CES 2026:英伟达Rubin架构首曝光,告别单芯片时代!
在2026年国际消费电子展(CES)上,人工智能无处不在,而英伟达GPU则是不断扩展的人工智能领域的核心。今日,在CES主题演讲中,英伟达首席执行官黄仁勋分享了公司将如何继续引领人工智能革命的计划。
NVIDIA Rubin,今日亮相
会上英伟达首席执行官黄仁勋介绍了新一代“Rubin”计算架构。Rubin是英伟达所谓的“极致协同设计”的成果,它由六种芯片组成:Vera CPU、Rubin GPU、NVLink 6交换机、ConnectX-9 SuperNIC、BlueField-4数据处理单元和Spectrum-6以太网交换机。这些组件共同构成了Vera Rubin NVL72机架。


对人工智能计算的需求永无止境,而每款 Rubin GPU 都承诺为这一代产品提供更强大的计算能力:NVFP4 数据类型的推理性能高达 50 PFLOPS,是 Blackwell GB200 的 5 倍;NVFP4 训练性能高达 35 PFLOPS,是 Blackwell 的 3.5 倍。为了满足如此庞大的计算资源需求,每款 Rubin GPU 都配备了 8 个 HBM4 显存堆栈,提供 288GB 的容量和 22 TB/s 的带宽。
每个GPU的计算能力只是人工智能数据中心的一个组成部分。随着领先的大型语言模型从激活所有参数以生成给定输出词元的密集架构,转向每个词元仅激活部分可用参数的专家混合(MoE)架构,这些模型的扩展效率得以相对提高。然而,模型内部专家之间的通信需要大量的节点间带宽。
Vera Rubin数据中心架构推出用于纵向扩展网络的NVLink 6,将每个GPU的交换矩阵带宽提升至3.6 TB/s(双向)。每个NVLink 6交换机拥有28 TB/s的带宽,每个Vera Rubin NVL72机架配备9个这样的交换机,总纵向扩展带宽可达260 TB/s。
Nvidia Vera CPU 采用 88 个定制的 Olympus Arm 核心,并配备 Nvidia 所谓的“空间多线程”技术,可同时运行多达 176 个线程。用于将 Vera CPU 与 Rubin GPU 连接起来的 NVLink C2C 互连带宽翻倍,达到 1.8 TB/s。每个 Vera CPU 可寻址高达 1.5 TB 的 SOCAMM LPDDR5X 内存,内存带宽高达 1.2 TB/s。
为了将 Vera Rubin NVL72 机架扩展为每个包含八个机架的 DGX SuperPod,Nvidia 推出了两款采用 Spectrum-6 芯片的 Spectrum-X 以太网交换机,这两款交换机均集成了光模块。每颗 Spectrum-6 芯片可提供 102.4 Tb/s 的带宽,Nvidia 将其应用于两款交换机中。
SN688 拥有 409.6 Tb/s 的带宽,可配置 512 个 800G 以太网端口或 2048 个 200G 以太网端口。SN6810 提供 102.4 Tb/s 的带宽,可配置 128 个 800G 以太网端口或 512 个 200G 以太网端口。这两款交换机均采用液冷散热,Nvidia 声称它们具有更高的能效、更高的可靠性和更长的正常运行时间,这大概是指与缺乏硅光子技术的硬件相比而言。
随着上下文窗口增长到数百万个令牌,英伟达表示,对存储与 AI 模型交互历史记录的键值缓存的操作将成为推理性能的瓶颈。为了突破这一瓶颈,英伟达正在利用其下一代 BlueField 4 DPU 创建其所谓的新内存层:推理上下文内存存储平台。该公司表示,这一层存储旨在实现人工智能基础设施中键值缓存数据的高效共享和重用,从而提高响应速度和吞吐量,并实现智能体人工智能架构的可预测、节能扩展。
Vera Rubin 还首次将英伟达的可信执行环境扩展到整个机架,通过保护芯片、架构和网络级别,英伟达表示,这对于确保人工智能前沿实验室珍贵的尖端模型的保密性和安全性至关重要。
总而言之,每个 Vera Rubin NVL72 机架提供 3.6 exaFLOPS 的 NVFP4 推理性能、2.5 exaFLOPS 的 NVFP4 训练性能、连接到 Vera CPU 的 54 TB LPDDR5X 内存以及 20.7 TB HBM4,提供 1.6 PB/s 的带宽。
为了保持这些机架的高效运行,Nvidia 重点介绍了机架级别的几项可靠性、可用性和可维护性 (RAS) 改进,例如无电缆模块化托盘设计,与之前的 NVL72 机架相比,可以更快地更换组件;改进的 NVLink 弹性,可以实现零停机维护;以及第二代 RAS 引擎,可以实现零停机健康检查。
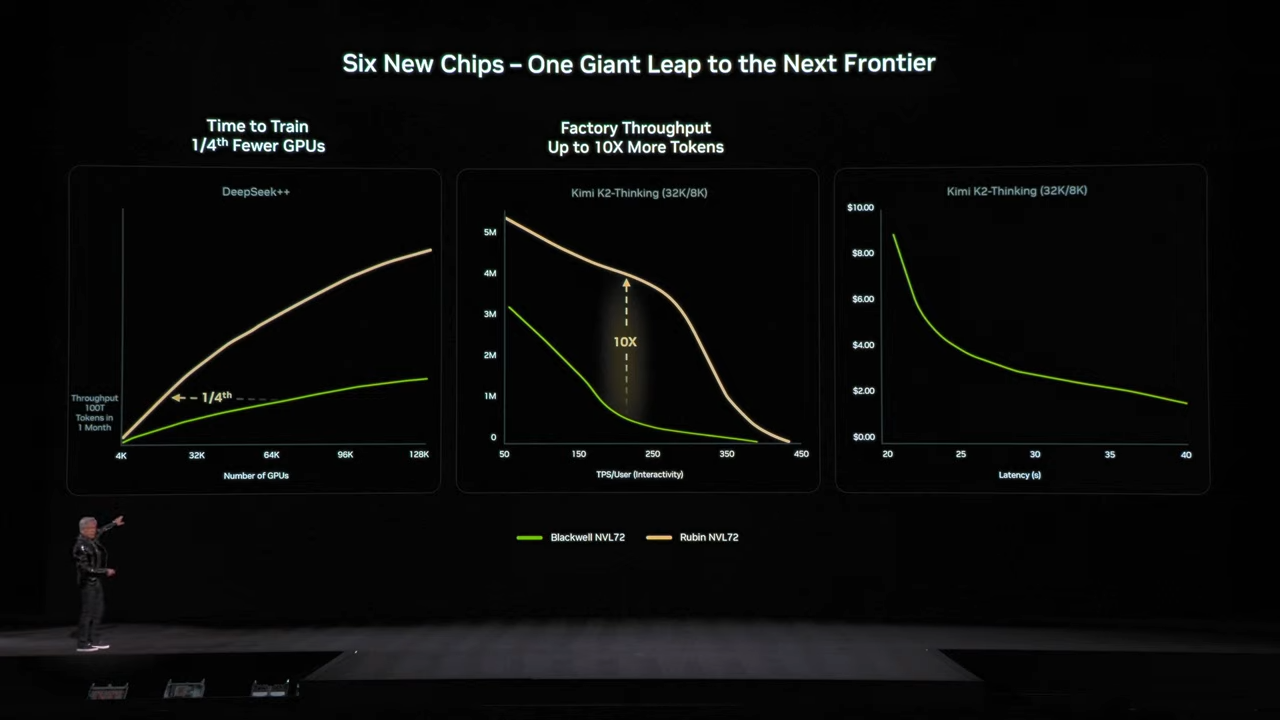
所有这些强大的计算能力和带宽乍看之下令人印象深刻,但对于英伟达的合作伙伴而言,在考虑未来大规模投资扩容时,总体拥有成本可能才是最重要的。英伟达表示,使用 Vera Rubin 训练 MoE 模型所需的 GPU 数量仅为 Blackwell 的四分之一,并且 Rubin 可以将各种模型的 MoE 推理的单令牌成本降低多达 10 倍。反过来,这意味着 Rubin 还可以提高训练吞吐量,并在相同的机架空间内提供更多的令牌。
Rubin 生产,已准备就绪!
NVIDIA Rubin 已全面投入生产,基于 Rubin 的产品将于 2026 年下半年通过合作伙伴推出。
2026 年首批部署基于 Vera Rubin 的实例的云提供商包括 AWS、Google Cloud、Microsoft 和 OCI,以及NVIDIA 云合作伙伴CoreWeave、Lambda、Nebius 和 Nscale。
微软将在下一代人工智能数据中心(包括未来的 Fairwater AI 超级工厂)中部署 NVIDIA Vera Rubin NVL72 机架级系统。
此外,思科、戴尔、HPE、联想和超微预计也将推出基于 Rubin 产品的各种服务器。
包括 Anthropic、Black Forest、Cohere、Cursor、Harvey、Meta、Mistral AI、OpenAI、OpenEvidence、Perplexity、Runway、Thinking Machines Lab 和 xAI 在内的 AI 实验室正在寻求利用 NVIDIA Rubin 平台来训练更大、更强大的模型,并以比以往 GPU 更低的延迟和成本为长上下文、多模态系统提供服务。
基础设施软件和存储合作伙伴 AIC、Canonical、Cloudian 、 DDN、Dell、HPE、Hitachi Vantara、IBM、NetApp、Nutanix、Pure Storage、Supermicro、SUSE、VAST Data 和WEKA正在与 NVIDIA 合作,为 Rubin 基础设施设计下一代平台。
Alpamayo,物理AI真正到来
会上,英伟达还宣布 NVIDIA DRIVE AV 驾驶辅助软件将率先随全新梅赛德斯-奔驰 CLA 车型登陆美国,新车预计于今年年底前推出。
该软件将为奔驰 CLA 带来增强的 L2 级端到端驾驶辅助能力,标志着以 AI 定义驾驶体验的新阶段。全新梅赛德斯-奔驰 CLA 是该品牌首款搭载 MB.OS 平台的车型,引入了 NVIDIA DRIVE AV、AI 基础设施以及加速计算能力所支持的先进驾驶辅助功能。
在技术架构上,NVIDIA DRIVE AV 采用双栈架构:一方面是用于核心驾驶的端到端 AI 驱动栈,另一方面是基于 NVIDIA Halos 安全系统构建的并行传统安全栈,为系统提供冗余和安全防护。通过这种方式,其车辆能够从大量真实与合成驾驶数据中学习,辅助驾驶员在复杂环境和场景中以接近人类的决策方式安全行驶。
英伟达表示,该统一架构支持功能更为丰富的 L2 级自动驾驶能力,包括在复杂城市环境中的端到端导航、具备主动碰撞规避能力的高级主动安全功能,以及在狭小空间内的自动泊车能力。此外,该系统还支持系统与驾驶员之间的协同转向。
如果说奔驰 CLA 的发布是英伟达“车载”技术的证明,那么 Alpamayo 就是英伟达试图将自动驾驶变成一个生态系统,并继续掌控决定谁能驾驶下一辆车的工具。
Alpamayo是一个全新的开源人工智能模型、仿真工具和数据集系列,用于训练物理机器人和车辆,旨在帮助自动驾驶车辆应对复杂的驾驶情况。
作为 Alpamayo 推广计划的一部分,英伟达还发布了一个开放数据集,其中包含超过 1700 小时的驾驶数据,这些数据涵盖了各种地理区域和路况,囊括了罕见且复杂的真实世界场景。此外,该公司还推出了 AlpaSim,这是一个用于验证自动驾驶系统的开源仿真框架。AlpaSim 已在 GitHub 上发布,旨在重现从传感器到交通状况的真实驾驶环境,以便开发人员能够安全地进行大规模系统测试。
Alpamayo 1是一个拥有 100 亿个参数的基于推理的思维链视觉语言动作 (VLA) 模型,它使自动驾驶汽车能够更像人类一样思考,从而在没有先前经验的情况下解决复杂的边缘情况,例如如何在繁忙的十字路口应对交通信号灯故障。
它通过将问题分解成多个步骤,推演每一种可能性,然后选择最安全的路径来实现这一点。它们还可以使用 Cosmos 生成合成数据,然后结合真实数据集和合成数据集,对基于 Alpamayo 的自动驾驶应用程序进行训练和测试。
此外,英伟达还发布了全新的开源模型 Nvidia Cosmos 和 GR00T。该公司表示,这些模型旨在帮助开发者减少预训练所需的时间和资源,从而将更多精力投入到构建下一代机器人上。
英伟达表示,Nvidia Cosmos Reason 2 是一种开放式推理视觉语言模型 (VLM),它使智能机器能够“像人类一样观察、理解和行动于物理世界”。此外,借助 Nvidia Cosmos Reason 2,物理人工智能可以像人类一样,运用推理、先验知识、物理理解等做出决策。
最后,Nvidia Isaac GR00T N1.6 是一款专为类人机器人设计的开放式推理视觉语言动作 (VLA) 模型,它支持全身控制,并利用 Nvidia Cosmos Reason 实现上述额外优势。所有这些新模型均可在 Hugging Face 上获取。
此内容为平台原创,著作权归平台所有。未经允许不得转载,如需转载请联系平台。




联系电话:
010-61853490
新闻投稿:
server@icviews.cn
商务合作:
business@icviews.cn
问题反馈:
19800315212(微信同号)


半导纵横公众号

半导纵横小程序