传统制程缩放走到尽头,算力、内存、功耗、数据传输全面遇阻
人工智能的飞速崛起,正从根本上重塑计算架构。随着AI模型向万亿参数级别演进,传统的性能提升方式已难以为继。整个行业正迈入全新阶段,系统级创新、先进封装与3D集成成为推动技术进步的核心动力。这一变化折射出计算产业的深层转型:性能提升越来越取决于整套系统的设计与集成能力,而非单纯追求晶体管制程的微缩极限。
一维制程缩放时代落幕
AI算力需求呈指数级增长,使得实际所需性能与传统硅基制程缩放所能提供的性能之间差距持续拉大。要弥合这一差距,仅靠芯片内部创新已经不够。最关键的转变在于:AI性能如今由系统层面决定,而非仅仅由芯片硅基工艺决定。未来的性能提升,取决于能否将计算、内存、互联及供电系统高效集成为一个有机整体。行业正从以器件为中心的优化模式,转向全栈协同设计,覆盖从晶体管工艺一直到数据中心架构的全链条。
数据传输成为新的性能瓶颈
现代AI系统的核心约束已不再是计算能力,而是数据传输。跨芯片传输数据的能耗,最高可达芯片内部数据传输能耗的50倍。与此同时,数据传输占用了系统绝大部分运行资源,通信延迟大幅降低了加速器的实际利用率。这一趋势让互联效率成为设计的核心优先项。提升带宽、降低时延、压缩每比特数据传输能耗,已成为释放整机系统性能的关键。
内存墙问题日益严峻
随着AI模型持续扩容,内存需求的增长速度甚至超过了算力提升速度。长上下文处理、多模态AI等新兴负载,推动内存容量与带宽需求呈指数级攀升。系统内存配置正从GB级迈向TB级,同时对低时延的要求也愈发严苛。但内存技术的发展节奏跟不上算力迭代,供需失衡不断加剧。因此,突破内存墙是AI持续发展的必经之路,也倒逼高带宽内存与内存集成方案快速迭代创新。
功耗与散热约束愈发关键
计算密度不断提升,尤其是3D堆叠技术的普及,带来了功耗密度与发热量的同步激增,并迅速成为制约AI系统扩容的硬性瓶颈。若供电、能效与热管理技术无法取得重大突破,性能增长将难以为继。由此,功耗与散热不再是次要考量,而是系统设计与整机性能的核心环节。
3D架构集成技术:下一代AI的全新基石
为应对上述挑战,先进3D架构集成技术正成为下一代AI系统的底层支撑。这类技术可将多颗芯片与元器件集成为高效率、高性能的整体系统。3D芯片堆叠等创新方案大幅提升互联密度,缩短数据传输距离、降低能耗。先进封装平台可实现逻辑芯片与内存的近距离集成,支撑带宽与容量的大规模扩容。与此同时,高带宽内存持续迭代,吞吐能力与能效不断优化。多重技术叠加之下,封装不再只是配套工艺,而是决定系统性能的核心驱动力。
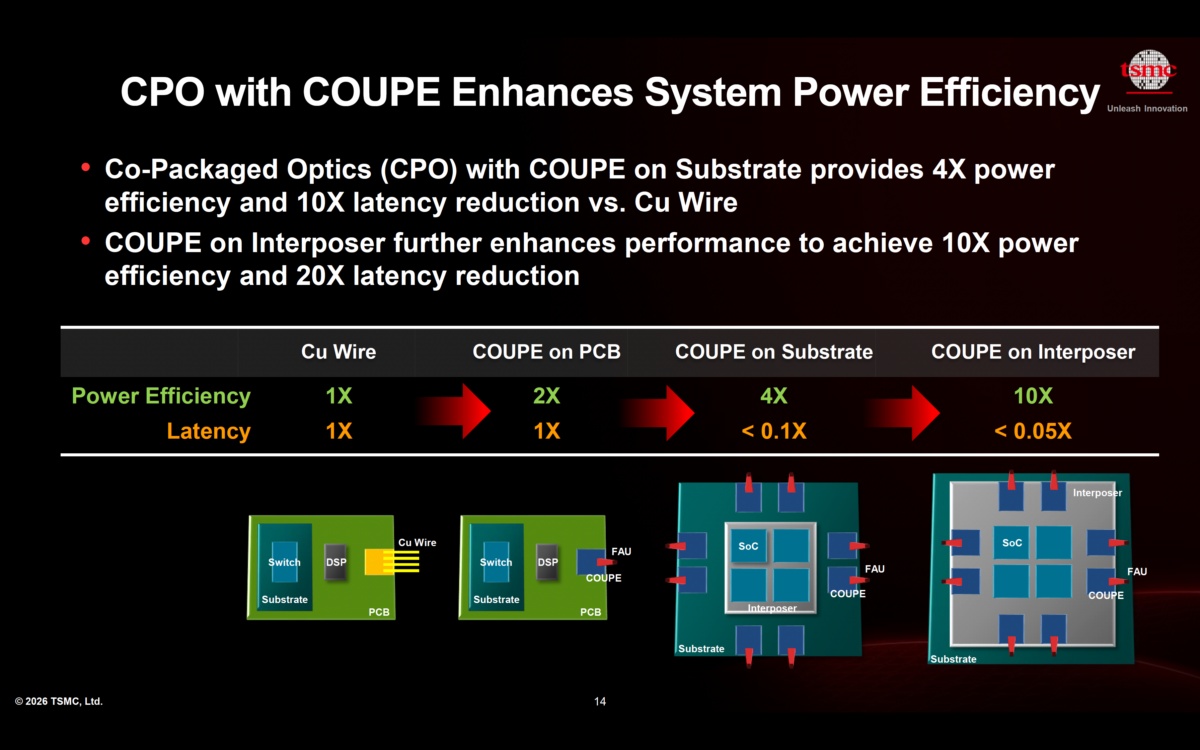
共封装光学:重构芯片互联范式
电互联技术已逼近物理极限,共封装光学(CPO)成为高速数据传输的优质解决方案。将光子器件与计算硬件直接集成,能够显著提升能效、降低传输时延,也为数据中心网络提供了可规模化的演进路径,行业对更高带宽、更低能耗的需求仍在持续增长。这一变革也标志着,光学技术正成为未来AI基础设施的重要支撑。
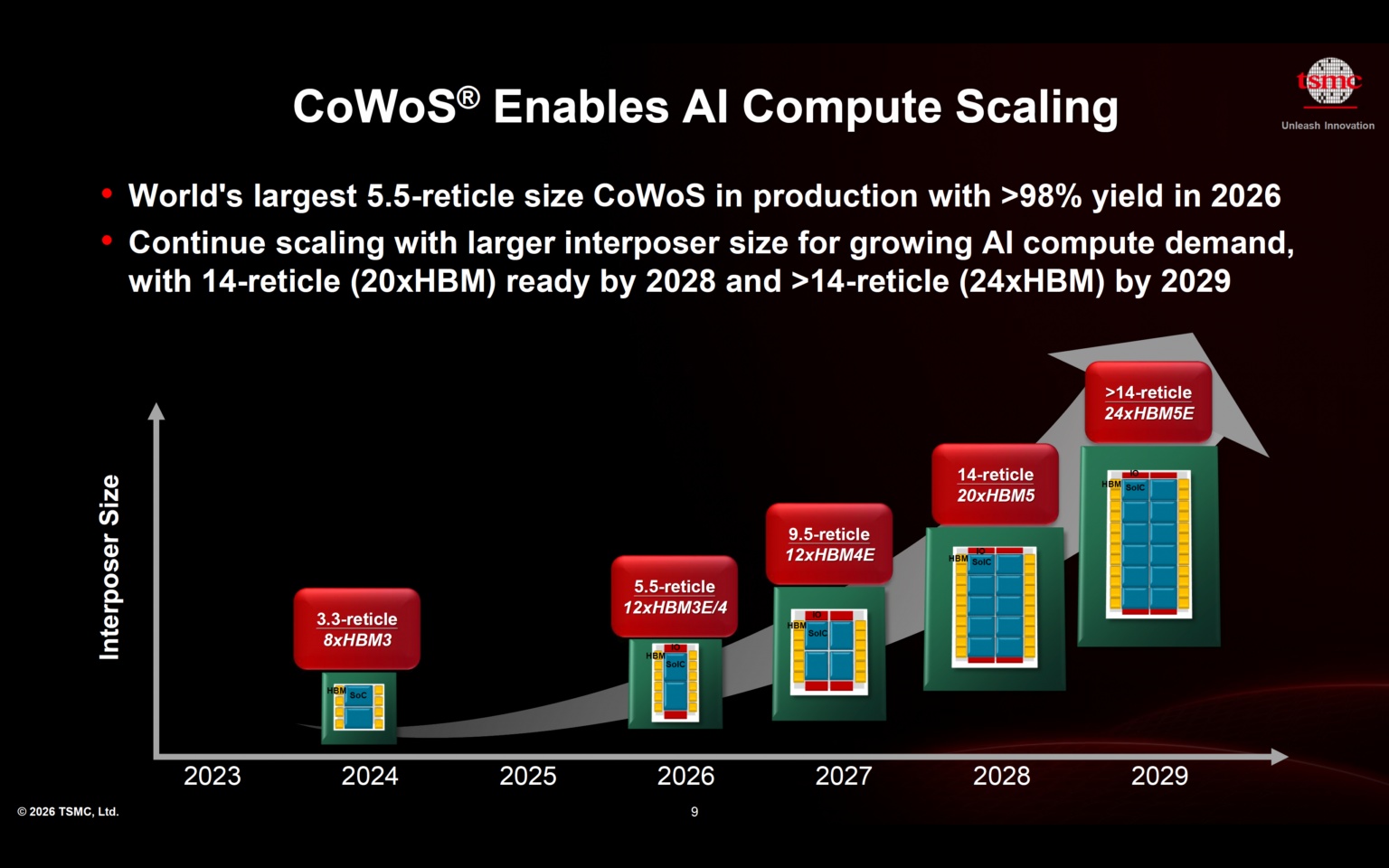
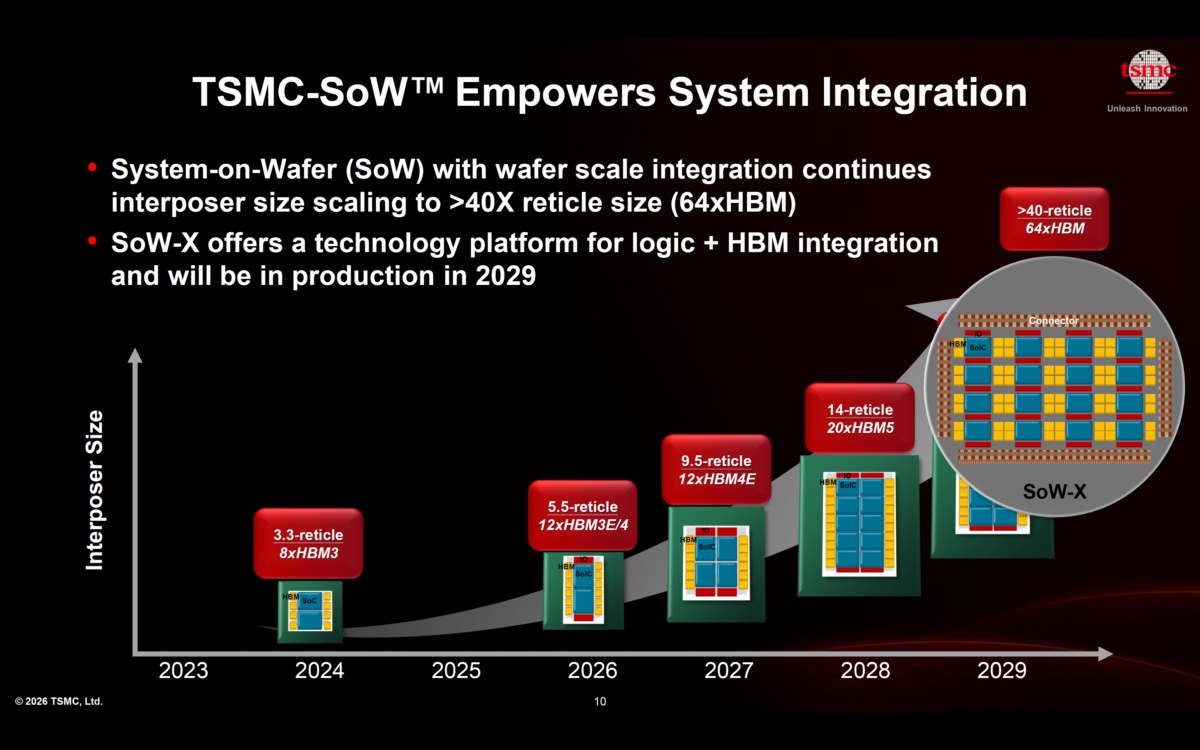
晶圆级系统与整片集成
放眼长远,系统集成正向晶圆级架构演进,在单一半导体基底上搭建完整系统。该模式实现了前所未有的集成密度,同时削减了传统互联带来的额外损耗。通过缩短通信距离、提升整体效率,晶圆级集成让AI性能突破传统封装的物理限制,开辟全新升级路径。
系统技术协同优化(STCO)兴起
AI系统复杂度持续提升,孤立优化单个元器件已无法满足需求。行业正普遍采用系统技术协同优化(STCO)思路,同步统筹芯片设计、封装、互联、供电与散热特性。这种全局设计方法能确保系统各模块高效协同工作,实现整机性能与能效双提升,也彻底改变了硬件系统的研发设计逻辑。
总结
AI硬件的未来,不再仅由硅基制程缩放定义,而是由封装、互联、内存架构与能效技术共同塑造,并通过系统级设计融为一体。在全新产业范式下,系统本身成为创新的核心单元。能否跨多领域深度集成、全局协同优化,决定着技术成败。伴随这场产业变革,“系统”实际上已经成为新一代芯片,重新定义了AI时代的性能增长逻辑。
本文转自媒体报道或网络平台,系作者个人立场或观点。我方转载仅为分享,不代表我方赞成或认同。若来源标注错误或侵犯了您的合法权益,请及时联系客服,我们作为中立的平台服务者将及时更正、删除或依法处理。




联系电话:
010-61853490
新闻投稿:
server@icviews.cn
商务合作:
business@icviews.cn
问题反馈:
19800315212(微信同号)


半导纵横公众号

半导纵横小程序