GPU趋势及其对AI基础设施的影响
以前有文章提到, Nvidia 的图形处理单元的性能强大,以至于网络和存储解决方案可能无法跟上,从而导致昂贵的 GPU 无法得到充分利用。然而,如今来看,很多事情都发生了变化。Nvidia 宣布了一种以Blackwell命名的新芯片架构。与此同时,英特尔和 AMD 在其竞争产品方面取得了进展。
采用 GPU 可能存在这样的问题:计算密集型工作负载的基础设施会出现失衡状况。
可以设想一下基于 CPU 的 AI 基础设施,在这种情况下一切运行顺畅,不存在瓶颈,各个组件的利用率能达到 80%,如此既不会过度采购设备,又留有足够带宽来应对突发情况。
那么当把计算升级到 GPU 时,这会给网络和存储解决方案带来怎样的影响呢?要是网络和存储无法跟上 GPU 计算升级的需求,那么对 GPU 的投资可就白白浪费了。
在这篇文章中,笔者想讨论一下引入 GPU 对您的基础设施意味着什么,以及您可以采取哪些措施来最大限度地利用您在 GPU 上的投资。在此之前,首先看看 GPU 和加速器的情况。
GPU 和加速器的现状
首先,来了解一下基本情况 - 加速器和 GPU 之间有什么区别?英特尔和 AMD 已经习惯使用术语“GPU”来指代在桌面系统上运行的芯片,以加速游戏玩家和视频编辑者的图形处理。他们使用术语“加速器”来指代专为数据中心设计的芯片,以支持机器学习、推理和其他数学密集型计算。另一方面,Nvidia 坚持在其所有产品中使用术语“GPU”。在这篇文章中,笔者将使用术语“GPU”来泛指这些芯片,因为它是最流行的术语。在提到英特尔和 AMD 的具体产品时,笔者将遵循他们的标准并使用术语“加速器”。
一起看看 Nvidia、Intel 和 AMD 在过去 5 年里都在做什么。下表按时间顺序排列,显示了自 2019 年 6 月以来进入市场的 GPU。它还显示了 Nvidia 的几款芯片,这些芯片原定于 2024 年底发布,但已推迟到 2025 年初。
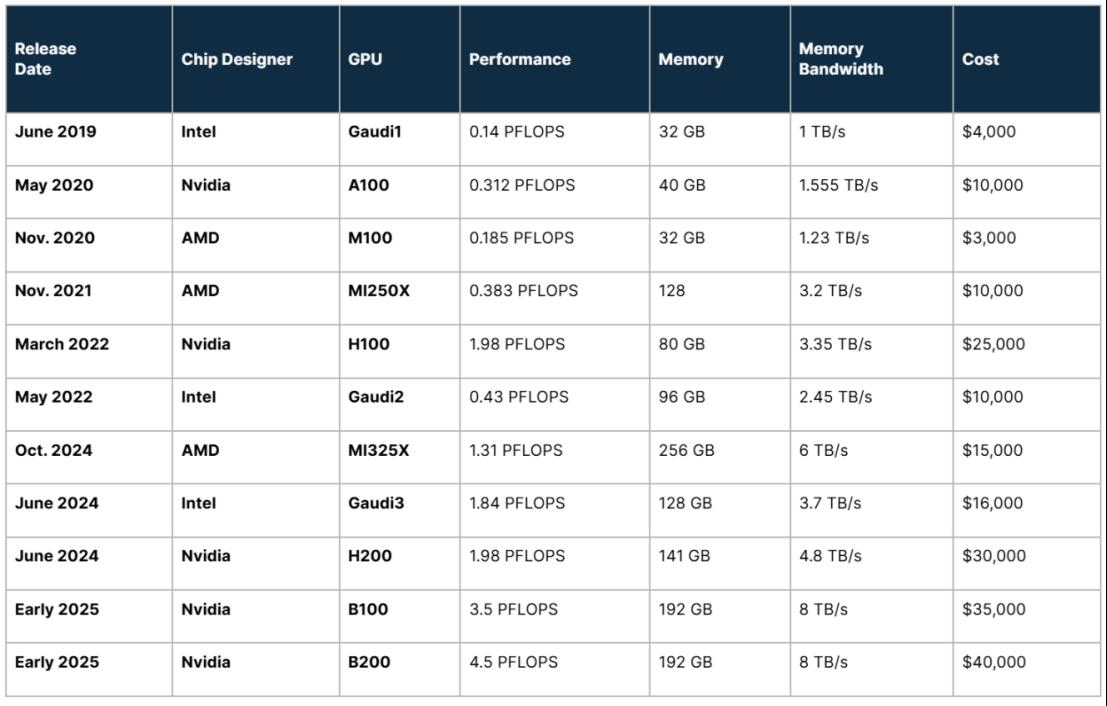 注意:上面显示的性能指标针对的是没有稀疏性的浮点 16 (FP16) 数据类型。
注意:上面显示的性能指标针对的是没有稀疏性的浮点 16 (FP16) 数据类型。
首先,存在一个性能趋势。了解这一趋势的最佳方式是按设计师绘制上述数字图表。底线是 GPU 的速度越来越快,而且这种模式没有显示出任何放缓的迹象。
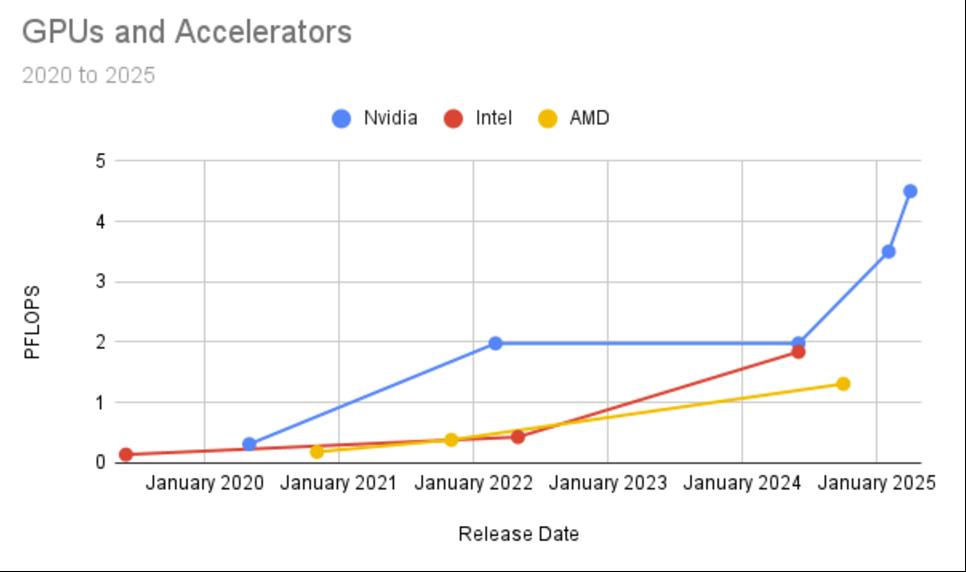
从上面的 GPU 表中可以得出的另一个观察结果涉及成本与性能的比较。例如,英特尔 Gaudi 3 加速器的成本是 Nvidia H200 GPU 价格的一半,但性能大致相同。因此,如果您不需要业内最快的芯片(即 Nvidia 的 B200),并且您的需求属于 2 PFLOP 类别,那么您最好购买 Gaudi 3。这是挑战者(英特尔)与具有性能优势的现任者竞争的经典策略。
基本思想是通过构建足够好的东西来在成本而不是性能上竞争,同时为您的客户节省成本。另一方面,如果您有多个团队训练和微调模型,并且您的生产环境在繁重的推理负载下有多个 LLM,那么您可能需要市场上最好和最快的芯片。竞争的最显著好处,就像我们现在在 GPU 上看到的那样,是消费者有了选择。
GPU 注意事项
如果您要升级 GPU,上表可以让您大致了解更快的 GPU 会给您的基础设施带来的额外压力。例如,如果您用 B200(均来自 Nvidia)替换一组老化的 A100,B200 的速度将提高 14 倍(4.5/.312),可能会给您的基础设施带来 14 倍的负载。B200 的内存也比 A100 多 152 GB,从而导致批处理大小更大或每个网络请求的数据更多。
首次采用 GPU 比较棘手,因为没有很好的方法来比较 GPU 和 CPU 的性能。因此,没有很好的方法来确定 GPU 会给您的网络和存储解决方案带来的额外负载。理论比较的问题在于 GPU 性能指标衡量的是每秒浮点运算次数。另一方面,CPU 性能以每秒时钟周期数来衡量。这是因为 CPU 处理多个指令集(每个指令集在不同的电路上运行),并且它们管理的逻辑操作被分解为多个任务,并且不同的指令集可能完成每个任务。时钟就像节拍器一样,可以精确协调逻辑操作的特定任务。
您可以猜测 CPU 处理的不同指令集的比例,以制定 CPU 的平均 FLOPS 指标,但这很容易出错。您还可以从训练集逆向推导,理论上确定运行一个训练集一个时期需要多少浮点运算。然而,这也是基于可能相差很大的猜测。最终,预测 GPU 对您的基础设施的影响的最简单、最准确的方法是试验实际工作负载。一定要试验多个训练工作负载和多个推理工作负载。这些实验可以在低成本的 POC 环境中进行,也可以与提供您希望购买的 GPU 的云供应商一起进行。
网络注意事项
由于 GPU 能够以极高的速度处理数据,因此它们的速度通常可以超过训练和推理期间数据加载的速度。网络速度慢或配置不足可能会导致 GPU 在等待数据到达时处于空闲状态。
此外,许多组织采用分布式训练技术,即使用集群中的多个 GPU 通过并行训练技术来训练单个模型。在分布式训练期间,网络基础设施不仅负责确保每个 GPU 都获得充足的训练数据,还负责在反向传播期间在 GPU 之间交换梯度。此操作的性能在很大程度上取决于网络的带宽和延迟。
网络设备价格昂贵,升级需要仔细规划,升级过程中可能会出现大量停机时间。出于所有这些原因,请考虑通过投资快速网络来为您的训练流程做好未来准备。400Gb 或 800Gb 网络可能听起来有点过分,但跳过一些升级可以节省资金,当引入更快的 GPU 时,您可以毫无问题地利用它们。
存储注意事项
如果您采用 GPU 并拥有高速网络,那么您 AI 基础架构的最终考虑因素就是您的存储解决方案。如果您使用 MinIO 的 AIStor 和 NVMe 驱动器,那么一切就绪了。最近的基准测试仅使用 32 个现成的 NVMe SSD 节点,就实现了 GET 325 GiB/s 和 PUT 165 GiB/s。如果您没有 NVMe 驱动器或想要从 AI 基础架构中榨取更多性能,MinIO 的 AIStor 有三个功能可以提供帮助。
S3 over RDMA:远程直接内存访问 (RDMA) 允许数据直接在两个系统的内存之间移动,绕过 CPU、操作系统和 TCP/IP 堆栈。这种直接内存访问减少了与 CPU 和操作系统数据处理相关的开销和延迟,使得 RDMA 对于低延迟、高吞吐量网络特别有价值。MinIO 最近将S3 over RDMA作为 AIStor 的一部分引入。
AIStor Cache: AIStor Cache允许企业使用多余的服务器 DRAM 进行缓存。它是一种缓存服务,使用分布式共享内存池来缓存经常访问的对象。一旦启用和配置,AIStor Cache 对应用程序层是透明的,并且可以无缝运行。考虑将 AIStor Cache 与 S3 over RDMA 结合使用。
Mirroring: 如果您拥有基于 AIStor 的大型全局数据湖,并且它未使用可用的最快磁盘驱动器,则可以安装一个带有 NVMe 驱动器的新的、较小的 AIStor 租户,并将其用于所有 AI 工作负载。AIStor 的Mirroring功能将使包含训练集的存储桶在租户之间保持同步。您的 AIStor 全局租户仍然是所有数据的黄金副本。新租户针对性能进行了配置,并包含 AI 所需数据的副本。
这种方法的优势在于不需要客户更换现有的 AIStor 实例。此解决方案还适用于 AIStor 缓存无法处理的大型数据集。随着 AI 工作负载数据的增长,高速租户也可以扩展。考虑使用 S3 over RDMA 的Mirroring解决方案,以获得更快的性能。
本文转自媒体报道或网络平台,系作者个人立场或观点。我方转载仅为分享,不代表我方赞成或认同。若来源标注错误或侵犯了您的合法权益,请及时联系客服,我们作为中立的平台服务者将及时更正、删除或依法处理。




联系电话:
010-61853490
新闻投稿:
server@icviews.cn
商务合作:
business@icviews.cn
问题反馈:
19800315212(微信同号)


半导纵横公众号

半导纵横小程序