“云计算成本逐年下降”的假设,在云计算服务的最前端已不再成立。
云市场已经分裂成两部分
云计算已经分为两个层面。在商品层面,传统的通货紧缩机制依然有效。H100 按需定价已从2025 年 9 月的每 GPU 小时约 7.57 美元降至如今的约 3.93 美元,Lambda Labs 和 RunPod 等平台列出的 H100 价格低于 3 美元,而老款 A100 的价格约为 1.92 美元。曾经一机难求的英伟达 T4 芯片,如今在多个 AWS 区域中 24 小时的供货概率已超过 90%。
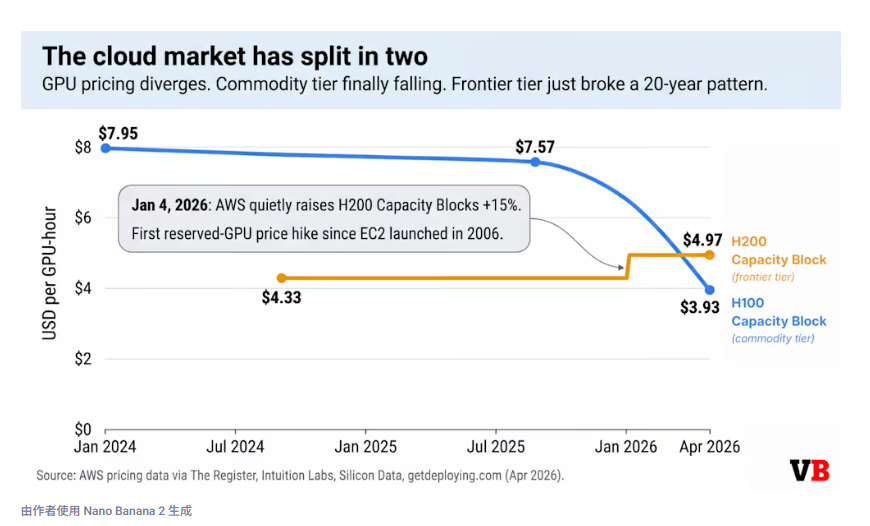
在前端芯片层,情况则截然相反。英伟达已收到2026年200万颗H200芯片的订单,而库存仅为70万颗。台积电的先进封装技术(用于封装所有配备HBM显存的GPU)的订单已排到至少2027年中期。AMD也警告称,由于同样的产能紧张,其2026年的价格也将上涨。即使是原本预计随着2023年起三年预订到期而有所回落的A100芯片,其价格也开始缓慢回升。Gill的解读是:FOMO(害怕错过)情绪如今蔓延到了老一代产品。企业工作负载位于哪一层决定了其面临的风险。
为什么是 5%?
第一部分:采购流程
GPU价格如此昂贵,为什么显卡利用率只有5%?Gill对企业GPU采购的解释是我听过的最清晰的。
一家企业需要GPU。它加入了超大规模数据中心的等候名单。几周甚至几个月过去了,杳无音讯。然后接到一个电话:“你们要了48个,我这里只有36个。如果你们想要的话,可以拿走,但必须签订一年或三年的合约,三年合约更划算。如果你们不要,名单上的其他五家公司会要的。” 失去配额的担忧十分强烈。于是签署了合约。此时,工作负载是否真的需要这么多GPU,或者这一代芯片是否适合运行在它们上面的应用,都不是关键问题。关键问题是:是答应下来,还是会失去这个配额?
一旦这些GPU被锁定,释放它们就变得极其麻烦。重新获取它们需要数月时间,而且没有人愿意成为那个释放了容量却无法再次获取的团队。因此,这些GPU就只能闲置,按小时计费,无论是否使用。Gill描述了企业按需付费的模式,这种模式的价格大约是预订一年价格的三倍,因为即使价格更高,企业也觉得释放它们比冒险要安全得多。
这就是5%这个数字背后的悖论。提高利用率最直接的方法是释放那些闲置的GPU。但正是由于GPU短缺导致价格高昂,也正是因为如此,才没有人愿意释放它们。于是,GPU资源持续过剩,短缺持续存在,价格上涨,而引发这个循环的FOMO(害怕错过)情绪也随之加剧。循环的每一次都让下一次退出更加困难。
Forrester 的数据从另一个角度证实了这种动态。首席分析师 Tracy Woo 发现,从业者自我估计的 Kubernetes 资源浪费率约为 60%,与 Cast AI 直接测量的结果接近。Kubernetes 实践中普遍存在的一种模式解释了这种动态:工程师通常会申请实际使用资源的五到十倍,因为资源不足的成本是显而易见的(会发出警报),而资源过度配置的成本是隐蔽的(云账单上会出现一笔工程师看不到的费用)。
第二部分:架构循环
单靠采购环节的改进无法使数量达到理想水平,因为企业目前拥有的GPU在内部也存在浪费。而架构方面的问题,则由与Cast AI竞争的团队进行独立诊断。
Ray框架背后的公司Anyscale于1月21日发布了一份分析报告,指出由于工作负载的容器化方式,即使集群规模恰到好处,现代AI工作负载的GPU利用率也常常低于50%。一个AI作业会经历CPU密集型阶段(数据加载、预处理)、GPU密集型阶段(训练或推理),然后再返回CPU。当所有这些操作都在同一个容器中运行时,GPU虽然在整个生命周期内都被分配,但只有一小部分时间真正用于执行有效工作。
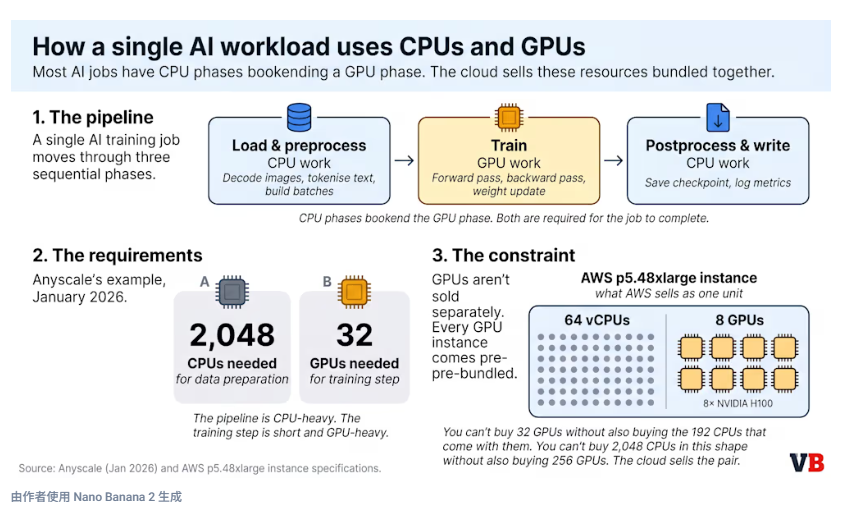
Gartner 也独立得出了相同的结论。在其 2025 年 11 月发布的关于本地部署 AI 基础设施的研究报告中,Gartner 建议将跨孤立项目的共享 GPU 使用与解耦推理相结合,即提示处理和令牌生成在不同的硬件上运行。Nvidia 上个月发布的 Dynamo 推理框架(用于 MLPerf Inference v6.0)也基于相同的原理。
两家供应商和一家独立分析公司(Cast AI、Anyscale、Gartner)得出相同诊断,比任何一家供应商的说法都更有说服力,尤其当其中一家是竞争对手时。这两种浪费会叠加。如果采购时资源分配过高,运行的工作负载容器导致 GPU 闲置等待 CPU 预处理,企业最终只能获得 5% 的资源。如果只解决其中一个问题而不解决另一个,大部分潜在的节省就无法实现。
40% 的利用率实际需要什么?
如果由于害怕错过机会(FOMO)而导致GPU发布受阻,且采购合同已经签订,那么唯一剩下的办法就是让已签约的GPU发挥更大的作用。这才是“提高利用率”在实践中的真正含义,而且这一切都不需要购买任何厂商的产品。
最简单的存在性证明其实是最古老的技术:跨时区GPU共享。一家银行的信贷决策引擎服务于亚洲和美国客户,它可以运行一个GPU池,在不同时间段服务于这两个市场。英伟达多年前就发布了MIG(多实例GPU)和时间片轮转技术。大多数企业不会手动实现,因为这在操作上既繁琐又会带来不必要的协调开销。而自动化调度器可以轻松完成这项工作。
澳大利亚设计平台 Canva 运行着 100 多个生产级 AI 模型,该公司告诉 Anyscale,在分布式训练运行期间,其 GPU 利用率接近100% ,云成本比之前的配置降低了约 50%。Cast AI 自身的数据显示,一个由 136 个 H200 GPU 组成的集群,在应用 GPU 共享、打包(将多个工作负载分配到更少、大小合适的节点上)以及竞价型/按需型混合模式后,平均利用率达到了 49%。这比集群平均利用率高出十倍,但尚未达到饱和。说实话,大多数实际企业集群在完全优化的情况下,混合了开发、测试和生产工作负载,其利用率可能在 40% 到 70% 之间,而不是 100%。即便如此,也比 5% 的利用率高出一个数量级。
需要注意的是:报告中提到的5%这一数字明确排除了专门用于人工智能训练的实验室。那些更像是前沿实验室而非混合型企业集群的组织,其利用率可能已经远高于此。
采购途径已不再可互换
2026年,企业究竟应该做出哪些改变?市场上的发展路径不再相同,每条路径都对供需走向做出不同的押注。
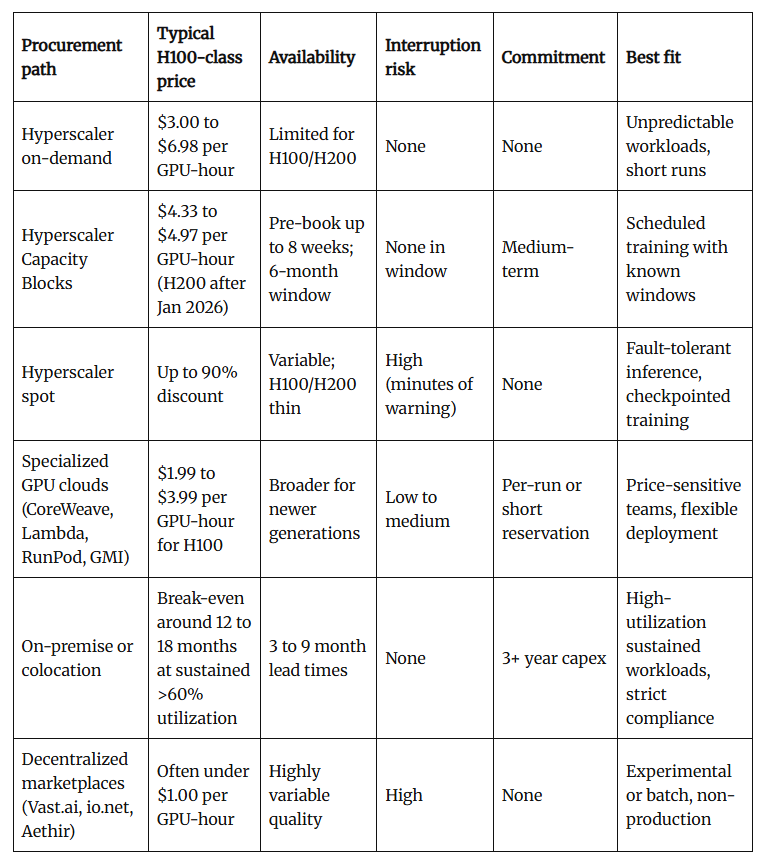
那种选择单一路径并锁定多年计划的模式已经不再奏效。更合理的2026年默认方案是混合使用不同的路径,避免出现资源分割:对于能够稳定运行的工作负载,选择通用型服务提供商;而对于需要保证服务窗口期的工作负载,则仅使用超大规模容量块。
今年大多数企业都没有问过的一个最实际的问题是:他们真的需要 H200 吗?
H200 专为超大型模型(700 亿以上参数)和超长上下文(12.8 万个标记)而设计,其 141 GB 的显存(几乎是 H100 的 80 GB 的两倍)使其能够轻松应对高负载而不降低性能。对于较小的模型、微调导数、量化推理以及大多数实际交付给客户的生产级 AI 应用,根据 Cast AI 的数据,H100 可以以大约低 40% 的 GPU 小时成本完成相同的工作。A100 通常也能胜任,成本大约低 60%。单一通用 GPU 作为默认解决方案的时代正在终结。芯片选择正从代际采购决策转变为针对具体工作负载的路由决策。
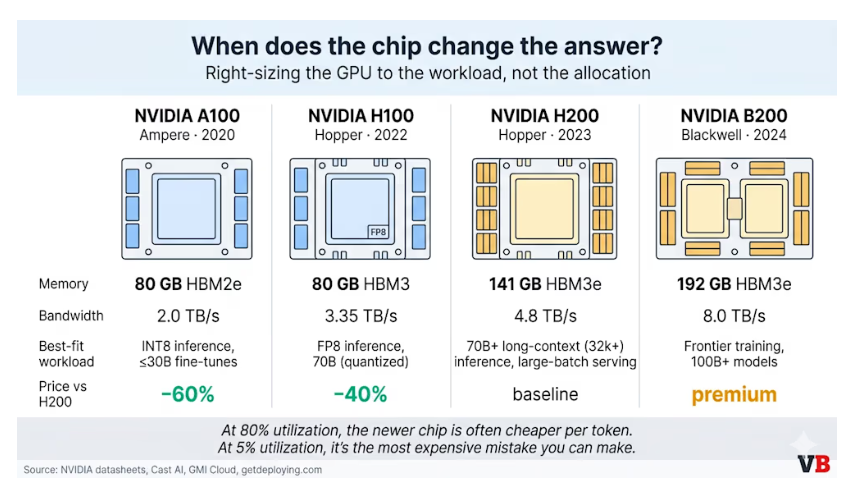
Gil 的观察更加印证了这一点。在 80% 的利用率下,B200 的单位代币成本确实比 A100 更低:其每小时性能更高,但每小时成本也更高。然而,当利用率降至 5% 时,情况就截然相反了。高端芯片反而加剧了资源浪费。购买最新芯片却未能充分利用,是 FOMO 循环中最昂贵的版本。
第一种方法是免费的,它是一种工作负载审计,而非软件采购。运行此方法无需释放任何GPU。生产环境中所有基于GPU的工作负载都值得根据一个问题进行审查:它所使用的芯片是否真正与其工作相匹配。令人惊讶的是,到2026年,相当一部分H200采购最终会被证明是因为分配成功,而不是因为工作负载本身需要它。因此,在投入更多预留容量之前,应该先修复运行时架构。在分配容量时,应该混合使用通用容量和预留容量,而不是只选择其中一种。
GPU 市场整体最终是否会重新平衡是另一个问题,不值得为此押上 2026 年的预算。供应可能会跟上,内存容量可能会缓解,专用推理芯片可能会分流 H200 系列的需求。所有这些都有可能发生,但没有一件事是确定的。可以肯定的是,采购和运行时问题本质上是同一个问题,只是体现在两个方面:FOMO(害怕错过)导致前端资源过度投入,而容器架构则让后端过度投入的资源闲置。如果企业将两者视为一个整体,就能打破这个循环;如果企业继续将它们视为两个独立的预算项目,则将继续以 5% 的成本运行其最昂贵的基础设施。
本文转自媒体报道或网络平台,系作者个人立场或观点。我方转载仅为分享,不代表我方赞成或认同。若来源标注错误或侵犯了您的合法权益,请及时联系客服,我们作为中立的平台服务者将及时更正、删除或依法处理。




联系电话:
010-61853490
新闻投稿:
server@icviews.cn
商务合作:
business@icviews.cn
问题反馈:
19800315212(微信同号)


半导纵横公众号

半导纵横小程序