数据中心需要高可靠性半导体
英伟达首席执行官黄仁勋曾表示,“在设计汽车、飞机、人工智能工厂时,你必须做到完美,原因在于其中的风险太大了。”汽车和飞机需要极高的可靠性,因为如果不可靠,人们会丧命。在人工智能数据中心,系统故障虽然不会导致人员伤亡,但经济影响是巨大的。
数据中心可靠性标准与策略
云服务提供商在全球运营着数百个巨大的数据中心,通过数千英里的光纤连接。这些是世界上最大、最复杂的计算机。
谷歌数据中心分布情况
数据中心基础设施旨在实现极高的可靠性,并提供多种选择。例如,谷歌提供从99.9%的正常运行时间到 99.999%的正常运行时间不等的服务。笔记本电脑死机的频率都比这高。更高的可靠性是通过跨越多个区域(数据中心)并使用能够在数据中心之间快速转移负载的软件来实现的,以避免单点故障。这在并行计算和冗余存储方面需要成本。如果托管的是全球交易平台,这个成本是值得的。如果一个副本丢失或不可用,操作将继续使用另一个副本。
不仅仅是半导体,为了获得最高的可靠性,数据中心拥有多余冷却系统。如果一个失效,另一个会接管。配电也是多余的,配有备用单元,可在需要时启动。此外,如果电网电力中断,电池或发电机将启动。

半导体可靠性的高级策略与数据中心的其他部分类似:
设计具有极高可靠性的组件;
设计组件和系统以识别早期故障迹象并优先修复;
添加冗余,以便如果组件在运行期间确实发生故障,能够迅速识别并由备份接管。
面向可靠性的半导体架构策略
数据中心芯片需要设计得尽可能可靠,但故障仍会发生。因此,数据中心芯片和子系统需要在架构上具备容错能力。
数据中心有成千上万个相同的服务器、交换机等。如果一个服务器或机架无法工作,可以绕过它。
ECC(错误校正码): 数据中心 CPU 使用 ECC 内存以实现高可靠性。自HBM2以来,HBM(高带宽存储器)就集成了片上ECC。HBM3使用更强大的Reed-Solomon码。HBM 还具有冗余数据总线通道,因此如果在运行期间某个通道出现故障,可以将其重新映射到备用的功能通道。
纵向扩展网络冗余: NVLink被称为是英伟达的“隐形护城河”,允许更大的 Pod 尺寸以及 GPU 之间极低的延迟。但是,为什么英伟达NVLink 是72 路而不是 64 路?英伟达的建议是使用 64 个 GPU 运行,保留 8 个作为备用(或处于待机状态,运行低优先级、可抢占的工作负载)。同样,交换机要有18个,尽管64个GPU只需要使用其中的 16 个。在 NVLink 中,每个交换机都连接到每个 GPU。这允许调节 GPU 之间的带宽,但这也意味着可以绕过发生故障的交换机而不会降低性能。当 NVL72 继续运行时,可以热插拔故障的交换机或计算托盘,以恢复完全冗余,实现最大可靠性。
几个月前,SemiAnalysis报道称,NVL72 背板的信号完整性问题导致了数据错误,可能需要数小时才能隔离和修复。NVL72 的修复时间比上一代长一个数量级。为了提供更高 Pod 性能而提高电频率,数据传输的可靠性会因信号完整性问题而降低。通过切换到光传输来提高可靠性也是必要的,因为光传输没有交叉耦合或电磁信号完整性问题,同时利用光学的更长传输距离来增加 Pod 尺寸。
横向扩展网络冗余:目前横向扩展系统主要基于以太网,基于数据包并确保数据包的传输,如果需要,会进行重试和备用路由。对每个数据包的数据负载都进行错误检查和纠正。RSTP(快速生成树协议)能够在毫秒级内从故障的主路径切换到备用路径。网络的鲁棒性非常高,但这在延迟上是有代价的。尽管如此,这仍是当今所有数据中心连接机架和排的方式。
光电路交换机:谷歌率先使用了 OCS,并将其部署在其 TPU 超级 Pod 中。电路交换机允许数百个光纤输入在毫秒级内重新路由到数百个光纤输出。这有很多好处。其中一个好处是能够绕过故障芯片快速重新路由高带宽数据。
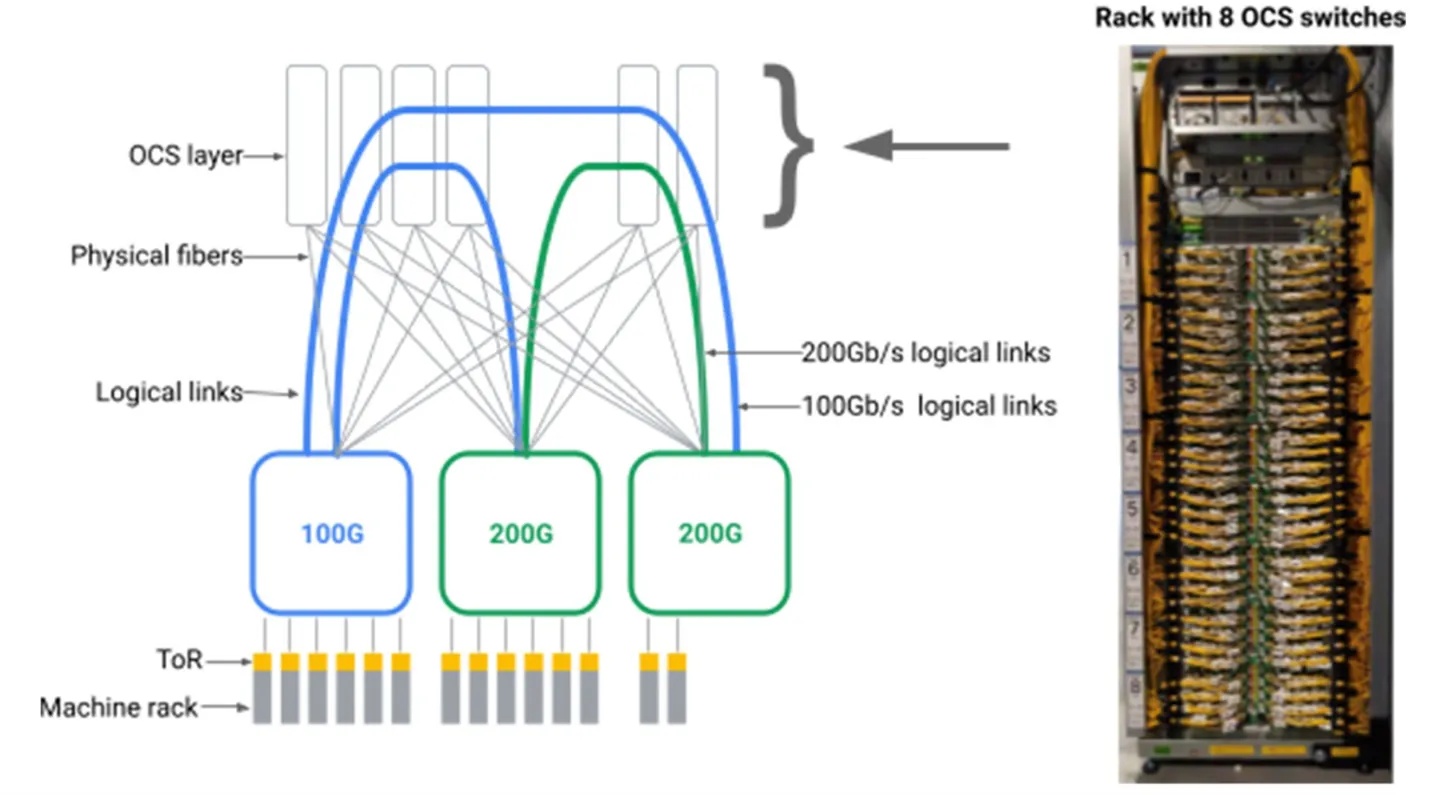
热插拔: 如果可能的话,系统应设计为模块化和热插拔,这样如果需要更换零件,可以快速、轻松地完成,且中断最小。
面向可靠性的半导体组件设计
与大多数半导体应用不同,机械工程对于数据中心的可靠性越来越重要。AI 加速器现在在有机基板上的CoWoS中介层上封装了多个XPU和HBM芯片。“三明治”各元素之间的材料和温度变化,以及层间数千个键合点,都存在物理连接翘曲和断裂的风险。
数据中心运营的某些方面对可靠性的要求较低:
工作温度: 英伟达 Blackwell GPU 的峰值工作温度为 85°C 结温。AMD Epyc 处理器通常在最高 95°C Tj下运行,但可以短暂运行在高达 105°C Tj。这些温度远低于汽车领域(高达 125°C Tj),因为功耗随温度呈指数增长;可靠性随温度升高而下降;昂贵的冷却系统应用在数据中心,在经济上是可行的,用以保持低功耗和高可靠性。
使用寿命: 汽车需要 10 年、15 年或 20 年的使用寿命。但数据中心使用寿命要短得多。有报道讨论了主要超大规模数据中心运营商出于会计目的的估计使用寿命,范围在5 到 6 年。从这个意义上说,数据中心就像 iPhone。5 年多以后会有更好的产品,因此升级比运行旧技术更经济,特别是考虑到世界大部分地区的电力限制。即使寿命很短,可靠性设计对于确保使用寿命期间的故障尽可能少也至关重要。
广泛的可靠性数据:5 年的使用寿命意味着当部署新的加速器/CPU/网络时,必须非常迅速地投入运行。这就像 iPhone 的产能爬坡。
超大规模数据中心运营商想要最好的技术,但只有在有广泛的可靠性数据可用时才会部署。
对于每个半导体组件,客户都希望看到广泛的可靠性和压力测试,从而实现极低的FIT率。这可能需要在高温下、在工作频率下对数以千计或数以万计的设备进行数月的测试,成本高昂。
故障预测与隔离: 客户希望拥有片上遥测技术,跟踪故障的主要指标,通过监控这些指标来确定何时应该在故障发生前主动更换设备。例如,在通信设备上,增加的误码率(BER)可能是一个早期预警指标。如果设备确实发生故障,它应该能够自我诊断并发出标志,以便可以快速隔离和修复错误的位置。如今在数据中心,可能需要数小时才能追溯故障的根本原因。
数据中心的供应商将希望能够访问其芯片上的遥测数据,以便可以学习提高预测故障的能力。此外,他们需要故障分析专家,能够确定故障的内容和原因,既要为更高的可靠性提供设计改进的反馈,又要调整固件设置以减少磨损或改进故障预测。
追求完美
数据中心是当今半导体最大的市场。若想取胜,就必须具备低功耗、低成本、高性能。但这一切都是基于高可靠性的架构、固件和设计,否则就无法被设计采用。
本文转自媒体报道或网络平台,系作者个人立场或观点。我方转载仅为分享,不代表我方赞成或认同。若来源标注错误或侵犯了您的合法权益,请及时联系客服,我们作为中立的平台服务者将及时更正、删除或依法处理。



联系电话:
010-61853490
新闻投稿:
server@icviews.cn
商务合作:
business@icviews.cn
问题反馈:
19800315212(微信同号)


半导纵横公众号

半导纵横小程序