HBM4不用等混合键合了
人们普遍预期下一代高带宽内存HBM4需要混合键合技术才能实现16层内存堆叠。JEDEC的一项举措使得这一代产品不再需要混合键合技术,但这仅仅是推迟,而非取消。
HBM内存因其在数据中心人工智能领域的高需求而备受青睐,尤其是在训练方面。数据传输是能源消耗的主要来源,而高带宽内存能够比标准DDR内存更快、更高效地处理更多数据。
“我们看到对内存的需求很多,无论是非易失性内存还是易失性内存,”联电高级封装总监王派表示,“但在人工智能时代,高带宽内存是最重要的。”
HBM技术将多个内存芯片堆叠在一起。“目前HBM堆叠层数为12层,正在向16层堆叠配置发展,”Brewer Science封装解决方案业务开发工程师Hamed Gholami Derami表示。可以通过增加堆叠层数和/或在每个芯片上增加存储单元数量来提高容量。
直到最近,JEDEC 还规定堆叠层数上限为 720µm,即使各种高度系数有所降低,这个高度仍然不足以容纳 16 层。“为了适应高度限制,芯片厚度正在不断减小(目前为 30 至 50μm),同时凸点高度、芯片间距和 TSV 间距也在减小,”Derami 表示。
TSV间距(水平尺寸)会影响芯片间厚度(垂直尺寸),这看似奇怪,但实际上它会影响凸点高度。“TSV间距和凸点高度直接相关,”Derami补充道,“间距越小,凸点也越小。”
同时,性能(以总带宽衡量)会随着接口宽度的增加以及每个引脚信号传输速度的提升而提高。HBM4 在拓宽接口的同时,通道数量也翻了一番。HBM4 的引脚信号传输速度也比 HBM3 快,但比 HBM3E 慢。
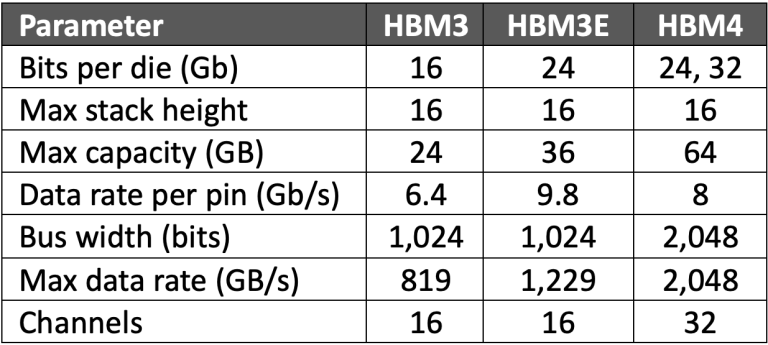
HBM4与HBM3和HBM3E的比较
更宽的接口带来了新的挑战,即需要在大致相同的空间内容纳更多的引脚。微凸点间距历来在 40µm 左右,但随着 HBM4 的出现,间距将接近 10µm。关键问题在于如何将芯片堆叠中的焊盘粘合在一起。
混合键合是计划中的解决方案
“目前,采用模塑底部填充的回流焊(MR)和使用非导电薄膜的热压键合(TCB)是主要的芯片堆叠组装方法,”日月光集团工程和技术推广总监 Vikas Gupta表示。
降低堆叠高度的预期解决方案是采用混合键合技术。即使每个芯片的厚度保持不变,由于没有微凸点,各层之间所需的空间也更小,从而缩短了堆叠高度。
yieldWerx首席执行官 Aftkhar Aslam 表示:“目前堆叠高度已超过 12 至 16 层,这得益于混合键合和晶圆减薄技术的进步。”
“随着 HBM 规格和性能要求不断突破互连和组装工艺的极限,混合键合提供了一种无凸点的 3D 堆叠组装方案,”日月光的 Gupta 表示。
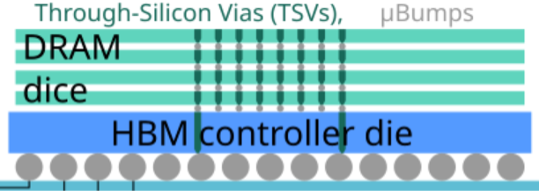
通用 HBM 结构。图中显示了微凸点。采用混合键合技术后,DRAM 芯片之间的间隙将消失。
混合键合是一种成本高昂的工艺,需要新的设备。率先采用该工艺的一代产品,其单封装成本会更高(尽管考虑到更高的容量,这可能不会转化为每比特成本的增加)。
该流程也给其他方面带来了挑战,例如测试。对于像包含十几个芯片的内存堆叠这样昂贵的单元来说,良率必须很高。任何一个芯片出现无法修复的缺陷都可能导致整个堆叠报废。因此,只组装已知合格的芯片是提高良率的重要途径。
联电的王派表示:“良率将是最大的问题。使用微凸点技术,我们可以在焊接微凸点之前测试存储层,但如果改用混合键合技术,测试流程将非常困难。”
键合前测试听起来似乎理所当然,但实际情况却因两方面原因而变得复杂。首先,混合键合需要焊盘表面洁净无瑕。测试探针可能会损坏焊盘或引入颗粒。此外,窄间距焊盘本身也带来了挑战。王派表示:“混合键合需要非常干净的表面,因为键合界面上不允许有任何颗粒物。而测试过程会产生颗粒物。”
为了实现这一目标,工程师必须有办法在测试后对焊盘表面进行修复。“我们的工艺流程包括在层间粘合之前进行中间测试——这是一个专门设计的工艺流程,”王派解释说。“我们在粘合前会使用表面平坦化技术来修复整体界面。”
第二个挑战是,代工厂通常习惯于将完整的芯片单元运送到OSAT(外包半导体组装和测试)工厂进行测试。但有些代工厂现在会自行组装芯片堆叠。因此,代工厂可能需要购置测试设备,以便在将芯片作为完整单元运送到OSAT工厂进行封装之前,先完成芯片堆叠的组装,而不是像以往那样先将芯片运送到OSAT工厂进行测试后再运回进行堆叠。
混合键合也给过程检测和监控带来了挑战。“材料创新——例如低翘曲基板、超平坦介电层和增强型底部填充配方——至关重要,但过程监控同样重要,”Aslam说道。“目前的检测技术包括光学干涉测量、声学显微镜和用于检测微孔和错位的在线空隙检测。在良率管理方面,相关工具能够进行垂直谱系分析,追溯堆叠中每个存储芯片的晶圆批次、老化历史和键合对准指标。通过将HBM堆叠中每一层的测试数据与组装和工艺计量数据关联起来,工程师可以隔离与混合键合对准、TSV电阻漂移或材料分层相关的缺陷,从而将传统的3D盲区转变为透明、可追溯的工艺窗口。”
高度调整提供了更大的空间
JEDEC将模块高度限制从 720µm 修改为 775µm,这为 HBM4 的微凸点键合提供了足够的空间。然而,HBM5 及其后续产品预计将采用混合键合技术。
王派表示:“混合键合技术可以减小焊料互连的厚度,因此已被列入HBM的发展路线图。但由于今年年初JEDEC标准的修订,我们看到混合键合技术的应用有所延迟。对于18层或20层堆叠结构——例如HBM4E——或许我们会看到混合键合技术开始获得发展动力。”
除了容量和带宽的提升,预计每比特能耗也将降低30%至40%,使HBM4比其前代产品效率更高——而且这还是在采用微凸块技术的情况下。“与目前的微凸块解决方案相比,混合键合技术的每比特能耗降低了一个数量级,”Gupta说道。
HBM4预计还会带来两项与逻辑相关的变化。第一项变化涉及堆栈的基础芯片(也称为逻辑芯片)。该芯片包含运行堆栈所需的所有逻辑,也是其他芯片上的内存控制器与之通信的基础。但到目前为止,该芯片基本都是标准化的,每个销售的单元都使用相同的芯片。
随着HBM4的推出,各公司预计将定制基础芯片,以便更好地使堆栈行为与特定应用相匹配。面向更广泛市场的标准版本应该会上市,但一些大型公司,例如AMD和Nvidia,计划在基础芯片中集成更多功能,并有可能将部分工作从处理器中转移出去。
Gupta表示:“定制芯片的特性将随着整体计算架构的发展而不断演进。这种演进将直接影响功耗、高效供电需求以及相关的散热管理。”
HBM4 还将包含一项旨在帮助抵御行锤攻击的新型内存功能。这项名为定向刷新管理 (DRFM) 的功能有助于刷新可能遭受行锤攻击的内存行。此外,HBM4 还将提升可靠性、可用性和可维护性 (RAS) 特性。
未来需要新的设备和材料
展望未来,我们将继续努力构建更高、更快的堆叠结构。但是,在缩小信号间距的同时减薄存储层厚度,必然需要更精密的设备和更好的材料。
“无论是 MR 还是 TCB 工艺,都需要更好、更精确的芯片放置工具,以及改进的芯片间键合和芯片与晶圆键合设备,”Derami 说。
即使采用混合键合技术,仍可能存在一些微凸块(MR)和热凸块(TCB)键合。“并非所有互连都会在HBM中采用混合键合,”Derami表示。“各公司正在探索一种解决方案,即DRAM芯片面对面进行混合键合,然后使用微凸块将这些键合对背靠背堆叠。这似乎是一种权宜之计,因为使用混合键合技术堆叠所有DRAM芯片存在困难,因此在这些集成方案中仍将使用热凸块和微凸块键合工具。”
晶圆减薄也带来了新的挑战。“随着HBM架构不断发展,包含更多存储层和更精细的互连,实现超薄芯片的均匀平面度和整个堆叠结构的耐热性(尤其是在混合键合方案中)变得越来越复杂,”Derami指出,这些材料需要具备热稳定性才能经受住加工过程。“我们需要使用具有更高导热性、热稳定性和更优异机械性能的先进材料,才能将芯片减薄到极薄的厚度,并保持器件的稳定性。”
HBM4E版本预计将于2027年左右投产,紧随HBM4预计于2026年投产之后。各公司已公布各自的目标,其中三星的目标是单引脚传输速度超过13 Gb/s,总带宽达到3.25 TB/s。能效也将得到提升。
限制混合键合技术应用的另一个因素是焊盘间距。现有技术适用于间距小至约 10 µm 的焊盘,因此在该间距下使用混合键合技术在经济上并不划算。HBM4 的焊盘间距为 10 µm,这也导致了混合键合技术的延迟。
新一代微凸点封装技术
虽然最初预计 HBM4 需要混合键合技术,但现在情况已有所不同。采用混合键合技术制造的芯片在价格上难以与采用微凸点封装的芯片竞争,因此后者将设定价格门槛,使更昂贵的组装工艺变得不经济。
HBM5是目前大规模采用混合绑定技术的必要阶段。它比HBM4晚几年上市,预计在本十年末期才能面世。堆叠层数预计至少保持在16层,接口容量翻倍至4096比特,带宽达到4TB/s。
这为存储器技术人员提供了一些喘息空间,让他们能够开发出此类高级存储器所需的复杂工艺。
本文转自媒体报道或网络平台,系作者个人立场或观点。我方转载仅为分享,不代表我方赞成或认同。若来源标注错误或侵犯了您的合法权益,请及时联系客服,我们作为中立的平台服务者将及时更正、删除或依法处理。



联系电话:
010-61853490
新闻投稿:
server@icviews.cn
商务合作:
business@icviews.cn
问题反馈:
19800315212(微信同号)


半导纵横公众号

半导纵横小程序