AMD的Magny Cours与HyperTransport互连技术
如今,我们早已习惯了拥有 16 核及以上的桌面处理器,服务器 CPU 的核心数更是数倍于此。但早在 2010 年之前,英特尔和 AMD 就已在全力攻克核心数提升的难题。AMD 的 “Magny Cours”(即皓龙 6000 系列)便是其中的一次重要尝试。回顾 AMD 如何凭借 2010 年前的技术实现核心数扩展,不失为一段有趣的技术溯源。特别感谢 cha0shacker 提供了双路皓龙 6180 SE 系统以供测试。
Magny Cours 芯片本质上是将两个 Phenom II X6 CPU 裸片并排封装。与流片全新的高核心数裸片相比,复用上一代 6 核裸片不仅降低了验证需求,还提高了生产良率。两个裸片通过 HyperTransport(HT,超传输)链路连接 —— 这一技术从 K8 架构时代就开始用于桥接多插槽系统。Magny Cours 沿用了这一理念,但将 HyperTransport 信号通过封装内的 PCB 布线传输。与双插槽架构类似,Magny Cours 芯片上的两个裸片各有独立的内存控制器,同一裸片上的核心访问本地内存时速度更快。这形成了 NUMA(非统一内存访问)架构,不过 Magny Cours 也可配置为跨节点交错内存访问,以提升非 NUMA 感知代码的性能。
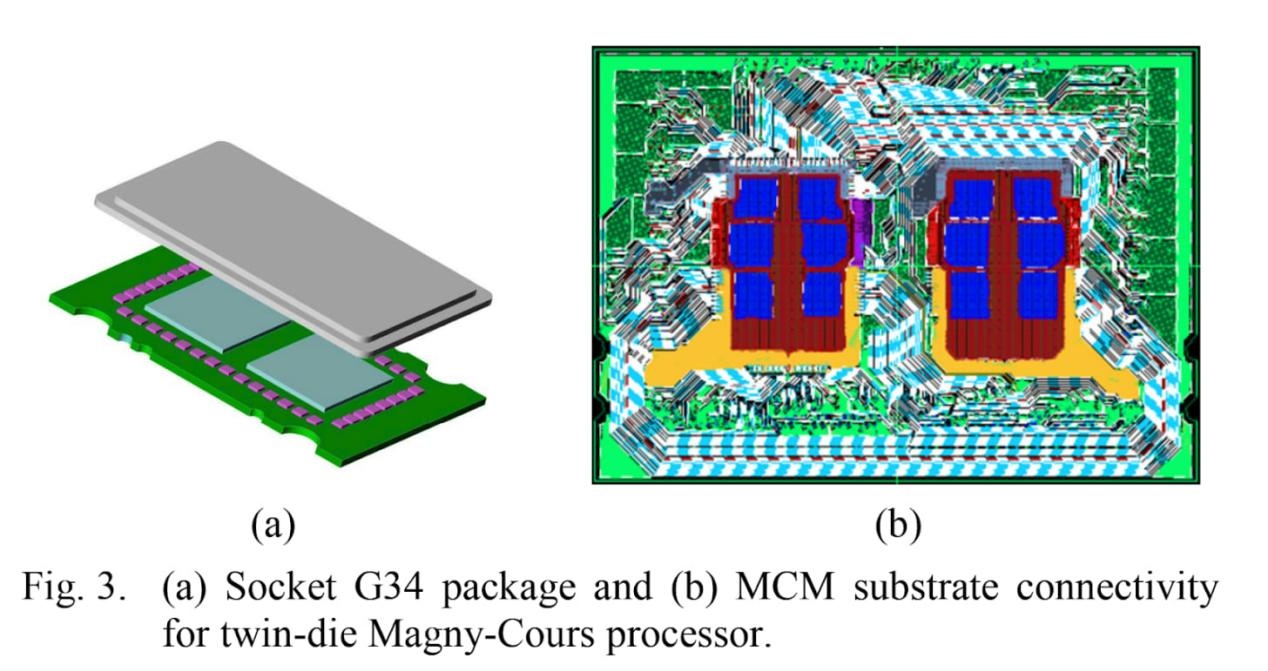
Magny Cours 的封装内链路设计颇为特殊。每个裸片有 4 个 HT 端口,每个端口宽 16 位,支持 “非绑定模式”(unganged mode)以拆分为两个 8 位子链路。两个裸片通过一条 16 位 “绑定链路”(ganged link)及另一个端口的 8 位子链路连接。但 AMD 从未启用过这条 8 位跨裸片链路,可能是因为额外带宽难以充分利用,且在非对称链路上交错流量的设计过于复杂。Magny Cours 采用第三代 HT 链路,最高速率达 6.4 GT/s,因此两个裸片间的带宽为 12.8 GB/s。若启用那条禁用的 8 位子链路,封装内带宽可提升至 19.2 GB/s。
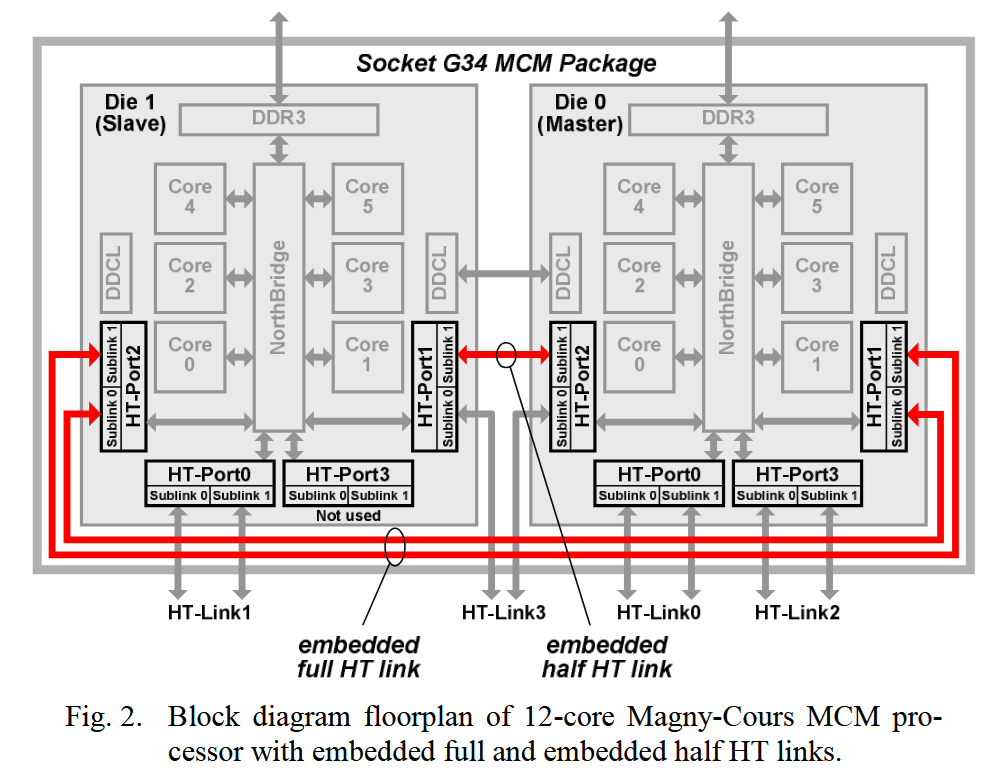
由于 1.5 个端口用于封装内连接,每个裸片剩余 2.5 个 HT 端口用于外部连接。AMD 借此为 G34 封装设计了 4 个外部 HT 端口:在单路或双路系统中,通常 1 个用于 IO,其余 3 个用于连接另一个插槽。
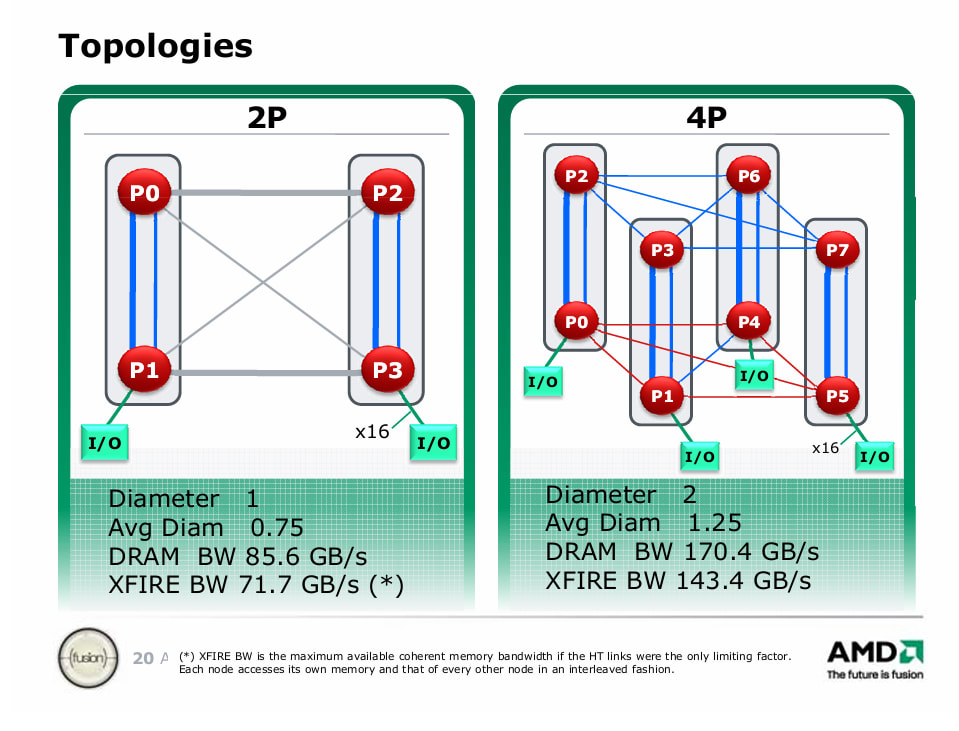
四路系统的设计则复杂得多,其链路分配需在 IO 带宽与跨插槽带宽间权衡。AMD 的幻灯片显示了一个基础方案:分配 4 条 16 位 HT 链路用于 IO,但也可仅让两个插槽连接 IO。
HyperTransport 性能
在我们测试的双路系统中,两个端口以 “绑定模式” 运行,连接两个插槽上的对应裸片;第三个端口以 “非绑定模式” 提供两条 8 位链路,分别连接第一插槽的裸片 0 与第二插槽的裸片 1,反之亦然。这形成了全连接网格拓扑,结构类似正方形,边缘链路带宽更高,对角线链路带宽较低。
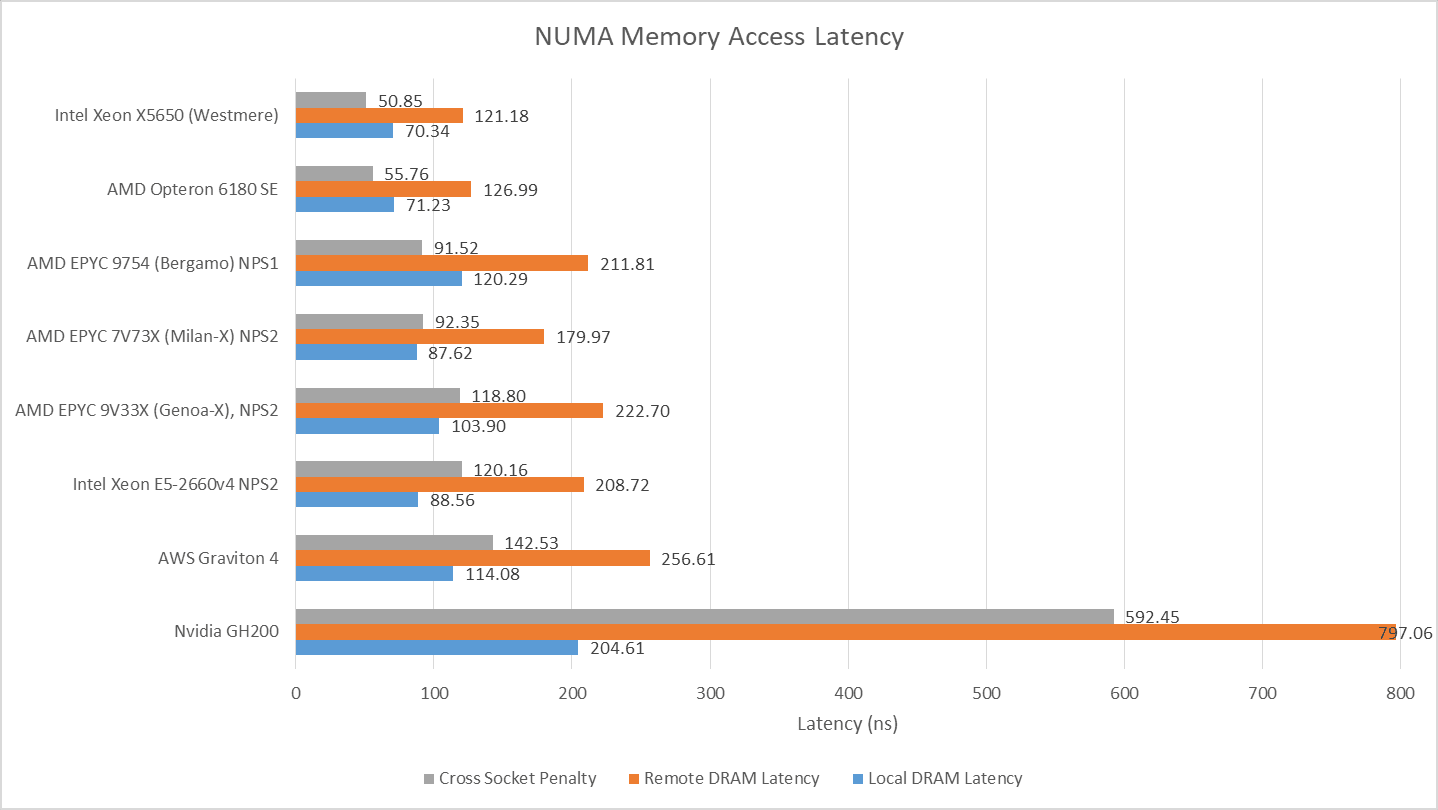
跨节点内存延迟为 120-130 纳秒,比本地内存访问约高 50-60 纳秒。Magny Cours 的延迟水平与较新的英特尔 Westmere 双路系统相当。这两款 2010 年前后的双路系统,无论本地还是远程访问延迟都显著低于现代系统,且远程访问相对于本地访问的延迟 penalty 也更低,说明当时的内存控制器和跨插槽链路延迟更低。
核心到核心延迟
与 AMD 前代架构一样,Magny Cours 的内存控制器(MCT)负责确保缓存一致性。它们可运行在广播模式下:每个内存请求都会触发 MCT 向所有节点发送探测信号。这种设计虽简单,但会产生大量探测流量,且因 MCT 需等待探测响应后才能从 DRAM 返回数据,导致 DRAM 延迟增加。由于多数内存请求无需访问其他缓存,AMD 引入了 “HT 辅助”(HT assist)功能:每个裸片预留 1MB L3 缓存作为探测过滤器。MCT 通过探测过滤器记录本地地址空间中哪些缓存行在系统中被缓存,以及缓存状态。
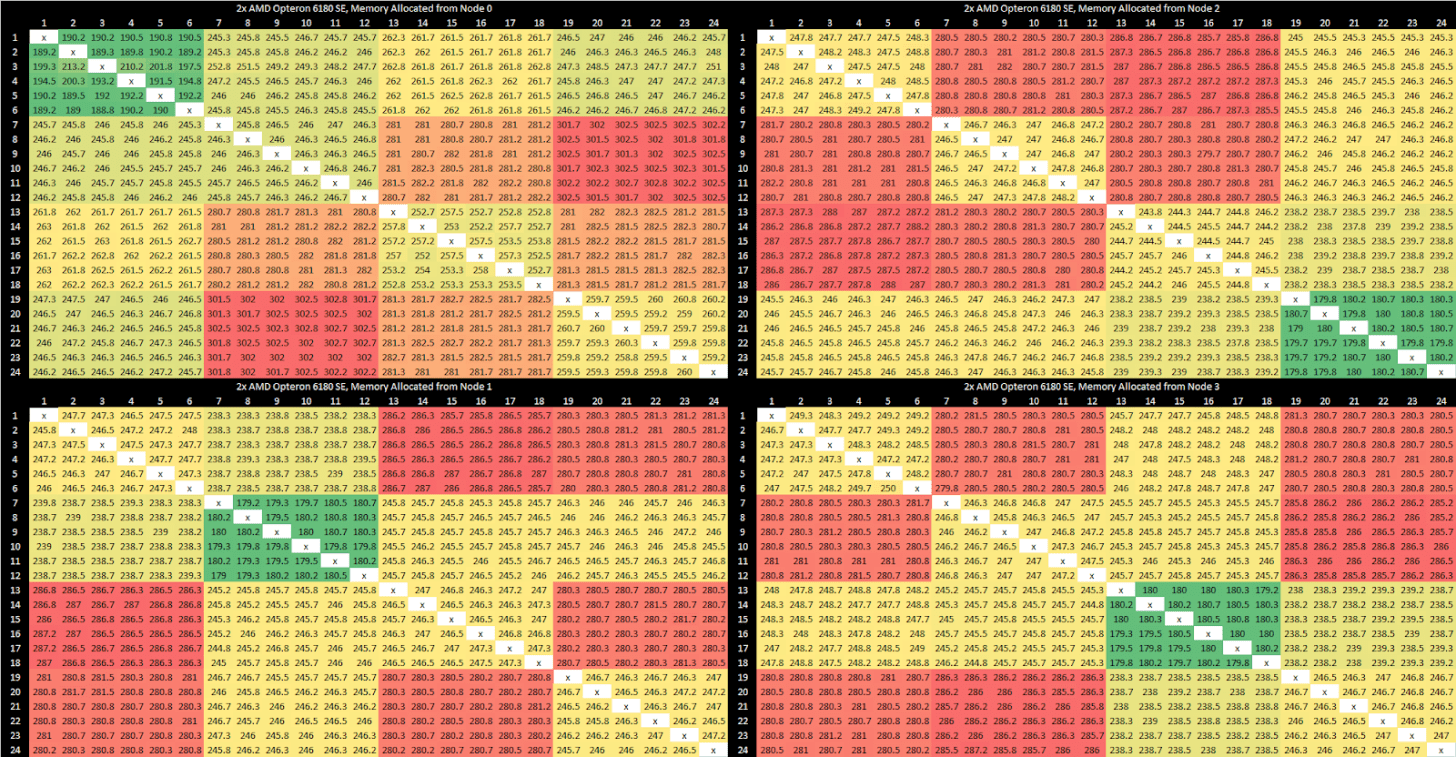
无论是否启用 HT 辅助,Magny Cours 的缓存一致性均由 MCT 全权负责。因此,核心到核心的数据传输必须由缓存行所属的 MCT 协调。若缓存行归属于另一个裸片,同一裸片上的核心可能需通过该裸片交换数据。同一裸片内的传输延迟约 180 纳秒,访问同一插槽内的另一个裸片时延迟增加约 50 纳秒;最糟情况下,当缓存行在三个裸片间跳转(两个核心位于不同裸片,由第三个裸片的内存控制器协调),延迟可超过 300 纳秒。
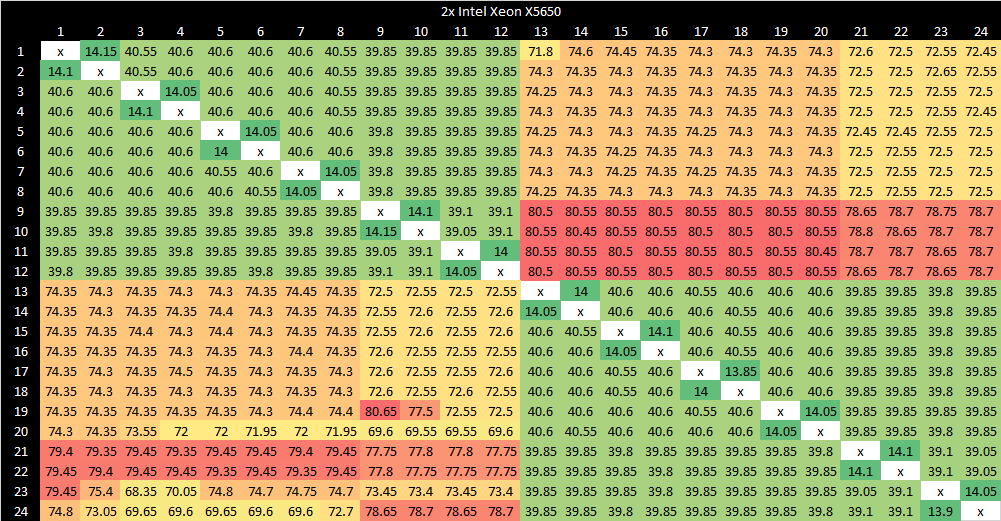
作为对比,英特尔稍晚的 Westmere 在 L3 缓存中使用核心有效位作为探测过滤器,即使地址归属于其他裸片,也能在同一裸片内完成核心到核心传输,且整体核心到核心延迟更低。
带宽
AMD 架构的带宽情况较为复杂:它是四节点系统,而 Westmere 是双节点系统,核心数仅为其一半。通过 16 位 HT 链路连接的 Magny Cours 节点间带宽约 5 GB/s,封装内链路性能略优于跨插槽链路;通过 8 位 “对角线” 跨插槽链路的跨节点带宽最低,约 4.4 GB/s。
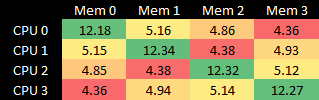
跨节点带宽(单位:GB/s)
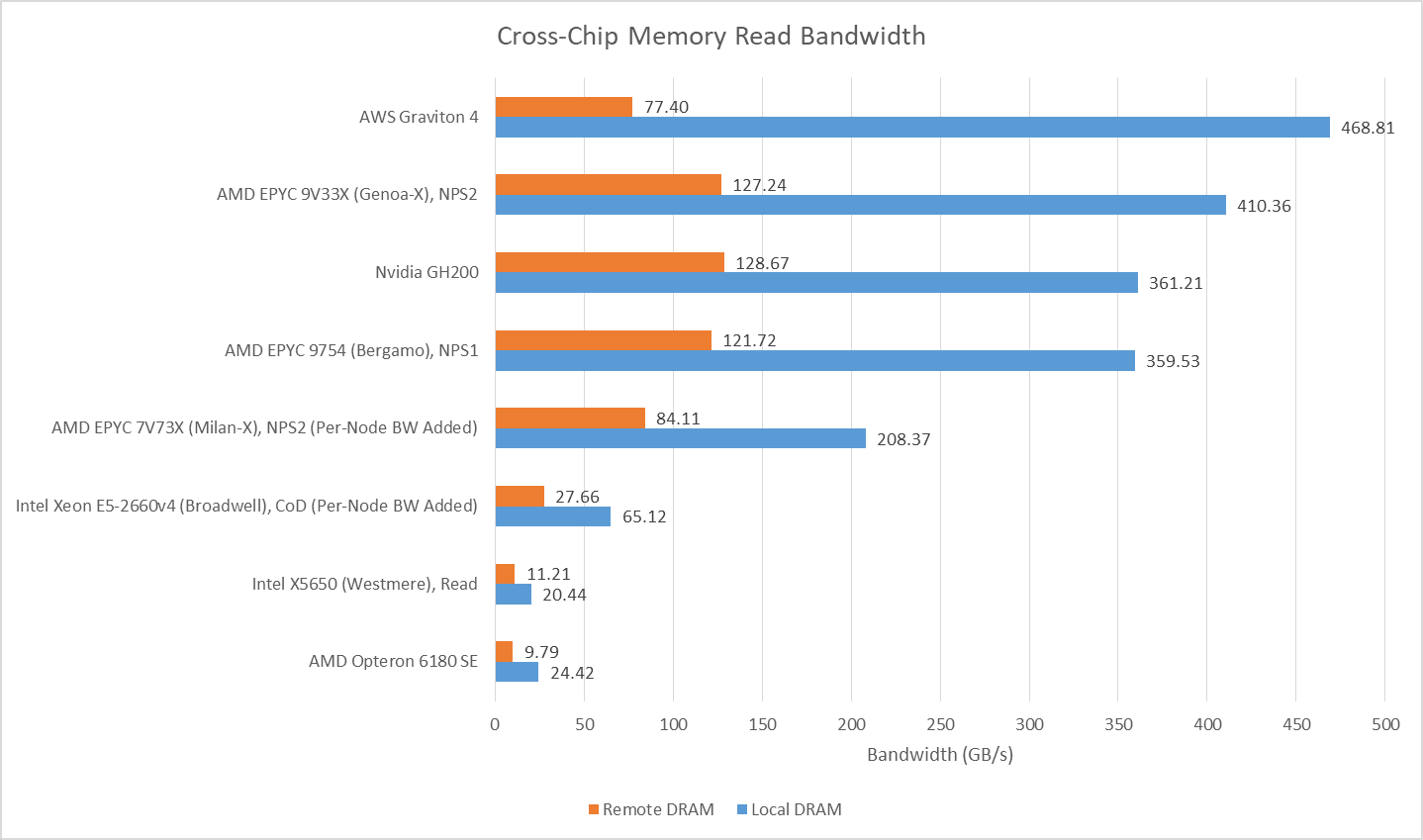
从单插槽读取另一插槽数据的速度来看,皓龙 6180 SE 与至强 X5650(Westmere)系统处于同一水平。当然,现代系统凭借更新的 DDR 版本、更宽的内存总线和改进的跨插槽链路,带宽已大幅提升。
值得注意的是,当两个插槽的核心均读取对方内存池时,跨插槽带宽可略超 17 GB/s,但需确保使用 16 位链路而非 8 位链路;若通过 8 位对角线链路测试,带宽仅为 12.33 GB/s。在一项复杂测试中,让每个裸片的核心通过 16 位链路读取另一个裸片的内存,总跨节点带宽可达到 19.3 GB/s。总结如下:
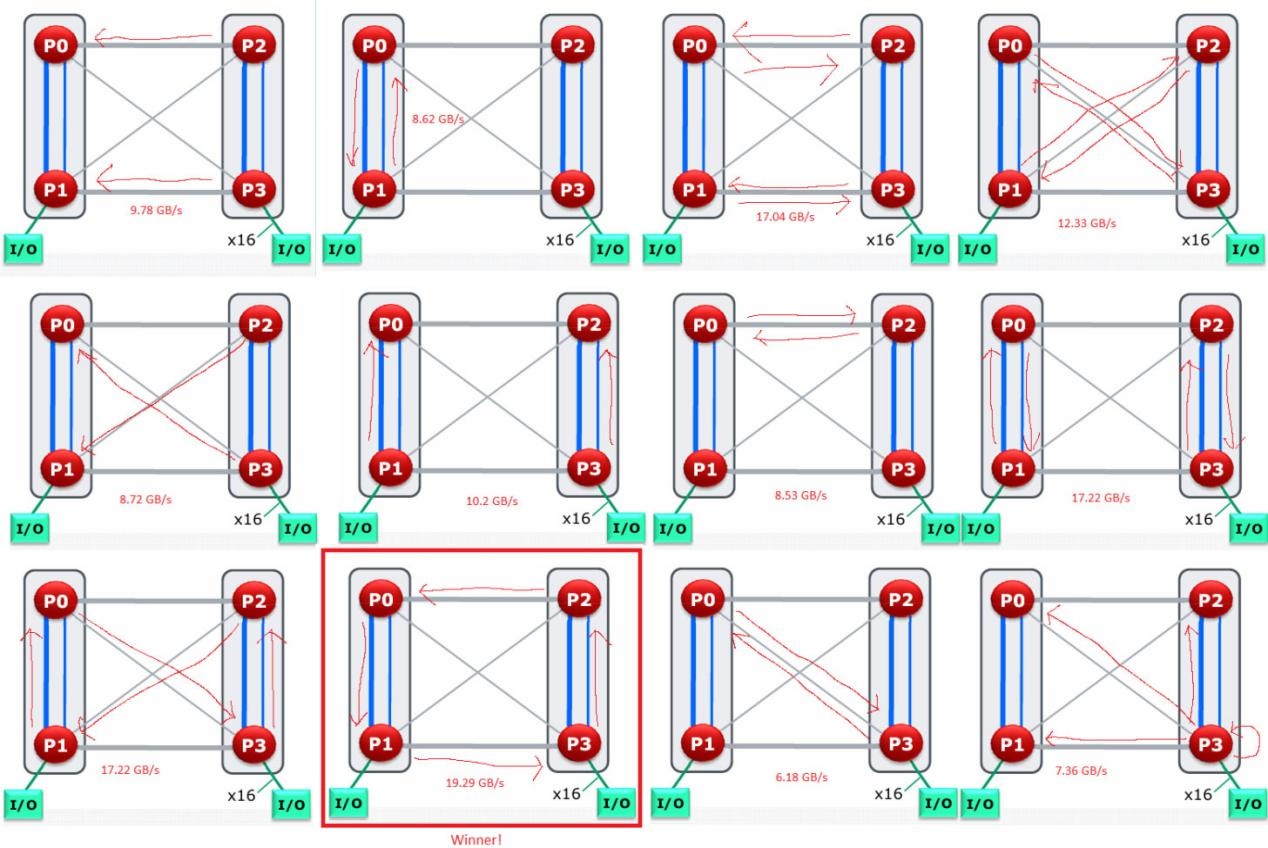
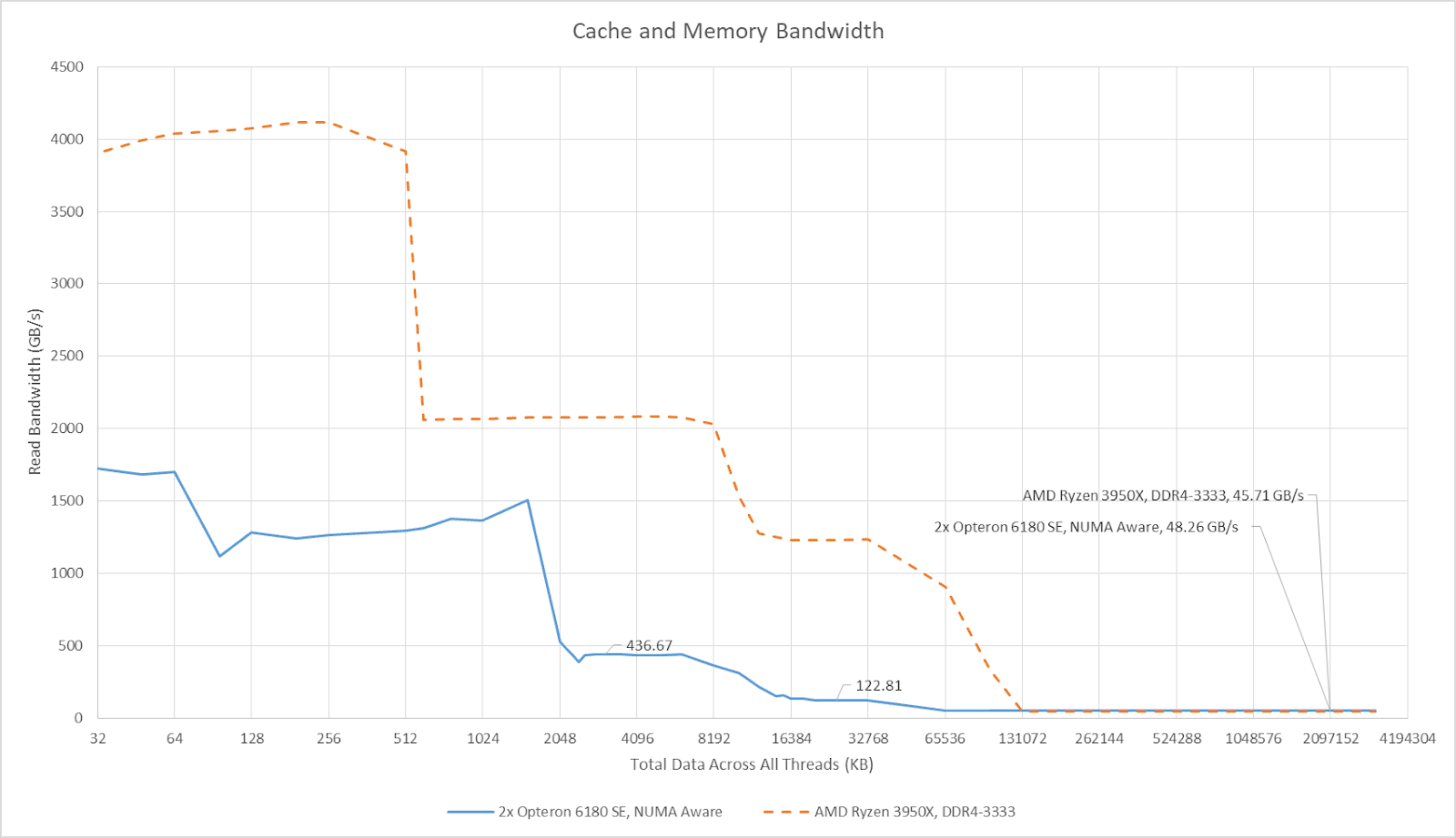
NUMA 感知应用自然会尽量保持内存访问本地化,减少通过 HyperTransport 链路的高成本访问。当所有核心访问直接连接的内存池时,整个系统的 DRAM 带宽可达到 48 GB/s 以上,这让这款老旧的皓龙系统拥有与相对现代的 Ryzen 3950X 相近的 DRAM 带宽。当然,新款 16 核处理器的缓存带宽更高,且无 NUMA 特性。
片内互连
Magny Cours 的片内网络(即北桥)负责将 6 个核心与本地内存控制器及 HyperTransport 链路连接。AMD 的北桥设计包含两个交叉开关:系统请求接口(SRI)和 XBAR。核心连接至 SRI,XBAR 则连接 SRI、内存控制器与 HyperTransport 链路。这种两级架构降低了每个交叉开关的端口数量。10h 架构 CPU 在 SRI 与 XBAR 间设有 32 项系统请求队列,多于早期 K8 皓龙的 24 项。在 XBAR 处,AMD 设计了 56 项 XBAR 调度器(XCS),用于跟踪来自 SRI、内存控制器和 HyperTransport 链路的命令。
交叉开关拓扑易于构建,天然支持有序网络和低延迟,适用于线数较少、节点数量不多的互连场景。
——Arm《AMBA 5 CHI 架构规范》(关于交叉开关、环形与网格互连的权衡)
AMD 早期片内网络的交叉开关设计在降低内存延迟方面表现出色:仅运行指针追逐测试时,基础内存延迟为 72.2 纳秒。而现代服务器芯片因互连更复杂,内存延迟常超过 100 纳秒。
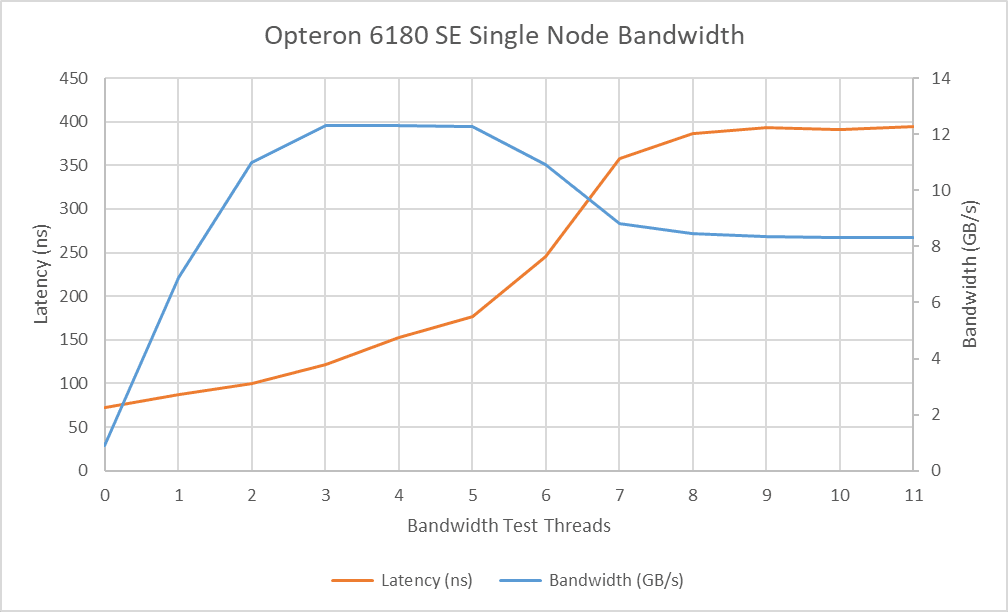
但随着带宽需求增加,互连架构在保证延迟敏感线程不被带宽密集型线程抢占方面表现平平。当同一裸片的其他 5 个核心产生带宽负载时,延迟增至 177 纳秒,是空载时的两倍多。通过 HyperTransport 连接的其他节点会加剧本地内存控制器的竞争:当其他裸片的核心读取同一内存控制器时,带宽降至 8.3 GB/s,而本地核心的延迟飙升至近 400 纳秒。

Magny Cours 仅需 3 个核心即可达到带宽上限(约 10.4 GB/s)。测试系统的每个节点配备双通道 DDR3-1333,理论上每节点 DRAM 带宽应为 21.3 GB/s,四节点总带宽 85.3 GB/s。但实际测试结果远低于此:即使 6 个核心全用于读取大数组,皓龙 6180 SE 的单个裸片性能仅略优于搭配 DDR2-800 的 Phenom II X4 945,甚至不及搭配高速 DDR2 的 Phenom X4 9950。这可能与北桥 1.8 GHz 的低频率、内存控制器的窄链路(可能为 64 位),或内存控制器队列深度不足难以掩盖 DDR 延迟有关。无论原因如何,Magny Cours 未能充分发挥 DDR3 的潜在带宽优势。这一问题在 Bulldozer 架构中得到解决,其 2.2 GHz 北桥可实现 20 GB/s 以上的带宽。
单线程性能:SPEC CPU2017
Magny Cours 的设计目标是高核心数,而非最大化单线程性能。皓龙 6180 SE 的核心频率为 2.5 GHz,北桥 1.8 GHz,甚至低于第一代 Phenom。由于在同一封装中集成两个桌面级裸片,AMD 需降低频率以控制功耗,因此单线程 SPEC CPU2017 得分并不理想:皓龙 6180 SE 略逊于英特尔后期的 Goldmont Plus 核心(最高频率 2.7 GHz)。
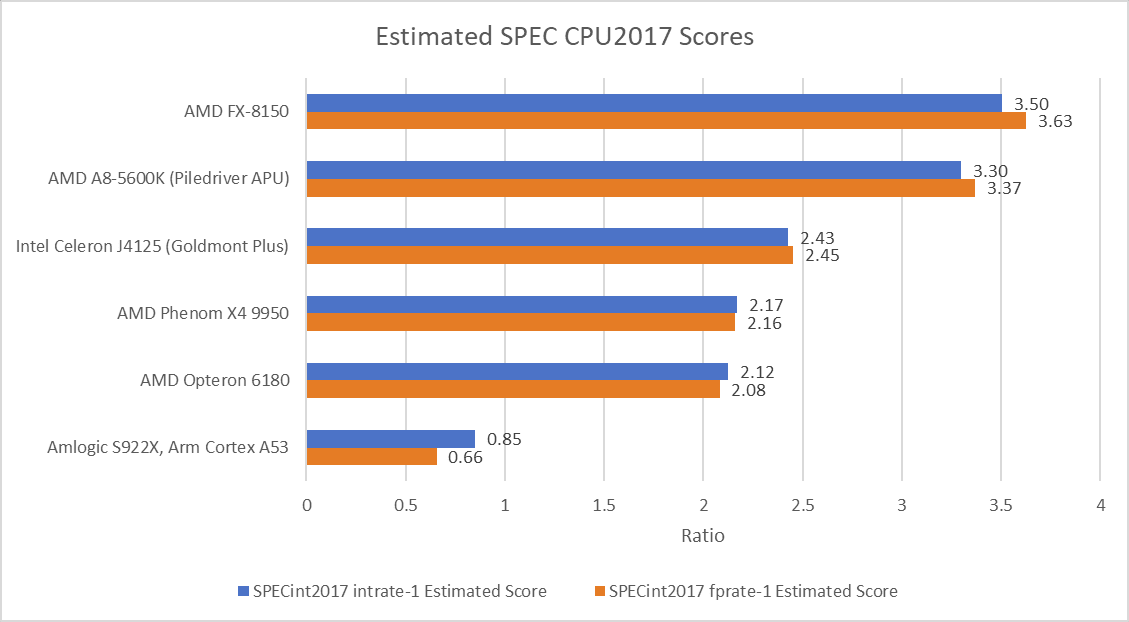
几年后的 AMD 客户端产品在 SPEC CPU2017 中表现更佳。较老的 Phenom X4 9950 在两个测试套件中均小幅领先:其 2 MB L3 缓存虽更小,但更高的频率(超频至 2.8 GHz 后优势明显)弥补了这一不足。尽管皓龙 6180 需预留 1 MB L3 作为探测过滤器(因此实际可用 L3 为 5 MB),但其 L3 命中率仍显著高于前代。
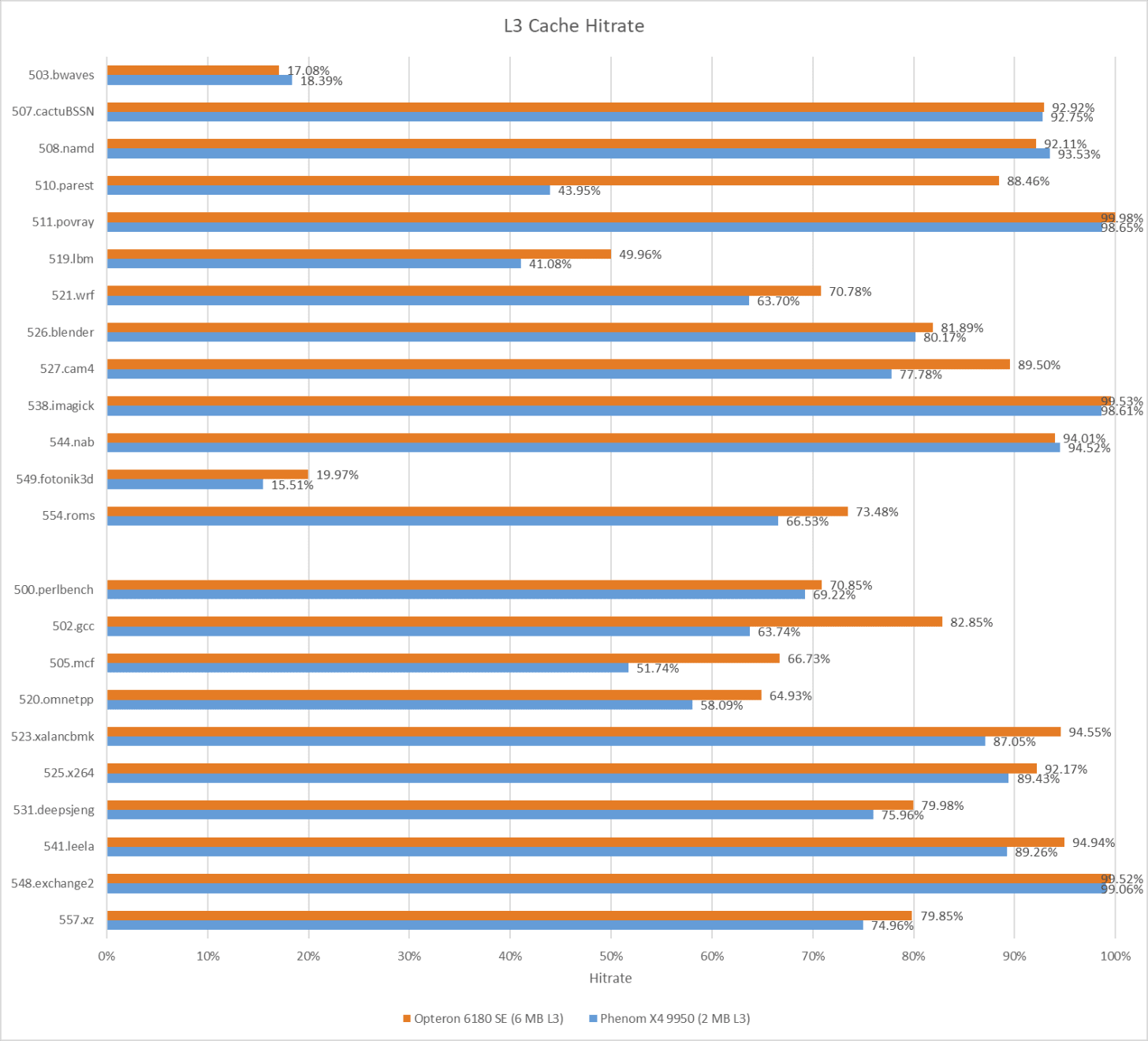
更大 L3 的优势因测试而异。510.parset 测试充分体现了大缓存的价值:皓龙 6180 SE 凭借命中率优势,比 Phenom X4 9950 领先 9.4%。反之,548.exchange2 是一款 IPC(每时钟周期指令数)高且数据足迹极小的测试,Phenom X4 9950 凭借 12% 的频率优势反超 11%。
结语
2000 年代末的技术限制让核心数扩展成为难题。Magny Cours 采用了一系列技术在提升核心数的同时控制成本:从 L3 中划分监听过滤器以减少裸片面积;在更高层面,AMD 通过复用小裸片覆盖不同市场,并通过堆叠相同裸片提升核心数,从而减少在产裸片的数量与尺寸。某种程度上,AMD 当时的策略与现在一脉相承 —— 均致力于通过复用小裸片实现多场景适配。
尽管成本低,但这种设计也有弊端:每个六核裸片都是独立单元(含核心与内存控制器),因此 Magny Cours 的最佳性能依赖 NUMA 感知软件。英特尔在提升核心数时同样面临 NUMA 问题,但八核 Nehalem-EX 与十核 Westmere EX 的每个 NUMA 节点拥有更多核心与内存带宽。AMD 的 HyperTransport 与低延迟北桥设计确实降低了 NUMA 跨节点成本(跨节点内存延迟低于现代设计),但相比英特尔,它对 NUMA 感知软件的依赖更强。
深入分析后可见 Magny Cours 的诸多特性:DDR3 系统的带宽表现未达预期,北桥在高带宽负载下难以保证公平性,四节点全连接架构中 “对角线” 链路带宽更低。这些特性虽增加了调优难度,但在 2010 年前的核心数扩展挑战下,实属正常。
不过 Magny Cours 的经验为 AMD 后续数代产品的扩展性奠定了基础:AMD 继续通过复用小裸片覆盖服务器与客户端市场,并通过增加裸片数量提升核心数。即使是 Bulldozer 架构的皓龙,仍沿用 “四插槽 + 每插槽 2 裸片” 的设计,直至 Zen1 才完成终极进化 —— 每插槽 4 裸片,并以 Infinity Fabric 取代北桥与 HyperTransport 的组合。如今,AMD 的多裸片策略进一步发展,通过 IO 裸片与计算复合体裸片(CCD)的组合实现更统一的内存访问。
本文转自媒体报道或网络平台,系作者个人立场或观点。我方转载仅为分享,不代表我方赞成或认同。若来源标注错误或侵犯了您的合法权益,请及时联系客服,我们作为中立的平台服务者将及时更正、删除或依法处理。




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
联系电话:
010-61853490
新闻投稿:
server@icviews.cn
商务合作:
business@icviews.cn
问题反馈:
19800315212(微信同号)


半导纵横公众号

半导纵横小程序