DPU与GPU ,边缘AI怎么选?
随着边缘人工智能用例的增长——从智能相机和机器人到汽车和工业自动化——嵌入式工程师面临一个基本问题:如何在紧张的功率、延迟和成本预算内有效地加速人工智能推理?
GPU是一种专门设计用于处理图形和并行计算任务的处理器。它可以同时处理多个数据并行计算任务,使得它在图形渲染、深度学习和科学计算等领域具有优势。
虽然 GPU 长期以来一直是 AI 工作负载的首选解决方案,但 DPU(深度学习处理单元)和类似的神经处理引擎(NPU、NPU、Edge TPU)为深度学习提供了引人注目的替代方案。
所谓DPU,或者称作数据处理单元,它是最新发展起来的专用处理器的一个大类,是继CPU、GPU之后,数据中心场景中的第三颗重要的算力芯片,为高带宽、低延迟、数据密集的计算场景提供计算引擎。DPU正迅速成为现代计算中的重要组成部分,能够帮助CPU分担数据相关工作负载以提升数据中心的整体效率和性能。
本文比较了用于边缘推理的 DPU 和 GPU,帮助您根据性能、效率和集成要求选择正确的架构。
什么是DPU(深度学习处理单元)?
DPU 是一种专用硬件加速器,针对神经网络中的矩阵运算和张量计算进行了优化。它具有以下特点:
- 高度并行但特定于应用程序。
- 集成到 SoC 或独立 IP 块中。
- 针对低延迟、低功耗推理进行调整。
例子:
- Xilinx AI 引擎/DPU(在 Versal 或 Zynq Ultrascale+ MPSoC 中)。
- Hailo-8 AI处理器。
- 耐能 KL520。
- 带有 AI 扩展的 Cadence Tensilica Vision Q7 DSP。
DPU 是专为深度学习推理而设计的加速器,与通用 GPU 相比,它为特定 AI 任务提供更高的能效和更低的延迟。对于性能受限的边缘设备来说,它是理想之选。
GPU 作为边缘 AI 加速器
GPU 在边缘推理中仍然很常见,因为:
- 成熟的 CUDA 生态系统(NVIDIA Jetson)。
- 灵活适用于多种型号。
- 更好地支持浮点精度和更大的批量大小。
边缘使用的缺点:
- 功耗更高(1-15W+)。
- 通用性限制了小型模型的效率。
- 低成本嵌入式 SoC 集成度较低。
热门边缘 GPU:
- NVIDIA Jetson Orin Nano/NX/Xavier。
- AMD Kria KR260(GPU + FPGA)。
DPU 与 GPU 比较
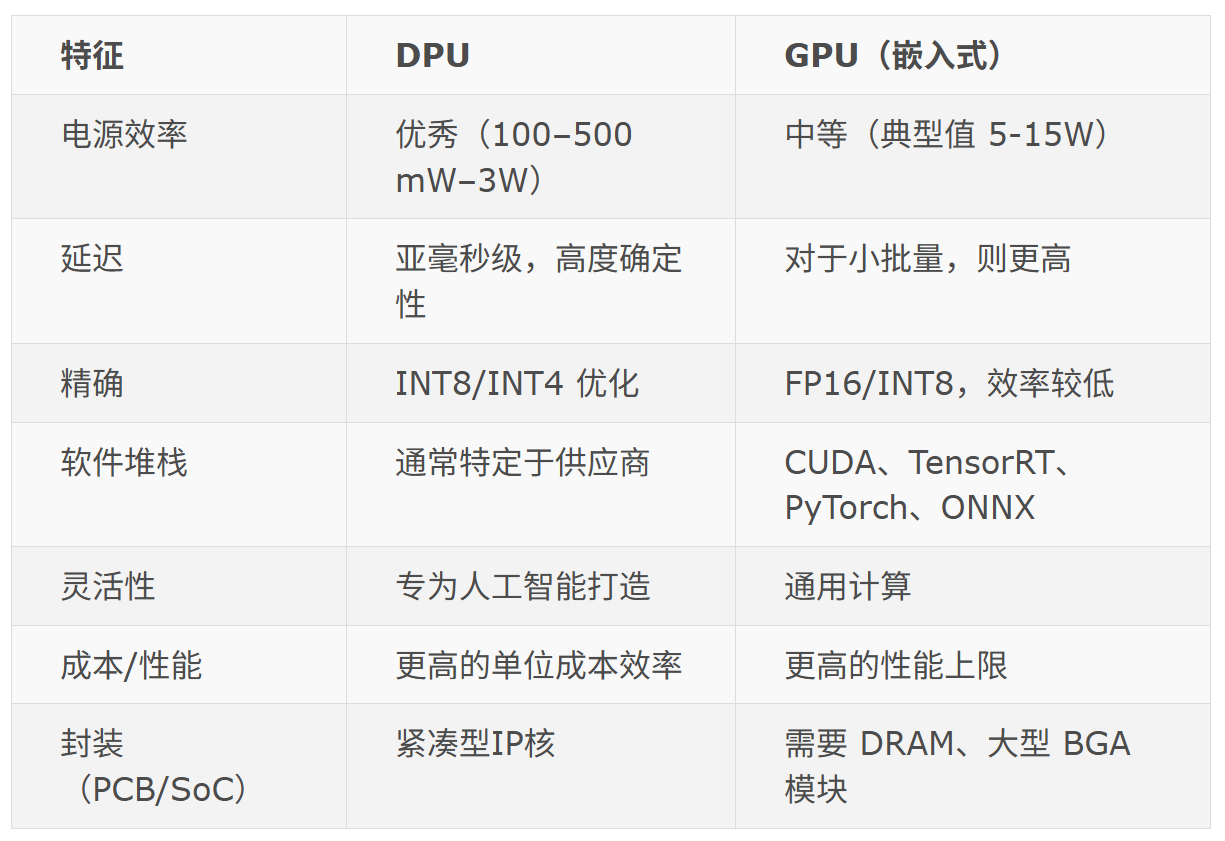
关键设计权衡
1. 模型复杂度
DPU:最适合量化 CNN、中小型模型(例如 MobileNet、YOLOv5n)。
GPU:更适合大型模型(例如 ResNet-50、Transformers)。
2. 批次大小和吞吐量
DPU:针对低批量和实时处理(例如视频逐帧)进行了优化。
GPU:需要批处理才能充分利用核心,从而增加延迟。
3. 热预算和外形尺寸
DPU:通过被动冷却实现超紧凑设计。
GPU:通常需要散热器或主动冷却,即使是嵌入式形式。
4.软件生态系统
DPU:可能需要转换为特定于供应商的格式。
GPU:具有现有模型的强大生态系统(TensorFlow Lite、ONNX、PyTorch)。
DPU 比 GPU 更节能,更适合在无人机、智能相机和手持仪器等电池受限的设备上进行实时推理。
部署场景
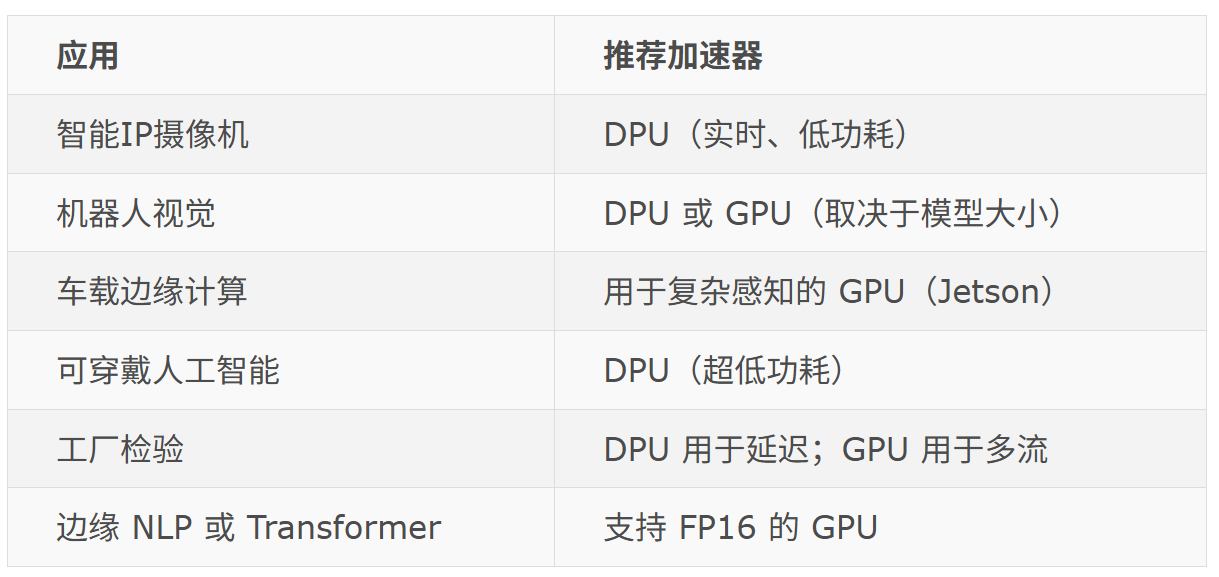
接口和集成
DPU 通常位于 FPGA 上或作为 SoC 中的硬 IP。
需要优化的模型转换工具(Vitis AI、TFLite 转换器)。
在某些设计中,GPU 需要外部 DRAM 和 PCIe 接口。
开发工具链
对于 DPU:
- Xilinx Vitis AI(Zynq/Versal)。
- Hailo SDK。
- Cadence AI Studio。
- 适用于 Edge TPU 的 TensorFlow Lite。
对于 GPU:
- NVIDIA TensorRT + CUDA。
- JetPack SDK。
- PyTorch/TensorFlow GPU 构建。
将架构与应用相匹配
对于边缘 AI 来说,DPU 和 GPU 之间没有绝对的赢家。选择取决于以下因素:
- 模型类型(CNN 与 Transformer)。
- 功率预算(mW 与 W)。
- 延迟容忍度。
- 软件集成。
- 部署量和成本。
一般来说:
- 使用 DPU 对量化模型进行实时、低功耗推理。
- 使用 GPU 实现复杂模型和开发灵活性。
为什么选择 Promwad?
Promwad 支持各种边缘 AI 架构的客户——从基于 GPU 的 Jetson 解决方案,到基于 DPU 的 FPGA 和定制 ASIC。我们能够提供以下帮助:
- AI硬件架构选择。
- DPU/GPU 集成和工具链设置。
- 嵌入式Linux和RTOS驱动程序开发。
- 模型优化与量化。
- AI性能和热调节。
DPU能够与CPU和GPU协同工作,负责增强计算能力并处理日益复杂的现代数据工作负载。
随着全社会对AI、机器学习、深度学习、物联网、5G及复杂云架构需求的增加,DPU市场也在稳步增长。
本文转自媒体报道或网络平台,系作者个人立场或观点。我方转载仅为分享,不代表我方赞成或认同。若来源标注错误或侵犯了您的合法权益,请及时联系客服,我们作为中立的平台服务者将及时更正、删除或依法处理。

联系电话:
010-61853490
新闻投稿:
server@icviews.cn
商务合作:
business@icviews.cn
问题反馈:
19800315212(微信同号)


半导纵横公众号

半导纵横小程序