AI时代的 “内存饥渴”
“内存墙”(Memory Wall)最早是由弗吉尼亚大学的研究人员 William Wulf 和 Sally McKee 在 20 世纪 90 年代中期提出,二人共同撰写了题为《撞上内存墙:显而易见的启示》(Hitting the Memory Wall: Implications of the Obvious)的论文。该研究指出,由于处理器速度与DRAM架构性能之间的差距,导致了内存带宽成为关键瓶颈。
这一发现揭示了工程师在过去三十年来一直试图克服的根本性障碍。而随着AI、图形处理和高性能计算(HPC)的兴起,这一挑战的严峻程度进一步加剧。
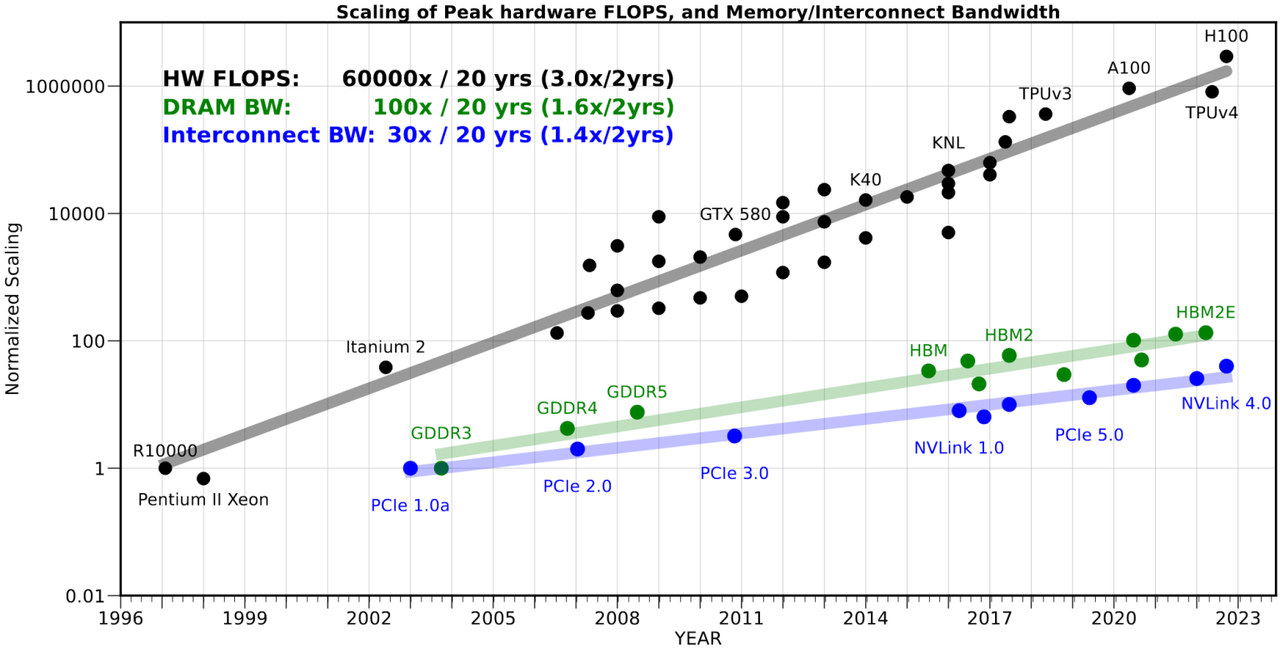
现代大型语言模型(LLM)的训练参数已超过万亿级,这需要持续的数据访问能力以及每秒 PB级的带宽。特别是新一代 LLM,无论是在训练还是快速推理阶段,都对内存带宽提出了极高的要求。而且这种增长势头没有放缓的迹象,预计 LLM 市场规模将从 2024 年的约 50 亿美元增长到 2033 年的 800 亿美元以上。CPU 与 GPU 性能、内存带宽及延迟之间日益扩大的差距已是不争的事实。
AI 训练面临的最大挑战在于如何在内存和处理器之间移动这些海量数据集,而在这一环节中,内存系统本身就是最大的瓶颈。随着计算性能的提升,内存架构必须不断演进和创新以跟上步伐。如今,高带宽内存(HBM)已成为应对 AI 和 HPC 等行业高要求应用的最高效解决方案。
内存架构的历史
20 世纪 40 年代,冯・诺依曼架构问世,成为了计算系统的基础。这种以控制为中心的设计将程序指令和数据存储在计算机内存中。CPU 按顺序获取指令和数据,这导致处理器在等待指令和数据从内存返回时会产生空闲时间。处理器的快速演进与内存相对缓慢的改进,最终造成了第一代系统内存瓶颈。

处理器与内存协同工作的基本架构
随着内存系统的演进,内存总线宽度和数据速率不断增加,实现了更高的内存带宽,从而缓解了这一瓶颈。21 世纪初,GPU和 HPC 的兴起加速了系统的计算能力,同时也给内存系统带来了新的压力,要求其必须与计算系统保持平衡。
这推动了新型 DRAM 的开发,其中包括优先考虑带宽的GDDR DRAM。在 21 世纪 00 年代至 10 年代 AI 和 HPC 应用成为主流之前,GDDR 一直是高性能内存的主导者。随后,业界需要一种新型 DRAM,即 HBM。
二十多年来内存的演进历程
HBM在AI领域的崛起
HBM 是满足 AI 最具挑战性工作负载需求的首选解决方案,英伟达、AMD、英特尔和谷歌等行业巨头均在其大规模 AI 训练和推理工作中采用了 HBM。与DDR或 GDDR DRAM 相比,HBM 在相似的 DRAM 占用空间内提供了更高的带宽和更好的能效。
它将垂直堆叠的 DRAM 芯片与宽数据通道相结合,并采用了一种新的物理实现方式:将处理器和内存共同封装在硅中介层上。这种硅中介层允许数千条线路将处理器连接到每个 HBM DRAM。
更宽的数据总线能够更高效地传输更多数据,从而提升带宽、降低延迟并提高能效。虽然这种新的物理实现方式增加了系统的复杂性和成本,但考虑到其带来的性能和能效提升,这种权衡通常是非常值得的。
JEDEC 于2025年4月发布的 HBM4 标准标志着 HBM 架构的关键飞跃。它通过将每个设备的独立通道数量增加一倍来提高带宽,进而在访问 DRAM 数据时提供了更大的灵活性。其物理实现方式保持不变,DRAM 和处理器仍封装在中介层上,与 HBM3 相比,该中介层允许更多线路传输数据。
尽管 HBM 内存系统的实施仍比其他 DRAM 技术更复杂、成本更高,但 HBM4 架构在容量和带宽之间取得了良好的平衡,为维持 AI 的快速增长提供了一条可行之路。
AI未来的内存需求
随着 LLM 以每年 30% 到 50% 的速度增长,内存技术将继续面临挑战,必须跟上行业在性能、容量和能效方面的需求。随着 AI 的不断演进并在边缘侧找到应用场景,受功耗限制的应用,例如高级 AI 智能体和多模态模型,将带来热管理、成本和硬件安全等新挑战。
AI 的未来将不仅取决于计算能力,同样也取决于内存创新。半导体行业有着悠久的创新历史,AI 带来的机遇为该行业在可预见的未来继续投资和创新提供了强有力的动力。
本文转自媒体报道或网络平台,系作者个人立场或观点。我方转载仅为分享,不代表我方赞成或认同。若来源标注错误或侵犯了您的合法权益,请及时联系客服,我们作为中立的平台服务者将及时更正、删除或依法处理。

联系电话:
010-61853490
新闻投稿:
server@icviews.cn
商务合作:
business@icviews.cn
问题反馈:
19800315212(微信同号)


半导纵横公众号

半导纵横小程序