Telum II:拥有独特缓存策略的主机处理器
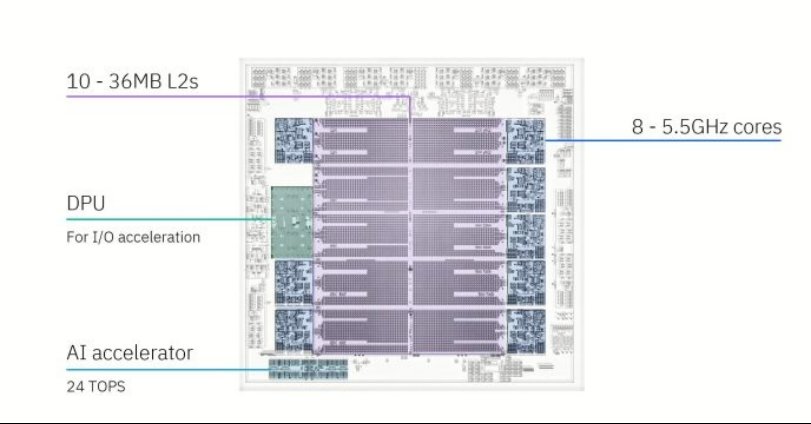
主机在当今仍然发挥着至关重要的作用,为金融交易提供极高的正常运行时间和低延迟。Telum II是IBM最新的主机处理器,其设计与其他服务器CPU截然不同。它仅拥有八个核心,但运行速度高达 5.5 GHz,并为这些核心配备了360 MB的片上缓存。IBM还为其配备了DPU以加速IO操作,以及板载AI加速器。Telum II采用了三星领先的5纳米工艺节点。
IBM的演示已经被其他媒体报道过,因此本文聚焦在Telum II一些有趣的特点上。DRAM的延迟和带宽限制往往意味着良好的缓存对性能至关重要,而IBM经常采用有趣的缓存解决方案。Telum II也不例外,它继承了IBM先前芯片中的虚拟L3和虚拟L4策略。
虚拟L3
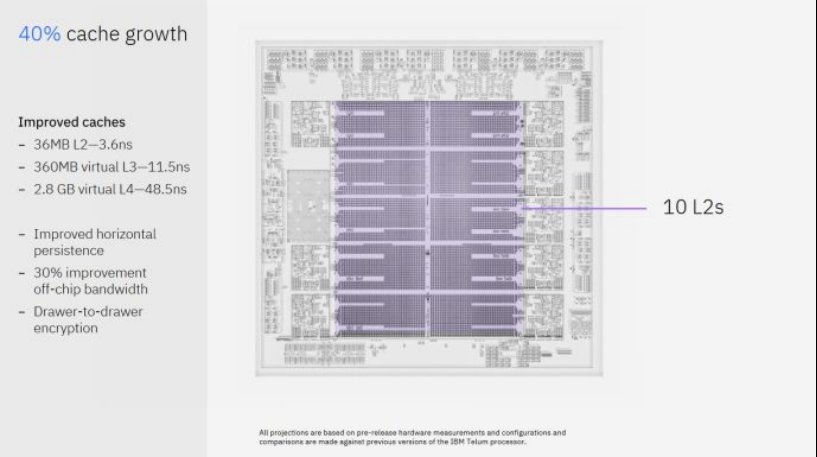
Telum II拥有十个36 MB的L2片上缓存,这绝对是巨大的。相比之下,AMD的Zen 3桌面和服务器CPU的L3缓存通常为32 MB。Telum II的八个L2缓存与核心相连,另一个与DPU相连,而最后一个则不与任何组件相连。另一个对比是高通Snapdragon X Elite中的Oryon核内核,其L2缓存为12 MB,延迟为5.29纳秒。高通考虑了紧密耦合的高容量缓存。Telum II的L2延迟为3.6纳秒,且容量更大。
 高通的Oryon具有5.28纳秒的L2延迟
高通的Oryon具有5.28纳秒的L2延迟
这些巨大的L2缓存对于减少内存访问延迟非常有效,但也使Telum II 陷入了尴尬的境地。现代 CPU 通常具有跨多个内核共享的大型缓存,共享缓存可以在低线程负载下为单线程提供更多容量,并在多线程负载下减少共享数据的重复。但Telum II的八个核心已经占用了288 MB的SRAM容量,以及相关的面积和功耗成本。一个更大的L3对于专用主机芯片来说也会很昂贵。
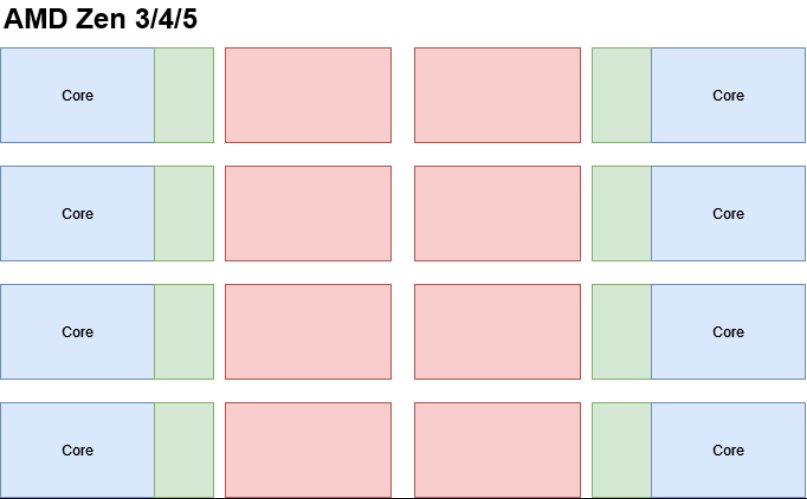 绿色= L2, 红色= L3
绿色= L2, 红色= L3
IBM的解决方案是减少缓存中的数据重复,并利用芯片的巨大L2容量来创建虚拟L3缓存。根据IBM的专利,每个L2都有一个“饱和度指标”,该指标基于其核心将数据带入其中的频率(以满足未命中情况)。当 L2 踢出一条缓存行以便为传入数据腾出空间时,该被驱逐的缓存行将由另一个饱和度指标较低的 L2 处理。这样,已经突破自身 L2 容量极限的核心可以将该容量留给自己。没有连接核心的L2切片始终具有最低的饱和度指标,使其成为被踢出L2的缓存行的首选目的地。如果另一个L2已经有该被踢出的缓存行的副本,Telum II会让该L2拥有该缓存行,而不是将其放入虚拟L3,从而进一步减少数据重复。
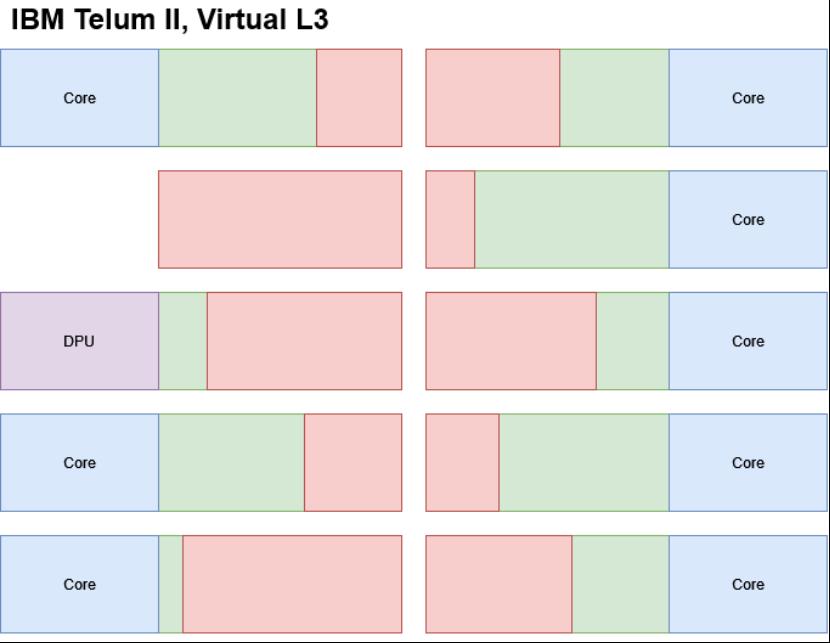 绿色= L2, 红色= 虚拟L3(从L2中逐出的行在其他L2中持久化)
绿色= L2, 红色= 虚拟L3(从L2中逐出的行在其他L2中持久化)
跟踪饱和度指标并不是IBM防止虚拟L3独占L2容量的唯一方法。IBM的专利还提到了将虚拟L3行插入到中间LRU位置。替换策略是缓存选择踢出一条线以引入新线的方式。LRU代表最近最少使用,是一种替换策略,其中最近最少使用的线被踢出。通常,新插入的行会被放置在MRU(最近最常使用)位置,使其成为最后被替换的。但虚拟L3行可以被放置在中间位置,从而为由核心带来的L2行提供优先权。
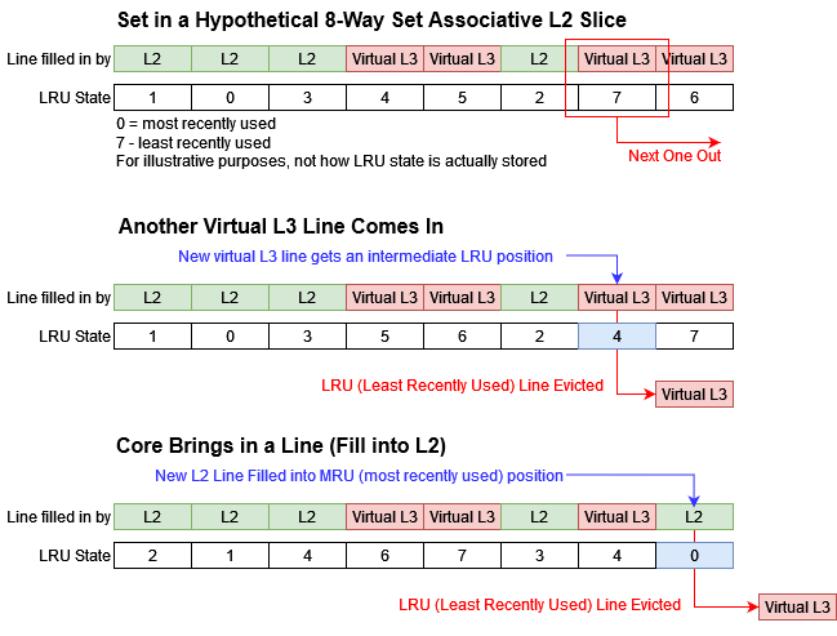
使用中间位置也让IBM能够控制虚拟L3可以使用多少L2容量。例如,将虚拟L3填充到LRU和MRU位置之间的一半位置将限制虚拟L3使用一半的L2容量。很容易看出IBM如何能够优雅地适应不断变化的应用程序需求。如果一个核心闲置,其L2可以开始在LRU位置插入虚拟L3填充,让虚拟L3在该切片中使用所有可用容量。
除了保证L2容量不会受到挤压之外,虚拟L3还面临着另一项挑战。虚拟L3中的一条线可能位于Telum II的十个L2切片中的任何一个。在AMD、Arm和Intel的L3缓存中,地址总是指向同一个切片。核心可以查看地址的子集位,并确切知道要将请求发送到哪个L3切片。但IBM并非如此。显然,IBM通过潜在地检查所有L2切片来处理虚拟L3访问。我询问他们是否担心来自更多标签比较的开销,但他们表示这不是问题,因为L2的未命中率很低。重要的是要记住,工程师们会努力保持CPU设计的平衡,而不是倾注资源以确保它在每个细节上都做到最好。Telum II核心最多可以使用36MB的L2容量。在其他条件相同的情况下,它应该比Zen 5核心在其32MB L3中更不常错过L2。Zen 5的L3访问可能功耗更低,但AMD需要这样做,因为Zen 5核心的L2容量比Telum II核心的L2容量小一个数量级。
为什么不止步于L3?
IBM的主机芯片并非孤立部署。最多可将 32 个 Telum II 处理器连接起来,形成一个大型的共享内存系统。同样,IBM也在整个系统中考虑了大量的缓存容量,而不是仅仅针对单个Telum II芯片。而且,他们再次应用了相同的虚拟缓存概念。Telum II通过将有闲置缓存容量的其他Telum II芯片上的L3被驱逐数据发送过去,从而创建了一个2.8 GB的虚拟L4。
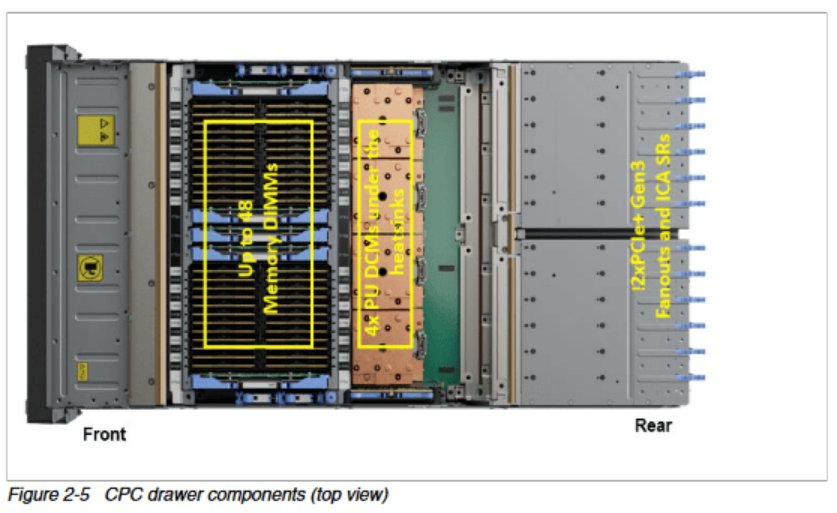
现在还不确定IBM是如何实现虚拟L4的,但IBM过去的主机设计可能会提供一些线索。IBM将主机CPU组织成CPC(中央处理器复合体)抽屉,这在某种程度上类似于机架式服务器。CPC不能像服务器那样独立工作,因为它不包括非易失性存储或电源供应单元,但它确实将一组CPU和DRAM放置在非常接近的物理位置。之前的 IBM 设计有一个抽屉宽的 L4,Telum II可能也是如此。2.8 GB的L4与八个Telum II如果一个抽屉有八个 Telum II 芯片,就像Z16抽屉中有八个Telum芯片一样,那么IBM可能是在抽屉间持久化L3的驱逐数据。
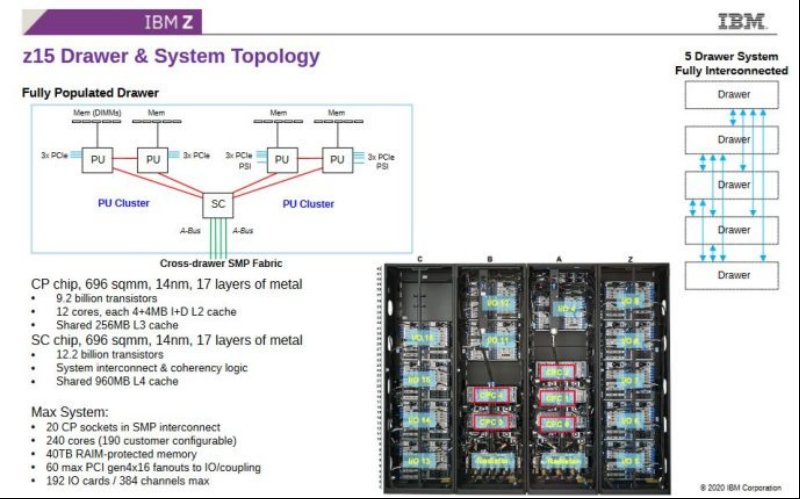 回溯到上一代,z15拥有一个系统控制器(SC)芯片,该芯片拥有一个巨大的可跨抽屉共享的960MB L4缓存
回溯到上一代,z15拥有一个系统控制器(SC)芯片,该芯片拥有一个巨大的可跨抽屉共享的960MB L4缓存
IBM声称虚拟L4访问的延迟为48.5纳秒。跨抽屉边界实现这一点将是一个巨大的挑战。尽管Telum II的野心很大,但我认为那将是过犹不及。在延迟方面,IBM很可能是在打赌L3未命中的情况足够罕见,以至于48.5纳秒的L4延迟不是什么大问题IBM 在跨越芯片边界时将延迟降至如此低方面也功不可没。相比之下,Nvidia的Grace超级芯片在单一芯片上就拥有超过42纳秒的L3延迟。
回顾Telum
在谈论Telum II的缓存策略时,不能忽视原始的Telum/Z16。那是IBM将虚拟L3和L4缓存引入其主机产品线的地方。Telum在去年的Hot Chips 2023上亮相。自那以后,IBM发布了更多关于Telum的虚拟L3/L4设置如何工作的信息。这是一个相当简单的方案,其中每个32 MB的L2片被分为两个16 MB的段。如果一个核心不需要其L2的全部容量,那么其中一个段可以成为虚拟L3/L4的一部分。如果核心空闲,那么全部的32 MB都可以用于虚拟L3/L4。

IBM的技术概述进一步阐明了虚拟L4是跨抽屉实现的。一个Z16抽屉有八个Telum芯片,每个芯片有256 MB的L2容量。在抽屉上运行的单线程工作负载会得到其自己的32 MB L2。所有的其他片上L2缓存都成为该线程的224 MB L3,而抽屉内的其他L2缓存组合起来形成一个1.75 GB的虚拟L4。
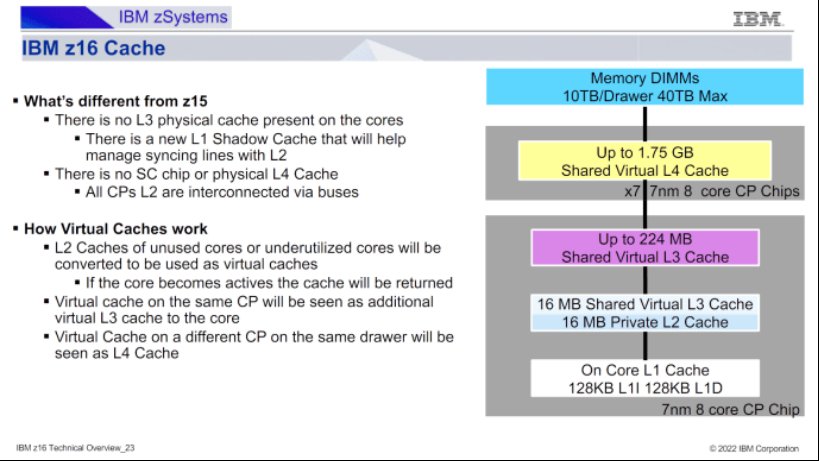
Telum II 进一步采用了这一策略,在L2、虚拟L3和虚拟L4上都有更高的缓存容量。当我在 Cheese 接受采访后询问 Telum II 如何处理其虚拟 L3 时,他们提到了一致性类。我不知道一致性类是什么。

最后的话
CPU设计者必须在单线程和多线程性能之间取得平衡。服务器CPU往往侧重于后者,而客户端设计则相反。Telum II和之前的IBM大型机芯片处理的是诸如金融交易之类的服务器任务,但奇怪的是,它们似乎更侧重于单线程性能。IBM实际上已经将每个芯片的核心数从Z15的12个减少到了Telum和Telum II的8个。IBM的缓存策略也明显侧重于单线程性能。在Telum II上运行的单个线程可以享受类似于客户端的L2和L3访问延迟,但每个级别的容量都大了一个数量级。
本文转自媒体报道或网络平台,系作者个人立场或观点。我方转载仅为分享,不代表我方赞成或认同。若来源标注错误或侵犯了您的合法权益,请及时联系客服,我们作为中立的平台服务者将及时更正、删除或依法处理。




联系电话:
010-61853490
新闻投稿:
server@icviews.cn
商务合作:
business@icviews.cn
问题反馈:
19800315212(微信同号)


半导纵横公众号

半导纵横小程序