国产CPU兆芯KX-7000,深度解析
作为我国少数掌握x86-64架构核心技术的半导体企业,兆芯近日发布了备受瞩目的开先KX-7000系列处理器。该产品搭载全新"世纪大道"微架构,标志着国产CPU在自主创新之路上迈出重要一步。值得一提的是,"世纪大道"不仅是上海浦东的核心地标,更延续了兆芯以上海城市地标命名处理器架构的独特传统。
兆芯成立于2013年,由威盛科技与上海市政府合资成立。故而兆芯完整继承了威盛的x86-64指令集授权,兆芯处理器既能保持与 x86生态系统的完全兼容,又可依托自主架构实现性能突破。
不过,x86-64兼容性仅仅是基础,性能同样非常关键。因为,兆芯前代架构“陆家嘴”(LuJiaZui,用于KX-6640MA)已难以应对现代应用需求。陆家嘴是2发射宽度的核心,主频低于3 GHz,乱序执行能力仅略强于英特尔1997年的Pentium II。而世纪大道架构正为直击这一性能痛点而来。
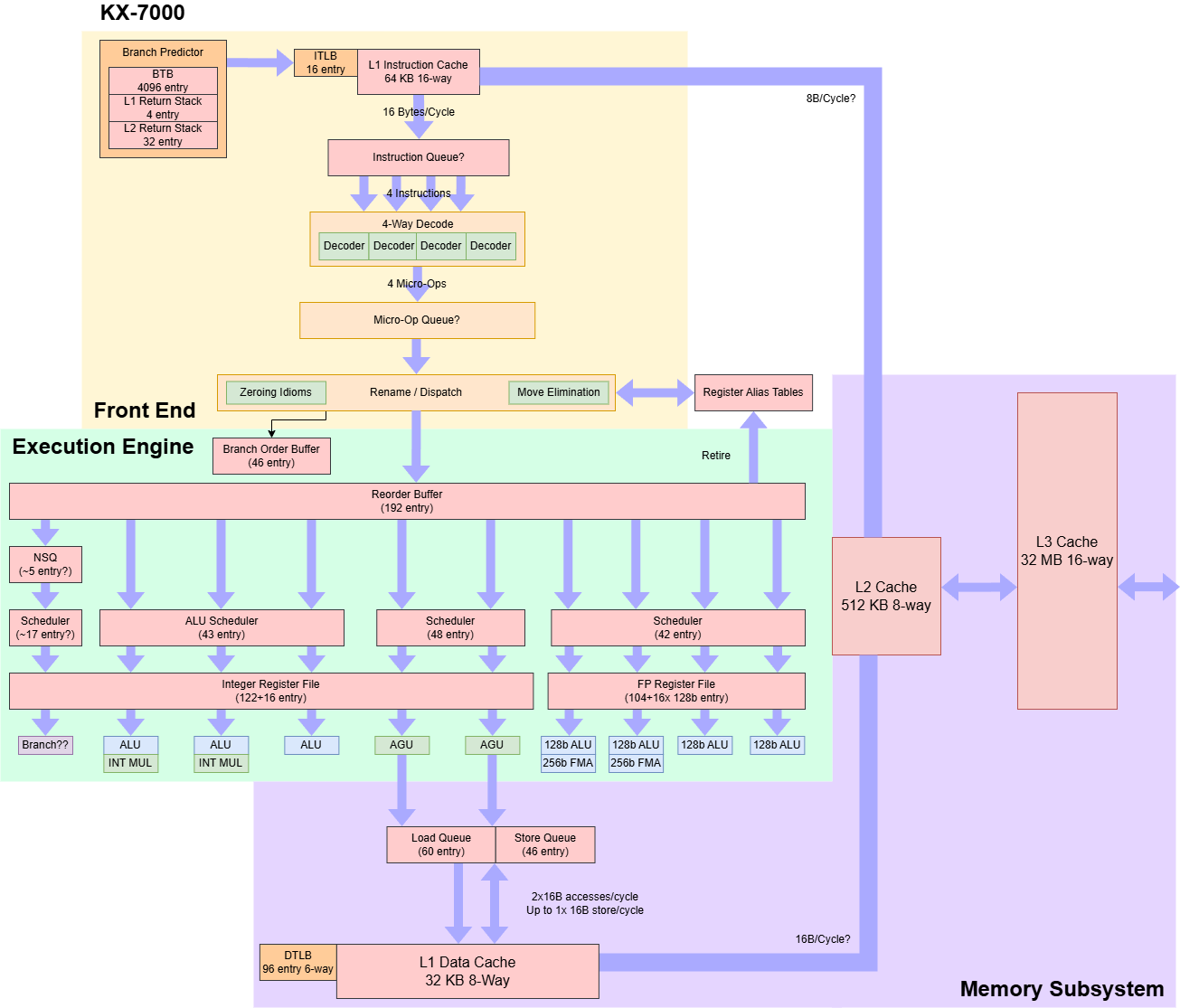
核心概览
世纪大道是支持AVX2的4发射宽度核心,其乱序执行窗口与2010年代初的英特尔CPU相当。兆芯不仅扩展了核心宽度并增强延迟容忍度,还致力于提升主频。KX-7000运行频率为3.2 GHz,显著高于KX-6640MA的2.6 GHz。兆芯官网称KX-7000可达3.5-3.7 GHz,但实际测试中未观察到其超过3.2 GHz。
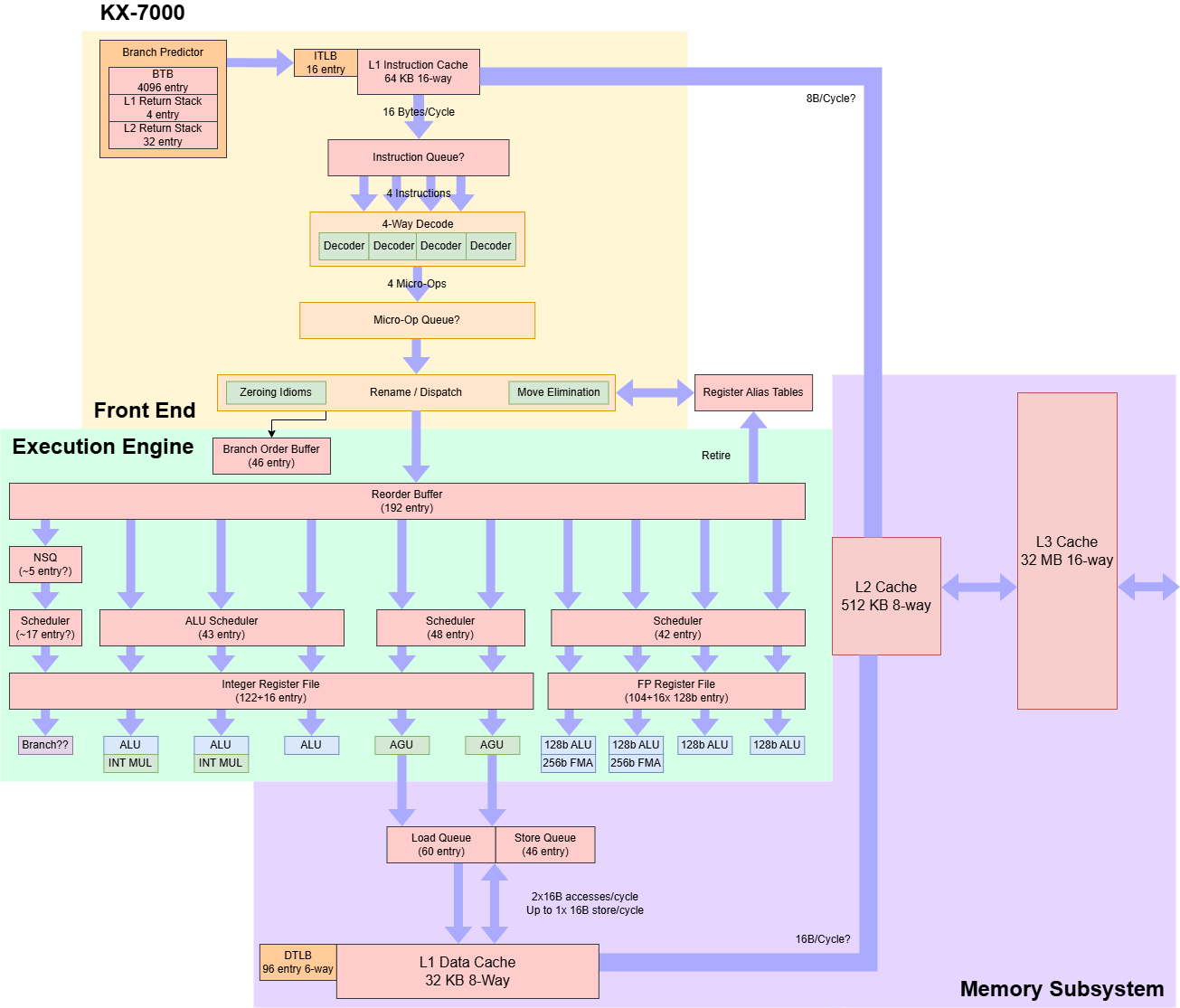
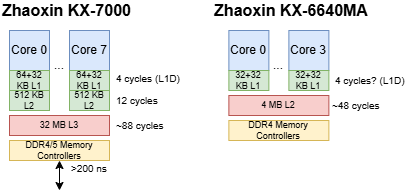
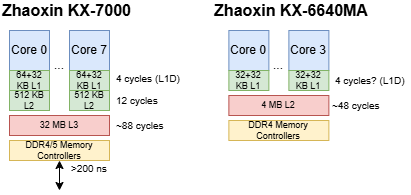
KX-7000包含8个世纪大道核心,采用类似AMD单CCD锐龙桌面处理器的Chiplet设计。所有核心位于同一芯片上,共享32 MB三级缓存,另有一独立IO芯片负责连接DRAM和其他外设。兆芯未公开制程节点,Techpowerup与Wccftech推测其采用未指明的16nm工艺。
前端设计
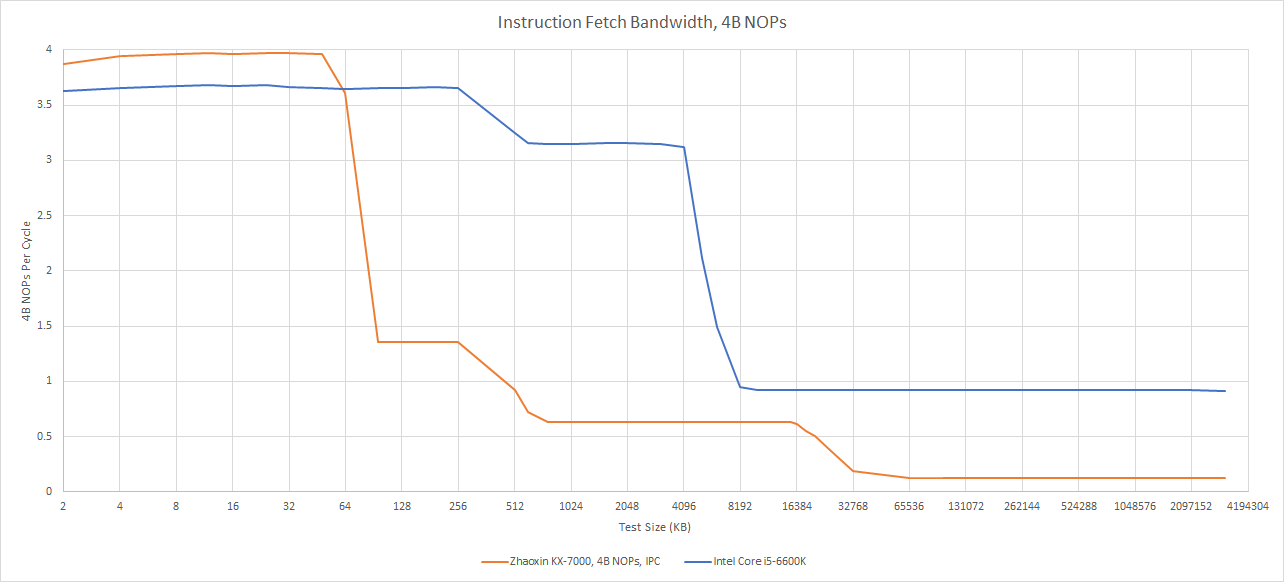
前端部分,指令从64 KB 16路组关联指令缓存(L1i)中提取。该缓存每周期提供16字节数据,供给4路解码器。世纪大道采用完全传统的前端设计,未配备循环缓冲区或微操作缓存。若平均指令长度超过4字节,指令缓存带宽可能成为前端吞吐量的瓶颈。
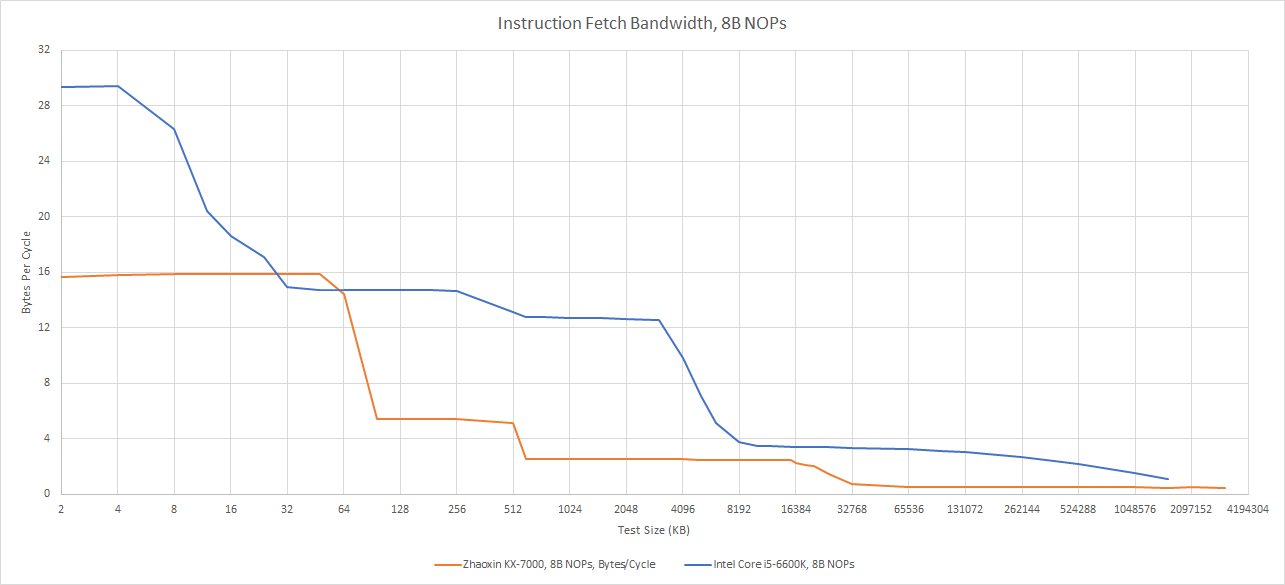
当代码超出L1i时,前端带宽急剧下降,这与2010年代的西方设计形成对比。例如Skylake可从L2缓存以每周期超12字节获取代码,足以支撑4字节指令下>3 IPC。若代码进入L3,世纪大道前端带宽进一步降至每周期不足4字节。
4096项的分支目标缓冲区(BTB)提供分支目标地址,但在分支跳转后会产生两个流水线气泡。即便分支数远低于4096,一旦测试溢出L1i,分支跳转延迟仍会骤增。BTB可能绑定于L1i,因此无法在L1i未命中时进行长距离预取。
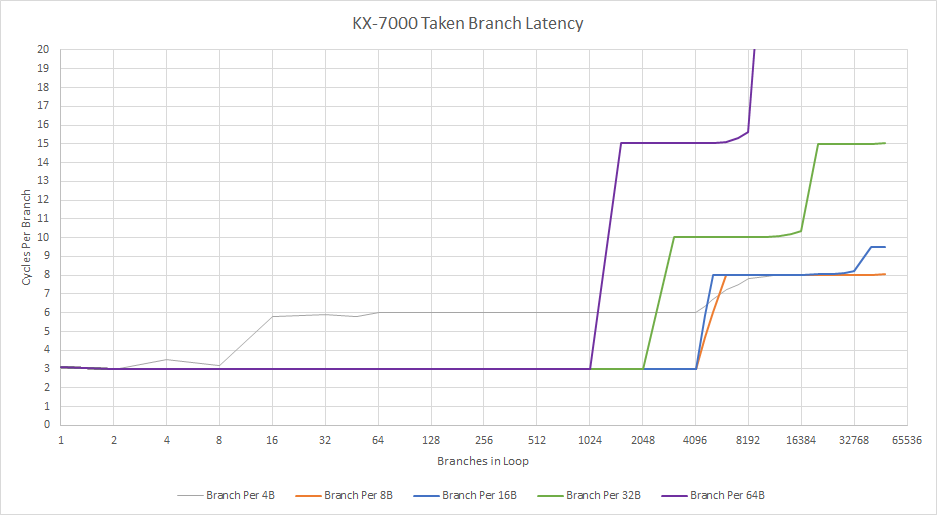
世纪大道的分支表现让人联想到威盛Nano等旧核心。相比陆家嘴通过16项L0 BTB实现零气泡分支,世纪大道反而退步。兆芯可能认为在3 GHz+目标下无法实现零气泡分支,但十多年前的英特尔/AMD CPU在更高主频下已具备更快分支目标缓存了。
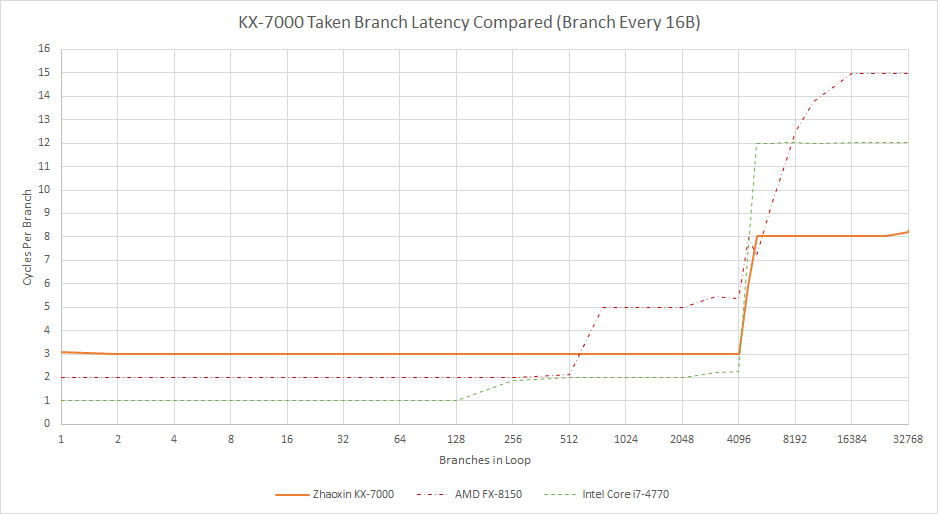
优势方面,世纪大道的方向预测器模式识别能力大幅提升。面对重复分支模式时,KX-7000表现接近英特尔的Sunny Cove。

返回预测与陆家嘴类似:当调用-返回对深度≤4时延迟合理,更深时出现拐点,暗示存在约32项的第二级返回栈。若存在,其速度较慢,每次调用-返回需14周期。而Bulldozer在返回栈未溢出24项前保持快速响应。
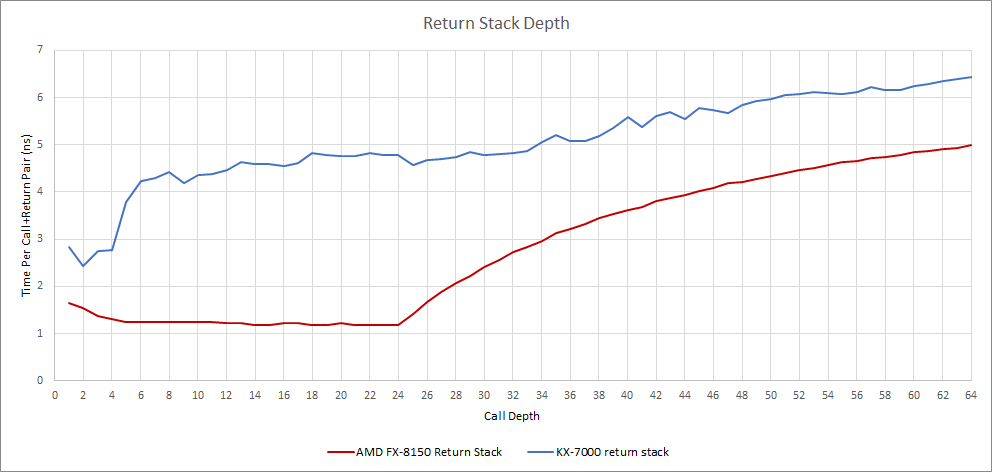
世纪大道前端以简单设计实现每周期最多4指令。传统取指-解码方案若优化得当,应本无问题,但其存在明显短板:AVX2代码因VEX前缀导致平均指令长度超4字节。AMD曾通过提升L1i至32B/周期(10h架构)解决,英特尔则在酷睿2中引入循环缓冲区,后于Sandy Bridge改用微操作缓存(同时保持16B/周期带宽)。兆芯未采用任何类似方案,也未实现AMD/英特尔沿用十余年的分支融合技术,导致如[add, add, cmp, jz]指令序列的IPC低于3。
分支目标缓存的简陋设计进一步凸显问题:单级BTB实际延迟3周期,这在当今显得过时,尤其当其绑定指令缓存时。当然,解耦BTB并非唯一方案,如苹果M1的BTB虽耦合L1i,但以192 KB超大L1i弥补。世纪大道的64 KB L1i虽大于多数x86-64核心的32 KB,却未像苹果般以蛮力应对大代码量。公允地说,Bulldozer也曾以64 KB L1i搭配低L2代码带宽,但2024年后仍保留3周期分支跳转延迟(尤其主频<4 GHz时)实难辩解。
重命名与分配
前端生成的微操作(μop)被分配至后端追踪结构,以支持乱序执行所需的簿记工作。寄存器分配与重命名同步进行——当指令写入寄存器时分配新物理寄存器以消除假依赖。重命名/分配阶段还可进行其他优化,为后端暴露更多并行性。
世纪大道能识别“寄存器自异或清零”等惯用操作,并告知后端其独立性。但此类异或操作仍受限于每周期3次,暗示其占用ALU端口。重命名器仍会分配物理寄存器存储结果(即使结果恒为零)。移动消除(Move Elimination)同样有效,但也限每周期3次。
乱序执行
兆芯转向基于物理寄存器文件(PRF)的执行方案,摒弃陆家嘴的ROB(重排序缓冲区)设计。独立寄存器文件减少核内数据传输,并允许ROB规模独立于寄存器文件容量。这些改进使世纪大道的乱序能力数倍于前代:其192项ROB理论上与Haswell、Zen及Centaur CNS相当,远胜陆家嘴的48项ROB。

ROB大小仅限制后端对停滞指令的前瞻范围。实际乱序能力受限于最先耗尽的资源(如寄存器文件、内存排序队列等)。世纪大道的寄存器文件小于Haswell/Zen,但仍可维持合理数量的分支与内存操作在流水线中。
世纪大道采用半统一调度器设计,不同于陆家嘴的分布式方案。ALU、内存和FP/向量操作各自拥有超过40项的大型调度器,分支可能有独立调度器(但未必专用端口)。测试中无法在同一周期执行未跳转分支与三次整数加法。尽管执行端口更多,调度队列数量却少于前代,减少了调优复杂度。
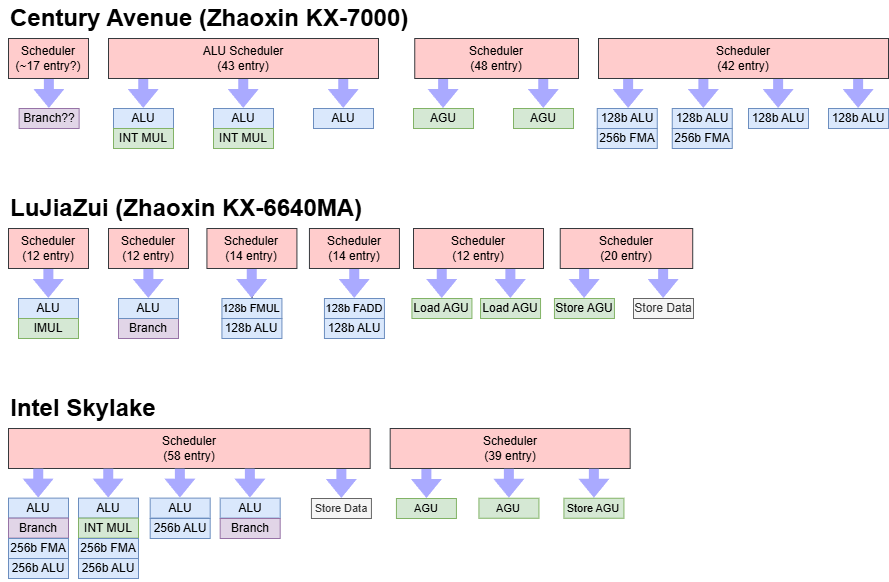
通常,统一调度器能以更少总条目数实现与分布式设计相近的性能。其条目可为任意端口保留微操作,降低单一队列满载阻塞指令的风险。凭借多个大型多端口调度器,世纪大道的调度容量超过Haswell、Centaur CNS甚至Skylake。
执行单元
三个ALU流水线处理标量整数运算。世纪大道由此与Arm Neoverse N1、英特尔Sandy Bridge并列,成为四发射核心中配备三ALU端口的设计。其中两个ALU含整数乘法器,64位整数乘法仅需2周期延迟,整数乘性能优异。
FP/向量单元表现亮眼:含四个流水线,均可执行128位向量整数加法;浮点运算每周期完成两次,甚至256位向量FMA指令亦能维持该速率,使得每周期FLOP数与Haswell持平。浮点加法/乘法延迟3周期,FMA延迟5周期,向量整数加法延迟仅1周期。
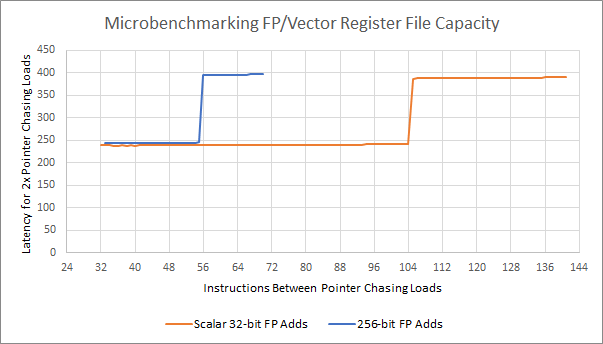
然而,世纪大道执行引擎对AVX2的支持并不彻底:测试中,所有256位向量指令均被拆分为两个128位微操作。例如256位浮点加法需占用两项ROB、两项调度器条目,结果消耗两项寄存器文件条目。内存方面,256位加载/存储各需两项加载/存储队列条目。兆芯的AVX2策略与Zen 4的AVX-512相反:AMD保持执行吞吐量不变,但通过512位寄存器文件提升任务并行度;而世纪大道优先提升执行吞吐量,再考虑如何有效供给数据。
核心内存子系统
内存访问始于两个地址生成单元(AGU),负责计算虚拟地址。AGU由48项调度器条目驱动,可能对应48项统一调度器或两个24项队列。
AGU生成的48位虚拟地址随后转换为46位物理地址。数据侧地址转换缓存在96项、6路组关联的数据TLB(DTLB)中。2 MB大页使用独立的32项、4路DTLB。世纪大道未通过CPUID报告L2 TLB容量,DTLB未命中会增加约20周期延迟——这一数值高于其他配备二级TLB的核心(Bulldozer除外)。

除地址转换外,加载/存储单元需处理内存依赖。世纪大道似乎通过虚拟地址进行初步依赖检查,导致加载对偏移4 KB的存储产生假依赖。对真实依赖,其存储转发延迟为5周期;部分重叠时快速转发失败,需22周期惩罚(属正常范围)。对独立访问,世纪大道支持酷睿2风格内存歧义消除,允许加载先于地址未知的存储执行,提升流水线利用率。
跨缓存行的“未对齐”加载/存储需12-13周期,与现代核心相比代价高昂(如Skylake未对齐加载几乎无惩罚,存储仅1周期惩罚)。若加载依赖于未对齐存储,世纪大道惩罚最高(>42周期)。
核心私有缓存
世纪大道配备32 KB 8路组关联数据缓存(L1D),含两个128位端口,加载到使用延迟4周期。仅一个端口处理存储,故256位存储需两周期完成。其L1D带宽与Sandy Bridge相似,但FMA能力对带宽需求更高。英特尔在Haswell首次支持双256位FMA时,将L1D带宽提升至每周期双256位加载+单256位存储。
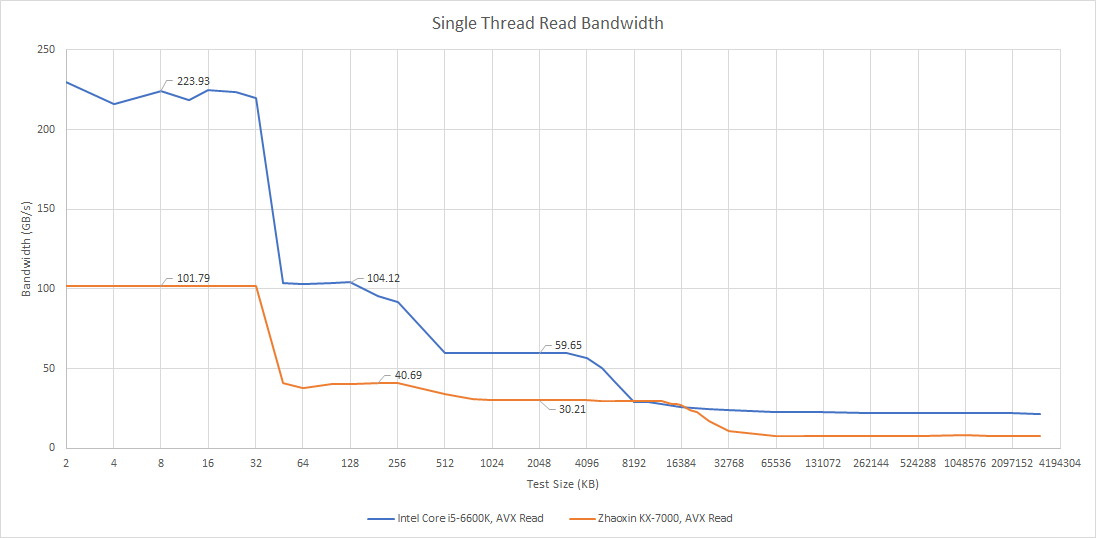
L2延迟为15周期,表现平平。对比Skylake-X的2 MB L2(14周期延迟,主频更高)可见差距。
共享缓存与系统架构
为提升多核扩展性,世纪大道的系统架构全面改进。KX-7000采用三级缓存设计,与AMD、Arm及英特尔高性能方案一致。核心私有L2缓存减少L1未命中对高L3延迟的敏感度,从而允许更大规模共享L3(从陆家嘴的4 MB L2增至32 MB L3,8核共享)。结合Chiplet设计,KX-7000类似单CCD的Zen 3桌面处理器。
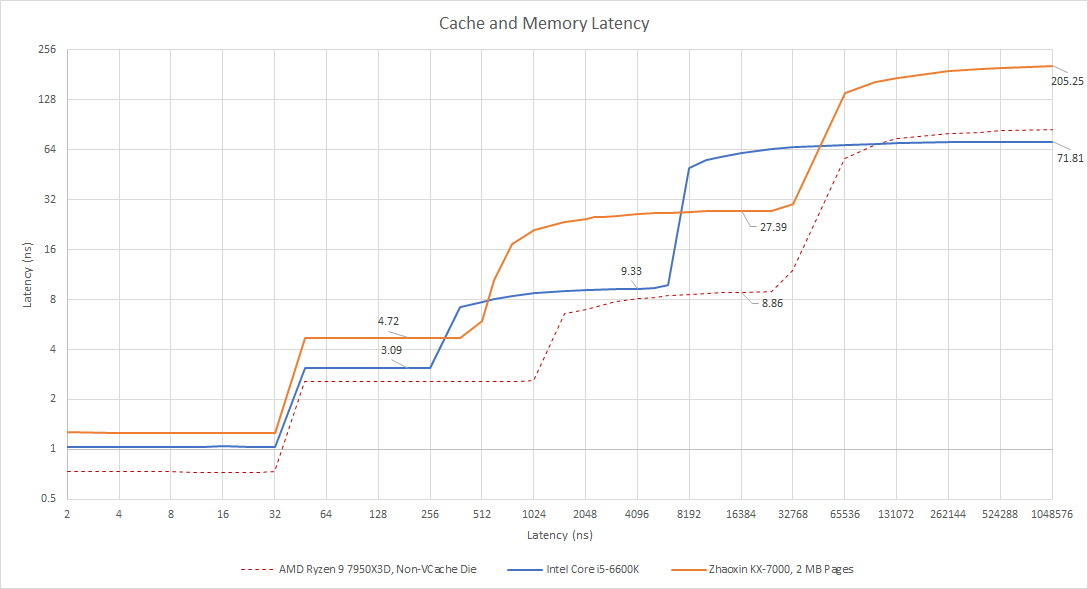
但与AMD近期设计不同,其L3延迟高达27纳秒(超80核心周期),带宽仅每周期略超8字节(读-改-写模式提升至11.5字节)。两者均不突出:Skylake纯读取模式L3带宽平均15字节/周期,AMD新设计可达其两倍。
KX-7000带宽扩展性尚可,但因低主频与单核带宽基数低,最终数值平平:纯读取模式215 GB/s,读-改-写超300 GB/s。对比Zen 2 CCD的L3带宽(超其两倍)仍有差距。
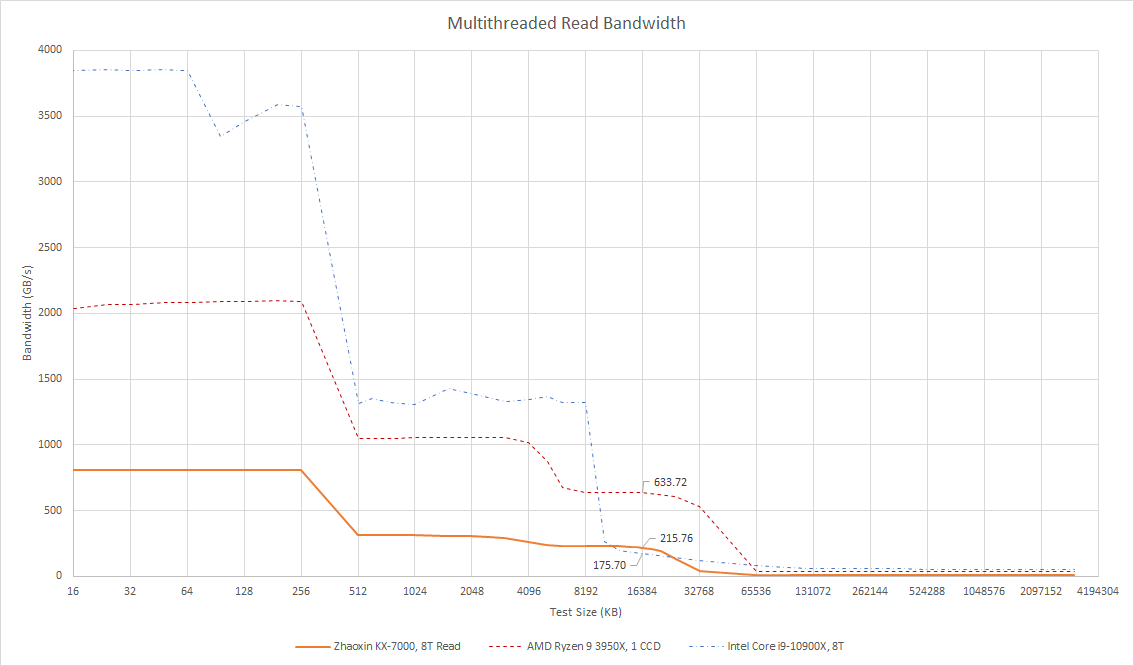
在相同线程数测试中,KX-7000的L3带宽确实高于Skylake-X,但后者以1 MB L2缓存隔离L3性能劣势。Skylake-X面向服务器市场,单线程性能优先级低;客户端领域,Bulldozer虽L3延迟相似,但通过2 MB L2减少访问频率。
DRAM访问
DRAM性能不佳:使用2 MB大页时延迟仍超200纳秒(4 KB页达240纳秒)。内存控制器仅支持1600 MT/s(尽管DIMM支持2666 MT/s JEDEC与4000 MT/s XMP),理论带宽限制为25.6 GB/s,但实测读取带宽不足12 GB/s。
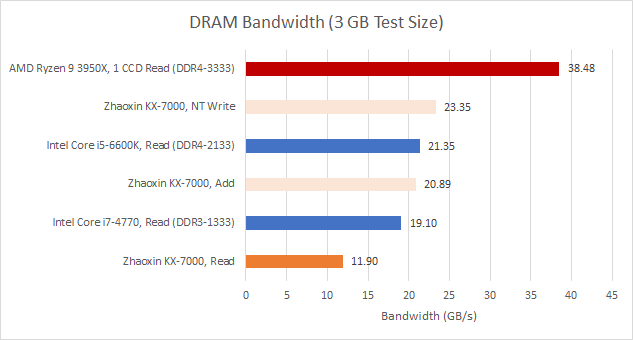
写入可提升带宽:读-改-写模式超20 GB/s,非临时写入达23.35 GB/s(接近理论值,说明跨芯片链路带宽充足)。读取带宽受限主因是延迟——写入数据可异步提交,但读取需等待数据返回,需维持足够多内存请求以掩盖延迟。
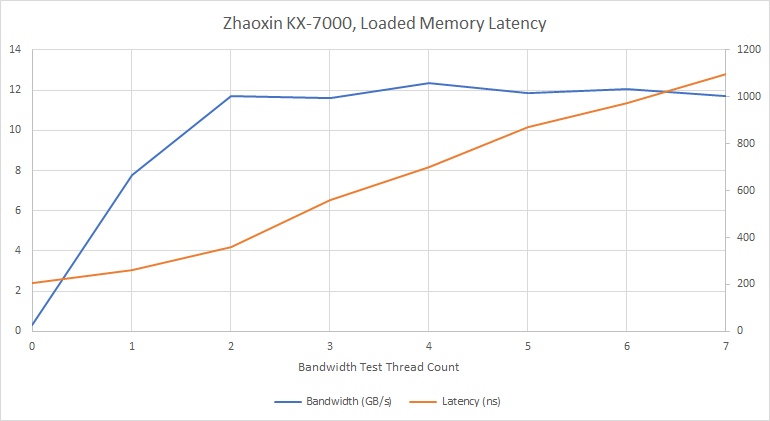
通常多核可增加内存请求数(每核有独立L1/L2未命中队列),但KX-7000读取带宽在双核以上测试时停止增长,暗示共享队列条目不足,无法隐藏延迟。
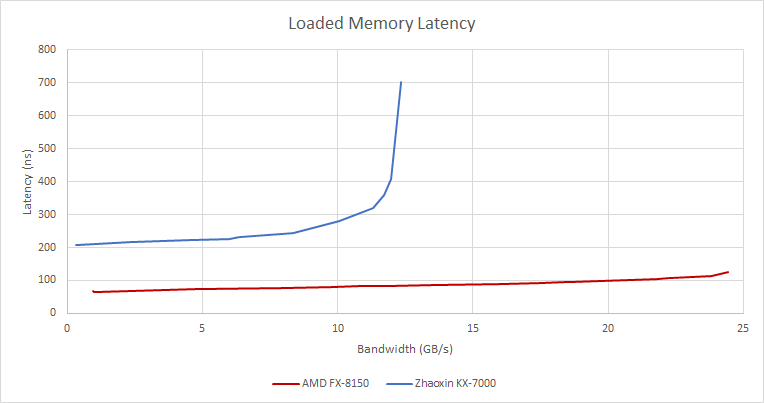
在不同线程数下选取最佳的延迟/带宽组合
更糟的是,内存子系统对多核请求公平性处理不佳:当其他核心高负载时,指针追踪线程延迟激增。极端情况(1延迟测试线程+7带宽线程)下延迟超1微秒,推测高带宽线程垄断了共享队列条目。
对比下,Bulldozer在高带宽负载下延迟控制更优:FX-8150北桥虽采用复杂双交叉开关设计,但延迟仅随带宽接近极限而上升,最坏情况仍优于KX-7000最佳情况。
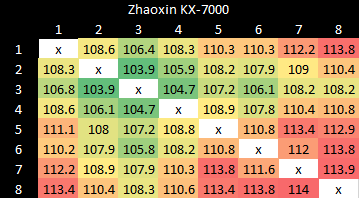
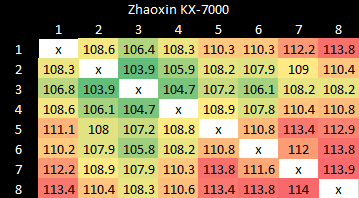
偶现需从其他核心缓存获取数据的情况(实践中罕见,但可揭示系统拓扑)。KX-7000核心间延迟测试显示较高但均匀的延迟,部分核心对延迟较低,可能与测试地址所属L3分片有关。
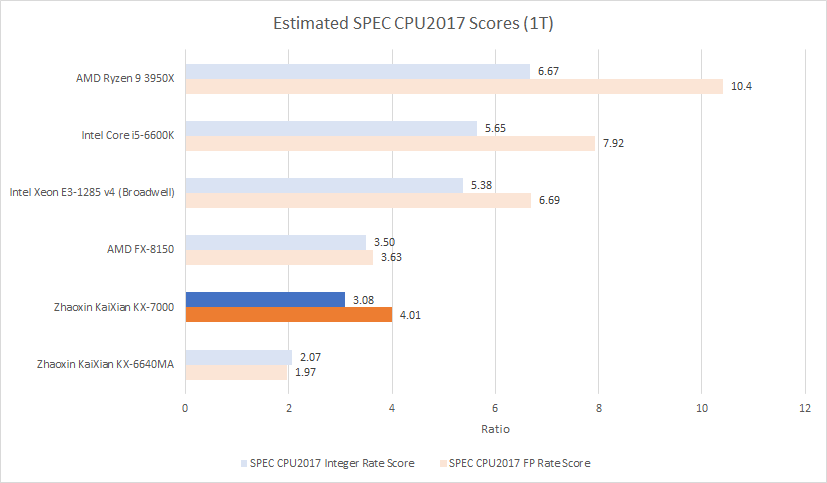
单线程性能:SPEC CPU2017
对比陆家嘴,世纪大道在SPEC CPU2017整数套件提升48.8%,浮点套件超2倍。兆芯近年努力收效显著,但与西方高性能x86-64芯片相比:整数套件略逊Bulldozer(FX-8150领先13.6%),浮点套件反超10.4%。
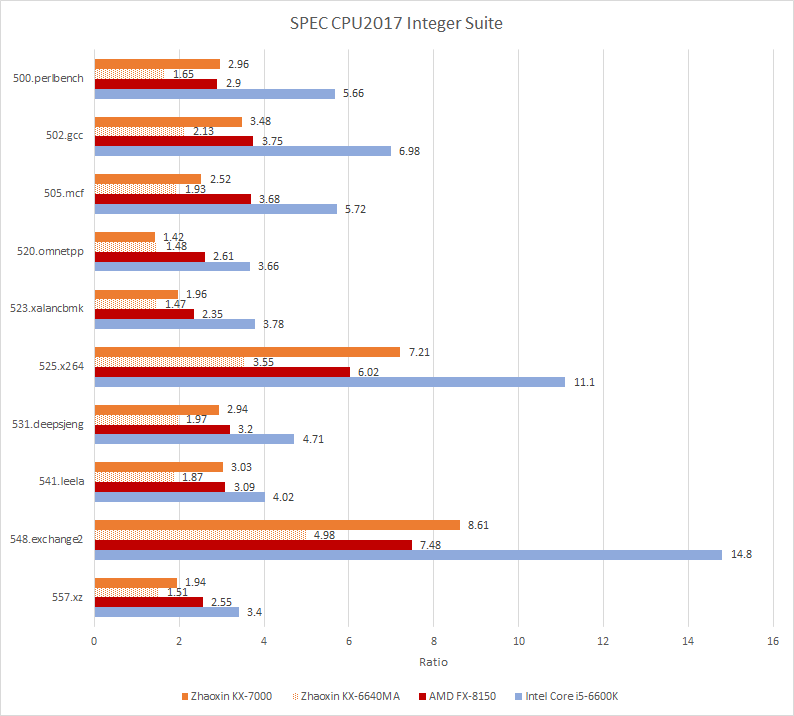
较Broadwell/Skylake等新核心,世纪大道性能差距悬殊,故Bulldozer是最佳参照。世纪大道在高IPC测试(如500.perlbench、548.exchange2、525.x264)表现更优,推测其额外执行资源占优;Bulldozer则在低IPC测试(如505.mcf、520.omnetpp)碾压KX-7000,这些测试含难预测分支与大内存足迹,Bulldozer的强内存子系统与更快分支预测器致胜。
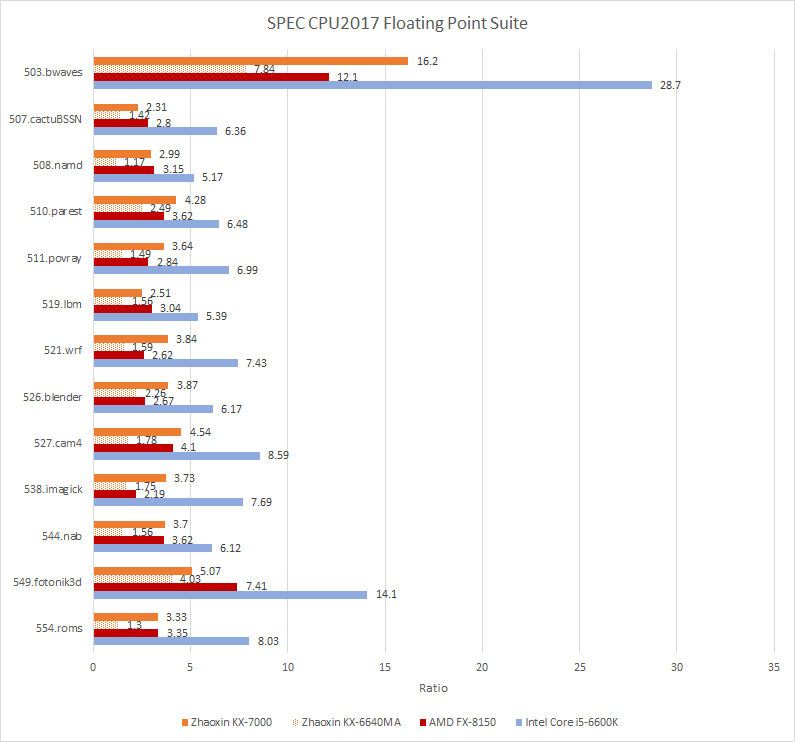
SPEC浮点套件多为高IPC负载,KX-7000占优,但FX-8150偶有胜场:如549.fotonik3d(低IPC、缓存未命中严重),Bulldozer领先46.2%;而538.imagick几乎无L2未命中。
综合SPEC结果,KX-7000单线程性能与Bulldozer大致相当。
多线程性能
8核是KX-7000对比FX-8150与i5-6600K的优势,但多线程结果参差:libx264视频编码(支持AVX2、多线程)中KX-7000甚至不敌Bulldozer;7-Zip压缩(纯标量整数指令)中Bulldozer与i5-6600K优势更大。
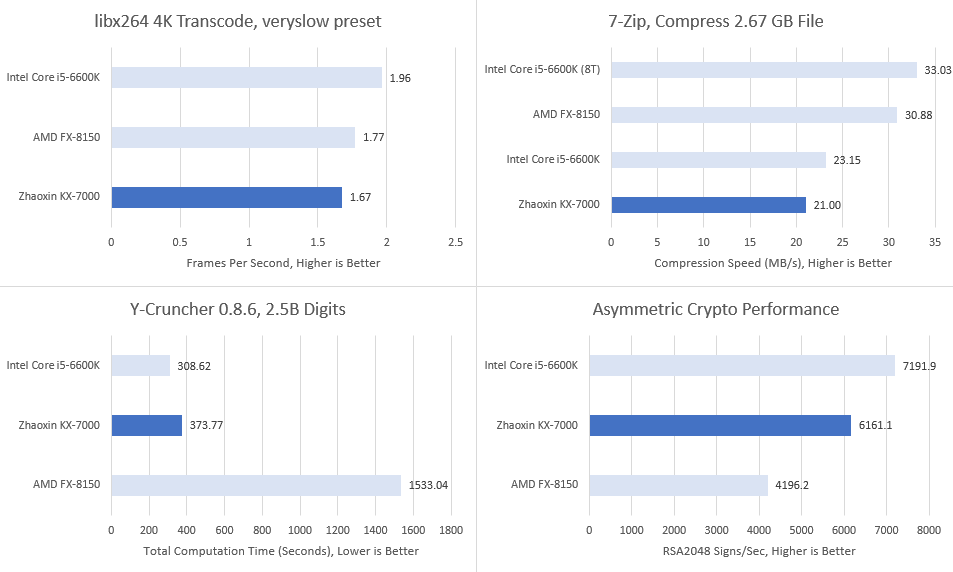
在Y-Cruncher测试中,KX-7000表现优于Bulldozer,可能是AVX2指令集为其带来了显著优势。然而,八核世纪大道(Century Avenue)处理器仍无法与四核Skylake匹敌。最后一项测试是OpenSSL RSA2048签名——这是一种纯整数运算,注重核心计算能力而非内存访问,对需要验证SSL/TLS连接身份的Web服务器尤为重要。兆芯(Zhaoxin)在此测试中再次击败Bulldozer,但仍落后于Skylake。
结语
兆芯继承了VIA的x86授权,但采取了不同的策略。VIA专注于低功耗、低成本应用,尽管Centaur CNS通过4发射设计尝试向更高性能目标迈进,但从未像AMD和英特尔那样进军广泛的通用计算市场。打造一款高频、高IPC(每时钟周期指令数)且能胜任从网页浏览到游戏再到视频编码的全能核心,是巨大的工程挑战。VIA理性地选择寻找利基市场,而非在缺乏对等工程资源的情况下与AMD和英特尔正面竞争。
然而,兆芯是中国为应对西方芯片断供风险而推进国产芯片计划的一部分。此举具有国家层面的战略意义,因此兆芯等企业即使无法盈利,也能依靠政府的大规模支持存活。兆芯芯片无需直接与AMD和英特尔竞争,但后两者的芯片已拉高了开发者对性能的预期。中国需要性能足以替代西方芯片且不会显著拖慢应用的本土产品。
世纪大道(Century Avenue)架构显然是为了实现这一目标而设计的尝试,摆脱了陆家嘴(LuJiaZui)架构的低功耗低性能路线。从宏观上看,世纪大道展现了显著进步——一款4发射、主频超过3 GHz且性能达到Bulldozer水平的核心已是一大步跨越。但在微观层面,兆芯似乎急于堆砌规模而未能充分优化整体协调性。世纪大道配备2个256位FMA单元,表明兆芯试图充分挖掘AVX2的潜力,但其缓存带宽较低,且在内部将256位指令拆分为两条微操作(micro-ops)。这种做法适合以兼容性而非高性能为导向的低成本AVX2实现方案。此外,相对于重排序缓冲区(ROB)容量,世纪大道的寄存器文件较小,限制了其利用理论乱序执行窗口的能力。
从系统层面观察,同样存在失衡问题。考虑到需缓解核心面对超过80周期的L3延迟,世纪大道的L2缓存容量过小。KX-7000的DRAM读取带宽对八核配置而言不足,其内存子系统在高带宽负载下也难以保证公平性。除了这些不平衡的特性,世纪大道的前端延迟较高且缺乏分支融合(branch fusion)能力,使其更像2005年而非2025年的核心设计。
最终决定用户体验的仍是实际性能。就这一点而言,KX-7000在多线程工作负载中有时甚至落后于Bulldozer——考虑到后者是2011年的设计(采用双硬件线程共享前端和浮点单元),这一结果令人失望。其单线程性能同样平庸,大致与Bulldozer持平,但即便在2011年,FX-8150的单线程性能已是其最大短板之一。当然,KX-7000的目标并非打动西方消费者,而是提供不依赖外国公司的可用体验。从这个角度看,Bulldozer级别的单线程性能已足够。尽管世纪大道缺乏现代AMD、Arm或英特尔核心的平衡性与精密性,但它仍是兆芯进军高性能领域的重要一步。
本文转自媒体报道或网络平台,系作者个人立场或观点。我方转载仅为分享,不代表我方赞成或认同。若来源标注错误或侵犯了您的合法权益,请及时联系客服,我们作为中立的平台服务者将及时更正、删除或依法处理。



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
联系电话:
010-61853490
新闻投稿:
server@icviews.cn
商务合作:
business@icviews.cn
问题反馈:
19800315212(微信同号)


半导纵横公众号

半导纵横小程序