Marvell用CXL,让DDR4“起死回生”
消费市场的DDR5内存价格飙升。由于AI数据中心对DRAM供应造成了巨大的需求压力,许多领域的DDR5内存价格都在上涨。因此,超大规模数据中心正在启用多年来采购的数十泽字节的DDR4内存,以降低价格上涨的影响。
我们前往Marvell公司,亲眼见证了其Structera X CXL扩展方案的实际应用。在那里,我们还看到了Marvell Structera A,它将16个Arm内核与DDR5 CXL控制器相结合,使系统构建商能够同时扩展计算和内存容量。虽然有人认为CXL不适用于AI,但我们有一个绝佳的例子可以证明CXL内存如何提升性能。
Marvell Structera X DDR4 和 DDR5 控制器
在 Marvell 公司期间,我们有机会亲眼目睹了全部三款 Structera 芯片。其中包括 Structera X(内存扩展控制器)和 Structera A(除了内存扩展功能外,还集成了 16 个 Arm Neoverse V2 内核)。这些都是高性能的 Arm 内核,我们一直很好奇它们的工作原理。这次我们不仅亲眼见证了它们的运作,还看到了“慢速”CXL 设备如何提升系统速度的实例。
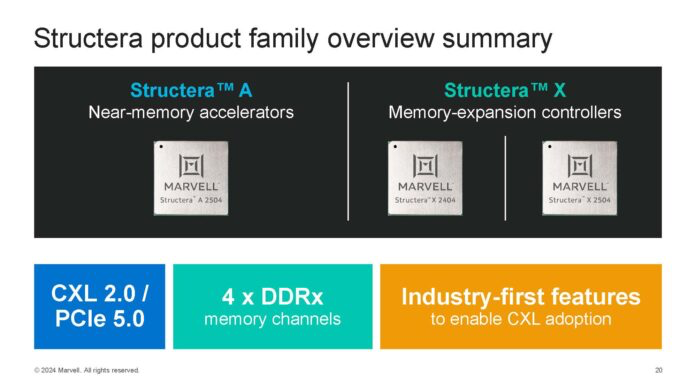
Marvell Structera 将于 2024 年推出产品线
这些设备的一大亮点在于,CXL 设备支持以内存线速进行 LZ4 压缩。Marvell 告诉我们,他们已经实现了 1.8 倍到 2 倍的压缩比。这不仅意味着你可以扩展内存,而且如果你将内存添加到 Structera 控制器上,每 GB 的实际成本大约只有其他安装方式的一半。
从 Structera X 2404 开始,这是一款 4 通道的 DDR4 扩展器。

Marvell Structera X 2404 4通道DDR4内存扩展设备
对于超大规模数据中心而言,这极具吸引力,因为它不仅可以提供四个 DDR4 通道,而且每个通道还可以支持三个 DIMM 插槽,即 3DPC(3DPC 模式)。换句话说,每个 Structera X 控制器可以支持十二个 DDR4 DIMM 插槽。

Marvell Structera A CXL DDR4 2
如果一家超大规模数据中心从退役服务器中回收 128GB DDR4 DIMM 内存条,使其“免费”可用,那么它就可以在单个 Structera X 2404 控制器上拥有 1.5TB 的内存。经过压缩,这大约相当于 2.75-3TB 的有效容量。

Marvell Structera A CXL DDR4
这种模式的另一个优势在于,超大规模数据中心可以回收利用内存,这意味着部署该方案只需要生产线缆、电路板和控制器,而无需生产DRAM。对于那些有环境影响目标的企业(暂且不谈人工智能),这种模式的影响远不止于成本节约。
DDR4 版本更注重性价比,但由于运行速度较低,性能也相应降低。对于需要更高性能 CXL 内存扩展器的用户,可以选择名为 Structera X 2504 的 DDR5 四通道版本。

Marvell Structera X 2504 概述 CXL 内存扩展器
它还提供 LZ4 压缩,这意味着不仅可以向系统中添加更多内存,而且添加到此内存中的内存实际上比添加到 CPU 的 DDR5 DIMM 插槽中的内存成本更低,因为每美元可以获得更大的容量。
另一个好处是,由于 CXL 使用的是 PCIe 控制器和线缆,而不是 DDR5 控制器和线缆,因此可以获得更高的带宽。这样一来,该系统既增加了内存容量,也提高了可用内存带宽。
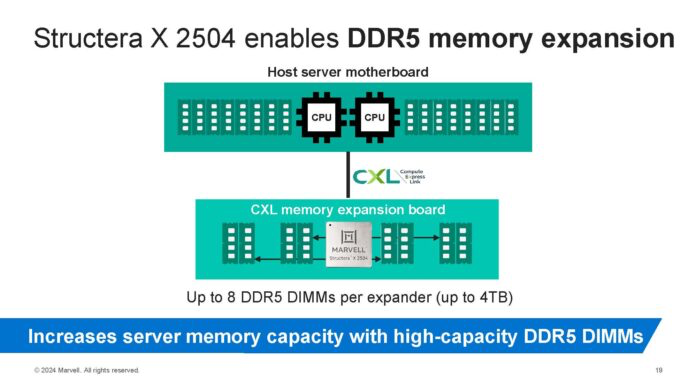
Marvell Structera X 2504 概述:CXL 内存扩展器,支持 DDR5
如果您想了解 Marvell 是如何实现这一点的,可以参考以下框图,想象一个 CXL 控制器。它的一端连接到 CXL 2.0 / PCIe Gen5 通道。该控制器包含压缩和解压缩/加密解密 IP。此外,它还包含内存控制器。DDR5 版本中的内存控制器支持 DDR5 内存,而 DDR4 版本中的内存控制器则支持 DDR4 内存。理论上,借助 CXL 技术,您可以兼容不同类型的内存。
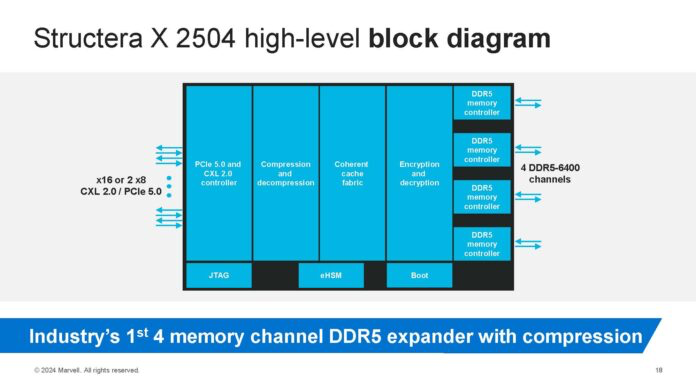
Marvell Structera X 2504 概述 CXL 内存扩展器框图
让我们更进一步,为 Structera X 2504 增添 16 个 Arm Neoverse V2 核心,使其性能更上一层楼。这些高性能 Arm 核心与 NVIDIA Grace CPU 中的类似,但这次它们被集成在了 CXL 加速器上。这正是 Marvell Structera A 与众不同之处。

Marvell Structera A 2504 概述
从框图来看,它与 X 2504 非常相似,但 A 2504 的中间部分采用了 Arm Neoverse V2 内核。
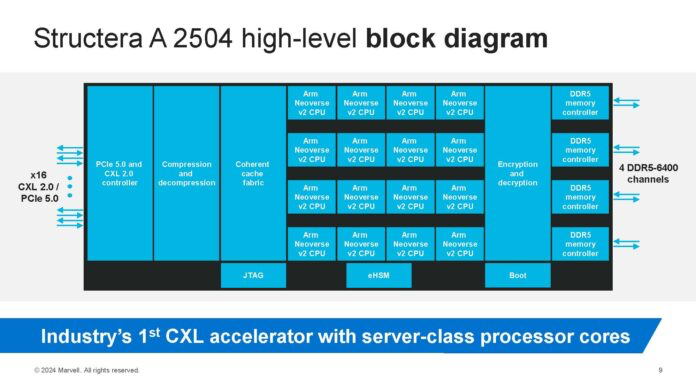
Marvell Structera A 框图
如果你想知道这在实际应用中是如何运作的,可以把它想象成一个运行在本地的轻量级 Linux 发行版,作为终端节点。这就像一台运行在另一台服务器上的迷你服务器,其运行速度与内存速度相当。它采用高速 Arm 内核,目标是在连接的内存上进行计算。
我们在实验室里看到的这些显卡,其两面都采用了 DDR5 封装,并且是低矮型 x16 外形尺寸。如果你需要一个概念模型来理解它的工作原理,可以把它想象成一个分布式处理单元(DPU),但它不是处理网络流量,而是处理本地内存。这意味着服务器可以同时扩展内存和计算能力。当然,去Marvell最有趣的部分就是我们有机会观看现场演示。

Marvell Structera A CXL 后部 DDR5
CXL 快速演示
这套系统配备了Structera A 2504显卡、一台Supermicro Intel Xeon服务器、一个Antec电源、几个风扇以及实验室级别的布线。
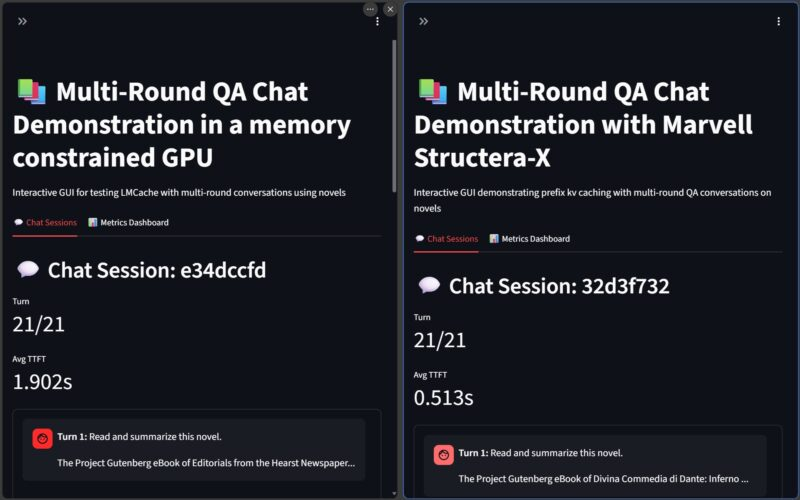
Marvell Structera X 演示版 20 个关于但丁《神曲·地狱篇》的问题
我们演示了当GPU内存不足时,Structera X如何充当KV缓存的存储。这实际上就是让Llama 3模型阅读书籍,然后提出关于书籍的问题。
模型仍然在GPU上运行,但仅仅是将KV缓存存储在内存中就改变了首次令牌到达时间(TTFT)。每次运行结果略有不同,但多次运行后,TTFT总共节省了大约30秒。当然,这实际上只是说明,即使延迟稍高,拥有更多内存也是有益的。
不过,我还是很想知道Structera A是如何工作的。这里有个很有意思的例子。你可以看到左侧的系统,它正在运行一个搜索程序,使用了48个英特尔至强处理器核心,以及连接到至强处理器插槽的本地内存。
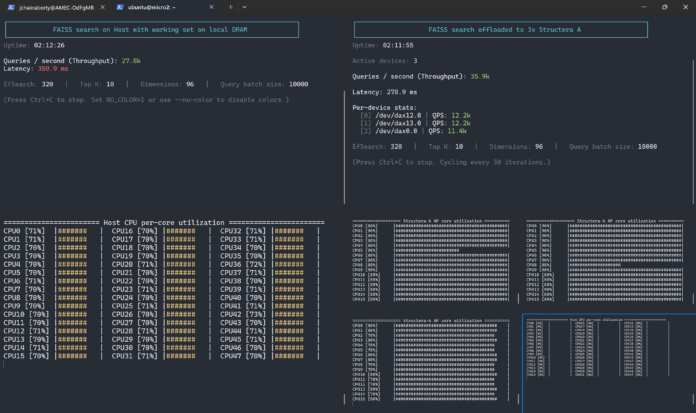
Marvell Structera A 演示图像 三个 Structera A 设备
右侧显示的是三张几乎满负荷运行的 Structera A 卡,而右下角的 Xeon 核心则完全没有负载。这个演示的目的是利用三张卡上总共 48 个 Arm Neoverse V2 核心。当 Xeon 核心空闲时,系统可以通过扩展内存来提升计算能力,从而执行更多任务。
这些演示主要侧重于展示如何使用这些模块来提高性能,但在许多用例中,拥有更多内存,或者在系统中拥有更多内存和计算能力,可以提高性能。
结语
这次视频让我们得以一窥超大规模数据中心正在使用的这项技术的幕后运作。从行业角度来看,这项技术最初是由一家超大规模数据中心提出的,但现在几乎所有数据中心都在采用,尤其是在他们意识到回收利用DDR4内存的好处之后。
Marvell Structera 目前专注于超大规模项目,这合情合理。当主机系统、模块类型等数量有限时,DDR4 的回收利用或 DDR5 的添加就更加容易。固件的兼容性是目前市面上没有 CXL 扩展设备的原因之一。Structera A 还需要管理卡上的 Linux 发行版,向 Arm 内核发送指令等等。尽管如此,这项技术非常酷,正在超大规模数据中心部署,但我们并不常见到。
本文转自媒体报道或网络平台,系作者个人立场或观点。我方转载仅为分享,不代表我方赞成或认同。若来源标注错误或侵犯了您的合法权益,请及时联系客服,我们作为中立的平台服务者将及时更正、删除或依法处理。



联系电话:
010-61853490
新闻投稿:
server@icviews.cn
商务合作:
business@icviews.cn
问题反馈:
19800315212(微信同号)


半导纵横公众号

半导纵横小程序