GPU ,加速计算光刻
计算光刻技术是通过对掩膜、光源的正向或反演优化,降低因光波衍射影响光刻效果的程度。 计算光刻是采用计算机模拟、仿真光刻工艺的光化学反应和物理过程,从理论上指导光刻工艺参数的优化。计算光刻通常包括光学邻近效应 修正(OPC)、光源-掩膜协同优化技术 (SMO)、多重图形技术(MPT)、 反演光刻技术(ILT)等四大技术。
在制造现代半导体器件方面存在许多挑战,整个行业能够克服这些挑战本身就令人惊叹。从基础物理到制造工艺再到开发流程,都不乏棘手的问题需要解决。其中一些最大的挑战出现在用于深亚微米芯片的光刻技术中。最近的一篇文章概述了光刻技术的主要趋势,并总结了几个挑战和新兴解决方案。这篇文章聚焦于另一个关键挑战——光刻计算需求的大幅增加——并讨论了图形处理单元(GPU)如何帮助满足这一需求。
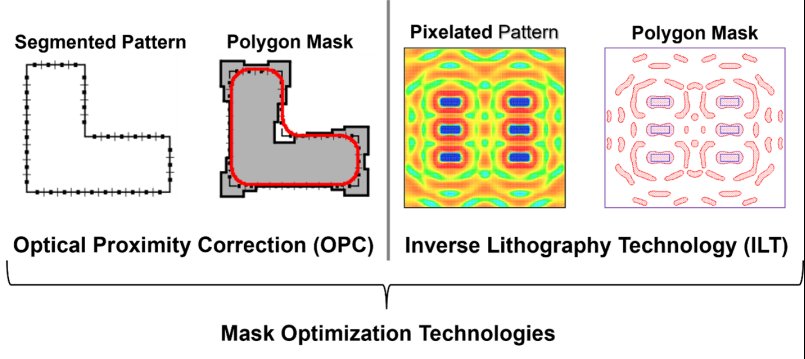
计算需求增加的原因在于通过衍射或工艺效应来补偿光刻过程中引入的图像误差,随着芯片设计的日益密集,这个过程需要更长的时间。如果不进行校正,刻在硅上的图案将无法精确再现设计者绘制的形状。角落可能会被圆化,线宽可能与预期不同。处理这一问题的传统方法是使用光学邻近校正(OPC),它调整边缘和多边形,以优化刻蚀特征,尽可能接近设计意图。
OPC需要大量的计算,但这通常不是一个主要的问题,因为基于分段的优化,可进行并行处理。更大的问题是,OPC提供了有限的自由度,在复杂的纠正形状和用于纠正他们的技术。近年来,逆光刻技术(ILT)作为一种更灵活的方法出现。模式被转换为像素,以便可以使用基于像素的优化技术。ILT可以处理更广泛的形状和图案,但它比OPC需要更多的计算能力。并行处理被广泛使用,但用户报告说,一个ILT掩码可以在多天内消耗超过10K个CPU核心。
计算光刻的需求不断增长。每个新的节点意味着每个掩模有更多的多边形,先进的工艺需要更多的掩模,而使用的形状变得越来越复杂。鉴于GPU提供了巨大的并行性并成功加速了芯片开发过程中的其他几个步骤,人们自然会想知道它们是否能加速ILT的计算。用户很清楚他们的愿望:使用合理的资源,计算时间不到一天。NVIDIA、台积电和Synopsys之间的近期合作提供了显著的证据,表明GPU可以帮助实现这一目标。这项工作涉及光刻代码从CPU到GPU的三个主要转换:
一些基于图像的操作自然适合通过直接重写来实现GPU并行化,包括FFT、卷积和图像处理。这些操作在下图中的绿色椭圆形中显示。
从多边形/边/点迭代到基于像素计算的算法,如新模型形式等都被转移到了 GPU 适配的领域。这些算法如下图中蓝色椭圆所示。将非 GPU 友好型数据结构(如基于多边形的布尔值和交互、用于创建水平集的多边形-2-像素算法以及轮廓绘制)迁移到 GPU 代码。这需要大量的研究、创新和软件工程。这些结构如下图中红色椭圆所示。
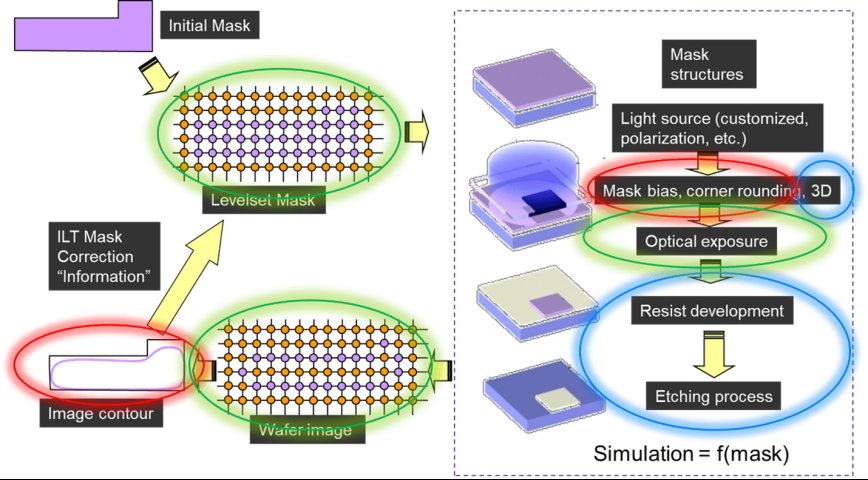
过去,基于 CPU 的算法和计算服务器硬件的改进为计算光刻技术提供了 2-4 倍的速度提升。2020 年使用 GPU 的初步实验表明,ILT 仿真功能的速度提高了 10 倍。如上图所示,随后的工作发现许多其他计算,如多边形和非基于图像的操作,都适合 GPU。其中一些操作既可用于 OPC,也可用于 ILT,这表明 GPU 可以加快这两种类型的掩模优化。
NVIDIA、台积电(TSMC)和Synopsys还共同开发了一个新的GPU光刻库,用于OPC和ILT。该库具有基于多边形和边缘的几何算法、多边形光栅化、FFT、卷积等特性。在某些类型的功能上,速度比CPU快高达40倍。从CPU到GPU的总体加速比,对于单个ILT“配方”在几个模板上累积的总运行时间超过15倍。使用较少的并行机器,多天的CPU运行时间可以缩短到不到一天。
计算光刻技术仍然是一个非常活跃的研究、开发和部署领域。更多流程和功能将继续为 GPU 启用,人工智能机器学习(ML)的应用也在不断增加,更有效的 CPU+GPU 协同优化也在不断推进。
本文转自媒体报道或网络平台,系作者个人立场或观点。我方转载仅为分享,不代表我方赞成或认同。若来源标注错误或侵犯了您的合法权益,请及时联系客服,我们作为中立的平台服务者将及时更正、删除或依法处理。



联系电话:
010-61853490
新闻投稿:
server@icviews.cn
商务合作:
business@icviews.cn
问题反馈:
19800315212(微信同号)


半导纵横公众号

半导纵横小程序