如何设计最先进的Chiplet和SoC架构?
当今,半导体行业面临的挑战,其中第一个挑战是硅片的复杂性不断增加(单芯片 SoC 已经足够复杂,现在我们正在转向基于芯片的多芯片系统)、软件(跨异构系统扩展)和一致性(保持芯片和集群之间的缓存一致性)。此外,性能“保证”(数据带宽、延迟、服务质量)在处理器、内存、缓存和结构中变得至关重要。然后是成本越来越高(硅片、功率、封装),市场窗口越来越小(需要更快的上市时间以及更快的扩展和定制 SKU 路径)。
作为其中的一部分,Baya Systems的首席商务官 Nandan Nayampally 展示了下面显示的图表,黑点和黄点分别代表 CPU 和 GPU 中的晶体管数量,有趣的是红点,它们反映了高级多核 SoC 中的硅 IP 块数量。请记住,Y 轴是对数的,这表明 20 世纪 90 年代末的平均 IP 数量不到 10 个,但现在已达到数百个,并且仍在增加。同样有趣的是无数 AMBA 协议的时间线并列,包括各种 AXI 和 CHI。
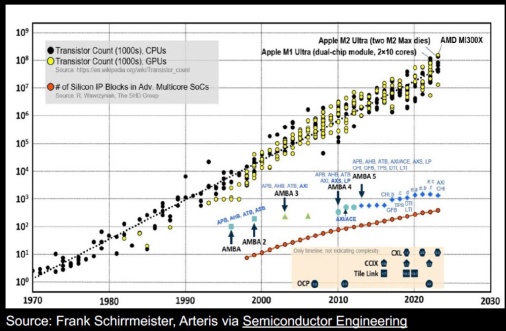 增长挑战。来源:Baya Systems
增长挑战。来源:Baya Systems
这里有很多信息需要消化。例如,请考虑下面显示的表示的上半部分。虽然简单,但这种描述反映了深度学习加速器(红色)的性能如何飞速提升,GPU(绿色)和 CPU(蓝色)正在努力跟上,而内存性能虽然在提高,但仍落后,性能差距逐年扩大。
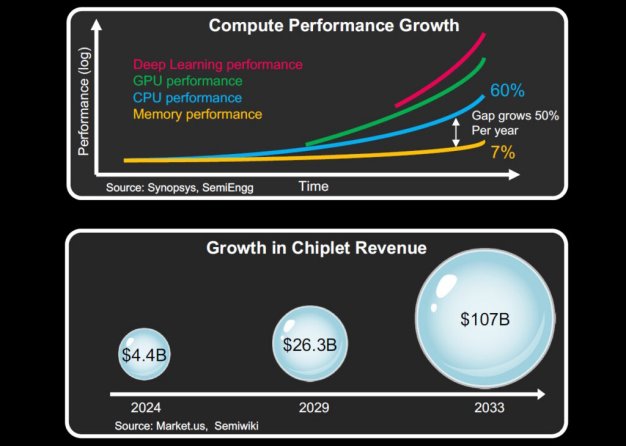 智能计算的主要趋势。来源:Baya Systems
智能计算的主要趋势。来源:Baya Systems
简而言之,计算速度超过了数据和带宽:CPU 性能超过了内存(并且差距正在扩大),GPU 性能超过了 CPU 性能,专用的深度学习加速器也超过了 GPU。
与此同时,我们正处于向基于芯片的多芯片系统过渡的早期阶段。这种向芯片的过渡可以实现一流的多供应商解决方案,从长远来看,它将在规模、重用、产量和成本方面带来优势,但在短期内,创建大型、复杂的基于芯片的设计仍是一个挑战。
此外,智能计算的增长需要一流的计算、高性能且高效的数据移动以及创新的复杂内存层次架构的紧密结合。
那么,Baya Systems 打算如何解决所有这些问题,它又将带来什么呢?很高兴您问到这个问题。这个故事有两个主要元素:Weave IP 和 WeaverPro。
让我们从 Weave IP 开始,它拥有协议中立的可扩展自定义结构、可配置的非一致和一致结构、多级缓存一致结构以及可配置的缓存控制器。
 Weave IP:支持的结构协议和功能。来源:Baya systems
Weave IP:支持的结构协议和功能。来源:Baya systems
接下来,我们有WeaverPro,一个包含两个主要元素的基础软件平台:Cache Studio 和 Fabric Studio。
Cache Studio 可帮助开发人员快速设计高效的内存和缓存架构,彻底分析自由形式的缓存和内存层次结构,使用快速准确的缓存模型模拟工作负载,并优化全局系统架构和芯片分区。
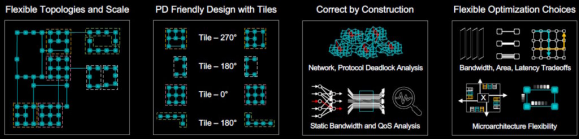
Fabric Studio 帮助开发人员设计数据驱动、最佳的片上架构微架构,静态分析和优化设计参数和性能,使用周期精确的模拟器动态分析和优化,然后生成正确的物理感知设计。
人们长期以来一直在研究片上网络 (NoC) 技术。人们可能认为这将为现有的 NoC 技术带来优势。然而,从另一个角度来看,随着时间的推移,最初没有考虑到的东西会被添加进来(或附加上去)。例如,早期的 NoC 实现并没有考虑到基于芯片的多芯片系统。在某个阶段,值得从头开始,利用多年来学到的知识来提出一种新的、精简的实现。这就是 Baya Systems 的员工所做的,他们打造了一个多功能网络,可以高效传输任何协议,并满足任何单芯片 SoC 和基于芯片的多芯片系统的性能和物理设计要求。
 用途最广泛的网络。来源:Baya Systems
用途最广泛的网络。来源:Baya Systems
该 NoC 提供高性能(4nm 工艺下最高可达 3GHz)、可配置通道宽度(8b 至 2048b),并且灵活且可扩展。可以有不同的 NoC 拓扑,并且可以将多个 NoC 连接在一起。该系统支持灵活的优化选择(带宽、面积、延迟权衡),并且一切都对物理设计友好且构造正确。
为了满足人工智能和数据中心类型操作的需求,Weave IP 和 WeaverPro 支持大规模扩展,包括芯片级的 1024 节点网络和多芯片系统级的 64 芯片和 128 个芯片间 (D2D) 链路。
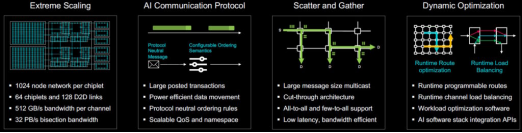 适用于 AI 系统和数据中心应用的可扩展结构。来源:Baya Systems
适用于 AI 系统和数据中心应用的可扩展结构。来源:Baya Systems
Weave IP 与 WeaverPro 的结合带来了统一的设计流程。智能数据驱动的统一结构的优势包括优化性能和面积的通用传输机制、拓扑和规模的广泛灵活性、通过构造进行纠正(无死锁、QoS、RAS)以及基于工作负载的局部和全局优化。
除了静态设计时配置和优化之外,WeaverPro 的 API 还支持动态运行时分析、定制和优化。
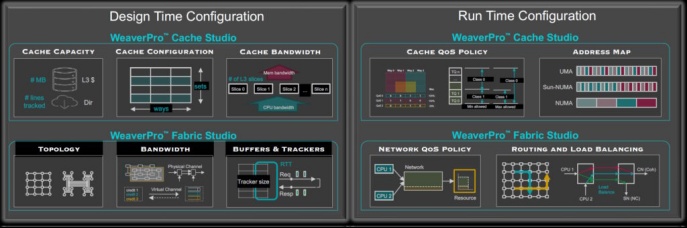 高级设计和运行时优化。来源:Baya Systems
高级设计和运行时优化。来源:Baya Systems
下面的结果反映了设计时和运行时优化对真实设计的影响。
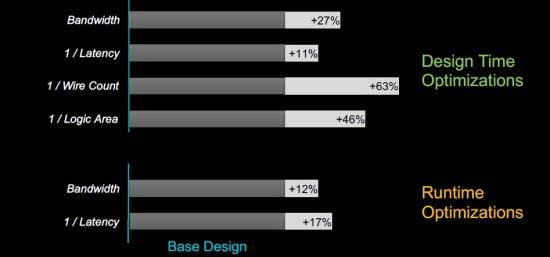 使用标准网格实现的结果与基线相比。来源:Baya Systems
使用标准网格实现的结果与基线相比。来源:Baya Systems
设计基线(条形的深灰色部分)是使用标准网格实现的。所有优化都是由工具驱动的,反映在条形的浅灰色部分中(超级用户可以使用这些结果作为起点来实现进一步的优化)。这里有很多需要我们思考的问题,但我们可以总结 Baya 的解决方案如下:
· 软件驱动的架构探索有助于优化设计,以实现基于内置模拟器的性能保证。
· 引擎根据流量规范生成代表性工作负载。
· 一流的灵活网络可以在 4 纳米工艺技术下实现 3GHz。
· 算法优化支持重用,并在不影响性能的情况下最大限度地减少硅和功率占用空间。
· 业界首个为单/多芯片系统提供多级缓存一致性的 IP,从根本上降低了这些大规模系统的一致性成本。
· 可定制的协议和多播功能,用于支持 PB 级吞吐量的高级 AI 和 CPU 加速。
· 通过构造正确设计生成可从根本上降低失败风险。
· Weave IP 支持 CHI、ACE5-Lite、AXI5 等标准协议,并且可扩展到包括 CXL 在内的其他协议。
· 具有模块化和平铺支持的物理感知流,易于实施。
本文转自媒体报道或网络平台,系作者个人立场或观点。我方转载仅为分享,不代表我方赞成或认同。若来源标注错误或侵犯了您的合法权益,请及时联系客服,我们作为中立的平台服务者将及时更正、删除或依法处理。




联系电话:
010-61853490
新闻投稿:
server@icviews.cn
商务合作:
business@icviews.cn
问题反馈:
19800315212(微信同号)


半导纵横公众号

半导纵横小程序