新架构很炸裂,但摩尔线程的真正野心在应用层
2024年的圣何塞,英伟达GTC大会上,当黄仁勋站在那块标志性的巨型LED屏幕前,真正让硅谷为之沸腾的,不仅仅是Blackwell芯片那恐怖的参数,而是会场外那个挤满了人形机器人、数字孪生工厂和气象模拟器的庞大展区。那里涌动着数以万计的开发者,他们用代码和应用证明了一个事实:英伟达的护城河不在冰冷的硅基切片上,而在那些让物理世界“活”起来的生态里。
2025年12月20日,北京的中关村国际创新中心,寒风中涌动着同样的热流。在摩尔线程首届MUSA开发者大会的现场,如果我们试图寻找这家“最像英伟达的中国挑战者”最真实的战略底色,答案或许同样不在主论坛聚光灯下滚动的参数PPT里,而在于会场外那个喧嚣的、超过1000平方米的“MUSA嘉年华”展区。

与传统芯片发布会往往仅展示服务器机箱、加速卡静态模组或单纯的Stable Diffusion生图演示不同,此次大会的展区布置呈现出一种高密度的“应用集市”形态。这里展示的不是芯片本身,而是芯片嵌入物理世界后的运行状态。
半导体产业纵横记者看到,在工业智造板块,雪浪云通过数字孪生屏幕展示了基于摩尔线程GPU的“盾构大脑”方案,呈现了地下几十米深处的三维地质构造与掘进姿态;在智慧医疗区域,微眸医疗展示了眼科手术机器人的端侧算力应用,利用GPU进行毫秒级的眼球组织识别与实时渲染;在具身智能领域,景业智能的四足巡检机器狗通过VR遥操作终端,展示了低延迟的视频回传与环境感知能力。此外,中国移动和中国电信展示了基于全功能GPU的云桌面与云游戏方案,实现了单卡并发多路的高清视频流分发。
这些屏幕上的实时渲染画面、后台流动的AI推理数据以及端侧设备的响应,构成了一个复杂的混合算力场。这种布展逻辑折射出国产GPU行业的一个重要转向:从早期的单点算力比拼,进入到以场景落地、工程化稳定性和生态密度为核心的“深水区”。
摩尔线程试图通过展示这些跨行业的落地案例证明,国产GPU的应用边界正在从单一的数据中心,向工业、医疗、教育、通信等物理世界的毛细血管渗透。这种渗透的广度,正是其“全功能GPU”战略的护城河所在。
物理世界,倒逼芯片架构
行业用户关注的焦点往往不是单纯的TFLOPS数值,而是“芯片能否解决复杂系统的协同问题”。以现场展示的工业数字孪生和具身智能场景为例,系统面临的是典型的“混合负载”挑战:它不仅需要处理传感器传回的海量时序数据进行AI预测,还需要实时构建高保真的三维模型进行可视化呈现,并对控制参数进行低延迟反馈。这揭示了物理世界智能化的一个真相:它往往是“AI计算+图形渲染+视频处理+物理仿真”的综合体。
目前,国内芯片行业存在多种技术路线。部分专注于AI计算的ASIC或GPGPU产品在单一计算任务上表现优异,但在面对上述这种跨域需求时,往往因为缺乏图形渲染单元或视频引擎,需要搭配额外的图形显卡。这种“异构拼凑”不仅增加了硬件成本和功耗,更带来了跨PCIe设备的数据传输瓶颈和复杂的驱动兼容性挑战。
摩尔线程坚持的“全功能GPU”路线,正是基于对这种应用场景的判断。12月20日,上市15天的摩尔线程正式发布了新一代全功能GPU架构——“花港”,该架构算力密度提升50%,效能提升10倍。更为关键的是,“花港”架构在设计之初就兼顾了计算与图形的双重需求,并针对性地解决了“既要又要”的难题:全精度计算支持, 它支持从FP4、FP6、FP8到FP64的全精度计算。这一点在MDC上被反复强调,因为科学计算往往需要FP64的高精度,而前沿的大模型推理正在向FP4低精度演进。全精度支持意味着它能适应从科研到商业的全谱系需求。图形引擎进化, 它内置了第二代光线追踪硬件加速引擎和AI生成式渲染架构。基于此架构,摩尔线程公布了未来的芯片演进路线。
“华山”芯片:专攻AI训推一体,内置新一代异步编程模型和全精度张量核心,旨在为万卡级智算集群提供稳定支撑。
“庐山”芯片:专攻极致图形渲染,计划将光线追踪性能提升50倍,3A游戏性能提升15倍,并宣布将于2026年完整支持DirectX 12 Ultimate标准。


这一路线图不仅清晰地展示了与其他国产厂商的差异化打法,也意味着国产显卡将在图形API标准上首次对齐国际一流水平。对于依赖Unreal Engine或Unity开发工业软件和游戏的开发者而言,这是一个关键信号:国产GPU不再是只能跑特定AI模型的加速卡,而是可以支撑复杂图形生态的通用底座。
今天的算力,好用了吗?
如果说工业现场考验的是GPU的广度,那么大模型训练则是检验GPU高度的试金石。这也是此前国产GPU最受B端客户质疑的领域。
在MDC 2025上,摩尔线程发布的“夸娥”万卡智算集群,重点展示了其在超大规模训练任务中的工程化能力。对于B端客户而言,集群的有效性远比峰值算力重要。数据显示,“夸娥”集群在Dense大模型上的训练算力利用率达60%,训练线性扩展效率达95%。

在软件层面,为了解决大规模集群常见的故障中断痛点,摩尔线程推出了万卡训练容错系统,通过自动故障检测和快速checkpoint恢复,将有效训练时间占比提升至90%以上。这一数据直接回应了行业对于国产集群“经常断训、甚至无法收敛”的担忧。
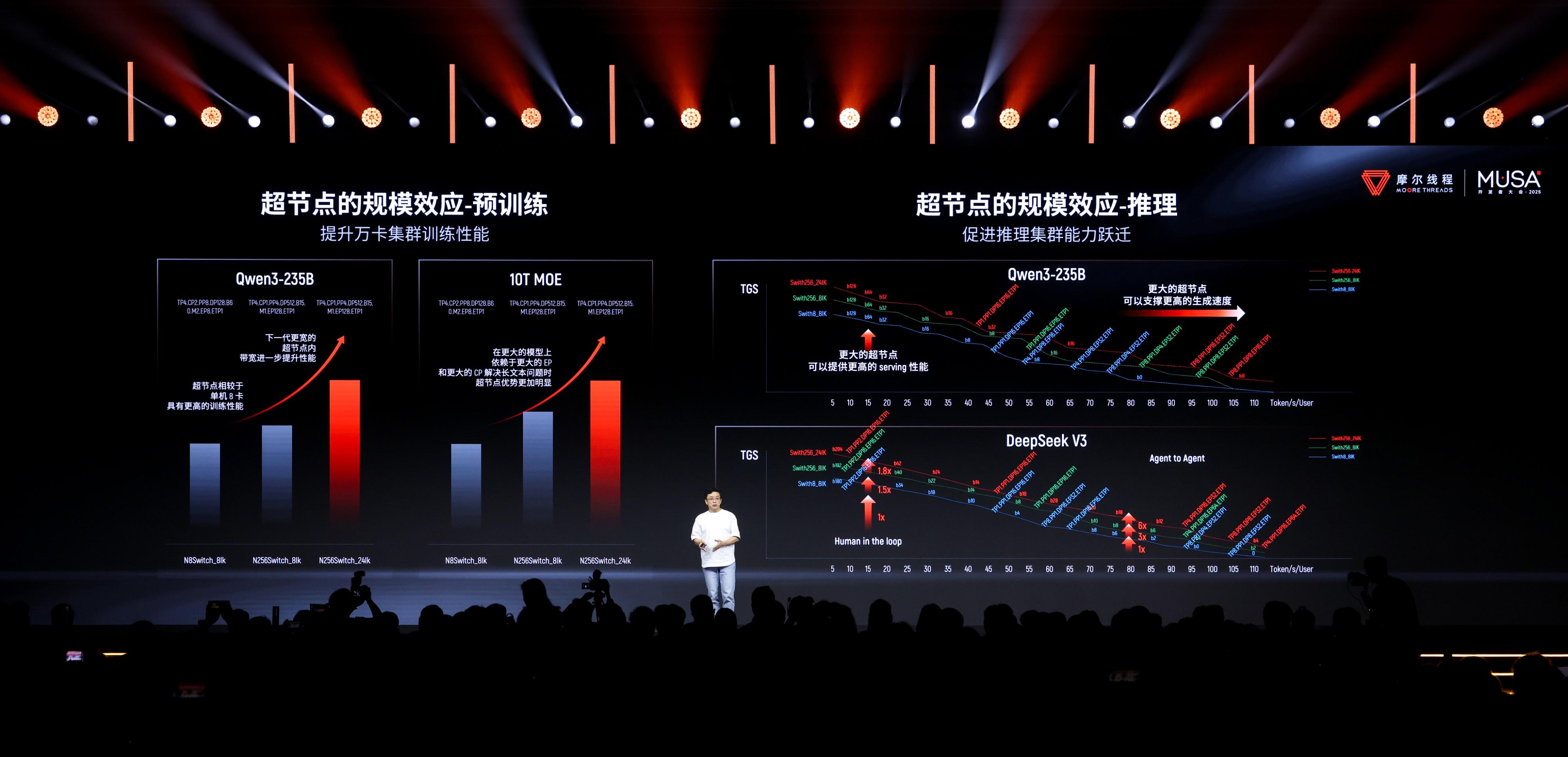
在硬件层面,摩尔线程补齐了互联带宽的短板。发布会上披露,其新一代Scale-up系统实现了1314 GB/s的片间互联带宽(MTLink 4.0),并推出了MTT C256超节点,能够以一层网络实现256颗GPU的全互联。虽然这一指标与英伟达最新的NVLink技术仍有代差,但在国产阵营中,能够实现千卡乃至万卡级别的线性级联,已足以支撑万亿参数模型的规模化训练。
在实战层面,摩尔线程宣布通过软硬协同深度优化,完整复现了DeepSeek V3的FP8训练。在这一过程中,摩尔线程特别强调了一个技术突破:其全功能GPU支持高精度累加计算,突破了DeepSeek V3在国际产品上FP8累加精度不足的难题。正如会上硅基流动CEO袁进辉指出:“有算力和好用的算力之间,有一条看不见的鸿沟。” DeepSeek V3的案例正是跨越这条鸿沟的典型。在行业惯例中,为了追求速度,部分专用AI芯片在处理FP8数据格式时,可能会因为硬件设计原因牺牲一定的累加精度,这往往导致大模型训练后期不收敛,前功尽弃。摩尔线程得益于MUSA架构的通用性设计,在保证速度的同时守住了精度的底线。此外,在推理侧,摩尔线程联合硅基流动,在现款旗舰卡MTT S5000上完成了DeepSeek R1 671B全量模型的适配。实测显示,单卡解码性能突破1000 Tokens/s,Prefill吞吐突破4000 tokens/s。这一数据表明,国产GPU已经具备了在生产环境中承载高并发推理业务的能力。
针对行业内对于国产算力“好不好用”的顾虑,摩尔线程创始人、董事长兼CEO张建中在现场的一席话或许是最好的回应:“以前很多国内开发者,由于国产硬件平台的性能不够,导致开发的产品跟主流产品有一定的差距。我们今天把平台提升,就是为了努力疏解开发者的束缚。”
走向智能端,撬动开源生态
在展区中,一款名为MTT AIBOOK的硬件产品引起了观众的注意。这是一款搭载摩尔线程自研“长江”智能SoC的AI算力本,拥有50 TOPS的异构算力,预置了Linux内核的MT AIOS操作系统及完整的AI开发环境,甚至内置了一个智能体“小麦”。该产品已于12月20日在京东商城开启预售。
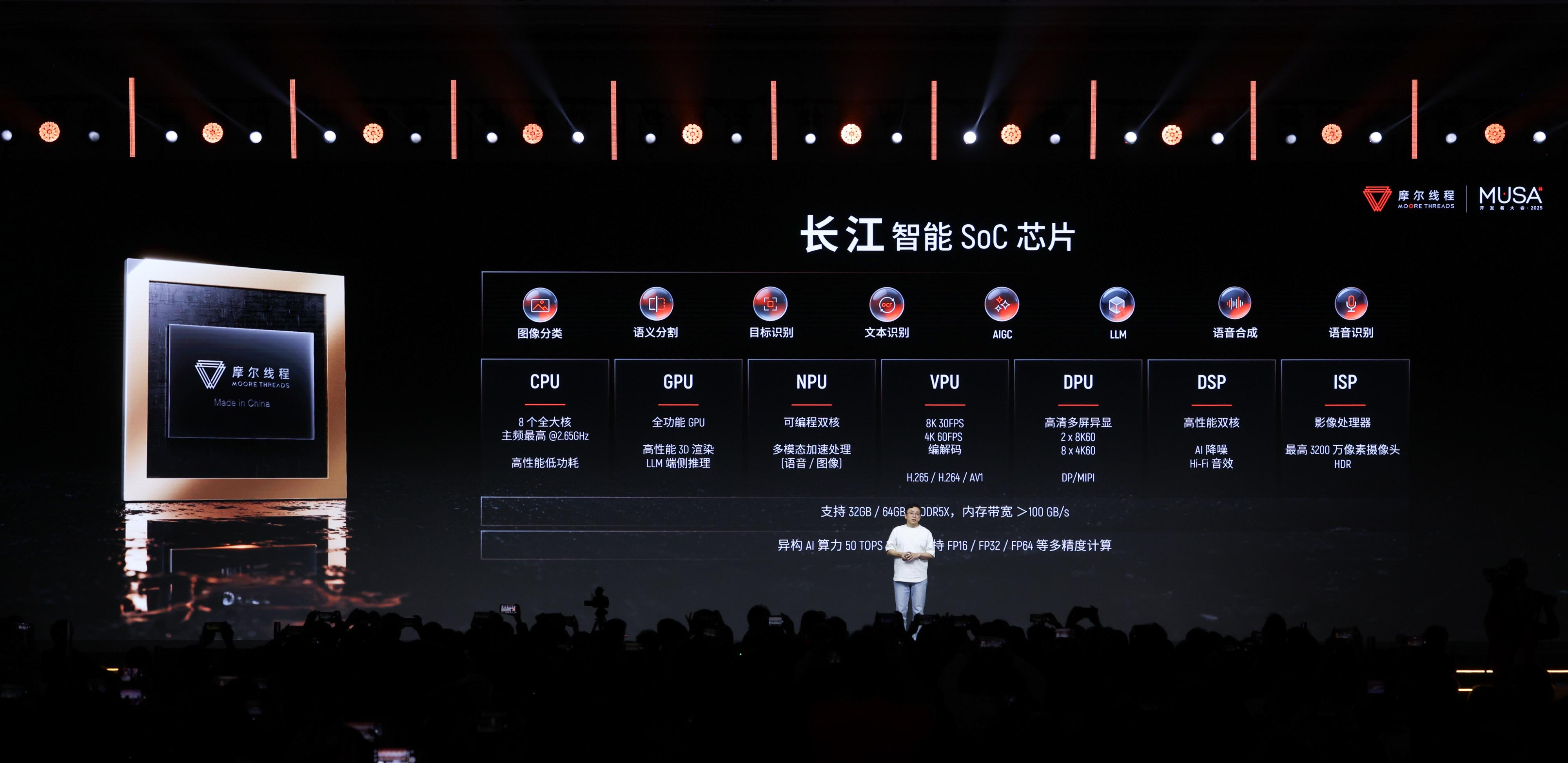

在当前国产芯片行业中,大多数厂商主要聚焦于B端数据中心市场,服务于运营商和大型互联网企业。这种策略虽然能快速获得大额订单,但往往难以触达最广泛的个人开发者和学生群体。而英伟达CUDA生态之所以强大,很大程度上源于其消费级显卡在教育和个人领域的极高渗透率,使得开发者在学生时代就习惯了其编程范式。
谈到生态建设的底层逻辑,摩尔线程CTO张钰勃表示:“一个公司的力量是有限的。未来我们每一代的GPU,从架构开始到上面的每一层软件,我们全部都会坚持开源的路线。我们要把黑盒打开,让开发者看到底层。”这种“开源”承诺与“终端普及”策略相结合,构成了摩尔线程独特的生态闭环:第一,降低门槛:摩尔线程推出AIBOOK,旨在补齐国产GPU生态在“人才供应链”上的短板。学生无需申请昂贵的云端服务器算力,在宿舍里就能用AIBOOK跑通MUSA代码。第二,打通链路:这是一个开箱即用的验证终端,实现了“端侧开发、云端部署”的无缝闭环。第三,开源共创:通过开源MUSA SDK、通信库及编译器前端,吸引高校和科研机构深度参与优化。正如清华大学翟季冬教授在会上表示:“真正的软硬协同,是要让做硬件的人看见软件第一手的需求。”通过将硬件下沉到C端开发者手中,摩尔线程能够更直接地获取开发者的反馈,从而反哺软件栈的迭代。目前,摩尔线程已直接触达了摩尔学院汇聚的20万开发者和全国200多所高校。这20万个“种子”,在未来将成为支撑国产计算生态的中坚力量。

结语:生态密度的较量
通过MDC 2025,摩尔线程传递出的最重要信号并非某一项参数的刷新,而是其生态系统的“密度”。
从地下的盾构机到云端的DeepSeek训练,从高校实验室的AIBOOK到前沿探索的量子计算框架MUSA-Q,摩尔线程的产品线覆盖了从端到云、从AI到图形、从商业应用到基础科学的广泛场景。


这种全铺开的打法,虽然在初期面临着巨大的研发挑战,需要同时维护庞大的图形驱动和AI编译器,适配海量的应用软件,但一旦生态成型,其抗风险能力和市场壁垒也将极高。正如中国工程院院士郑纬民所讲:发展“主权AI”的核心在于实现“算力自主、算法自强、生态自立”。其中,“生态自立”是最难啃的骨头。
对于国产GPU行业而言,2026年将是一个分水岭。如果说之前的竞争更多停留在参数对标上,那么接下来,谁能让芯片在更多的物理场景中真正转动起来,谁能让更多的开发者在自己的平台上写下第一行代码,谁就能在激烈的淘汰赛中站稳脚跟。
此内容为平台原创,著作权归平台所有。未经允许不得转载,如需转载请联系平台。




联系电话:
010-61853490
新闻投稿:
server@icviews.cn
商务合作:
business@icviews.cn
问题反馈:
19800315212(微信同号)


半导纵横公众号

半导纵横小程序