Lumai光学计算机落地,技术性能超GPU 50倍,功耗降低90%
英国初创企业Lumai正将其基于透镜的光学计算机推向产品化,用于人工智能推理中的矩阵乘法加速。Lumai产品负责人Phil Burr表示,这是光学计算系统首次成功运行数十亿参数模型,也为验证这项技术的商业可行性迈出了重要一步。
Burr称,该公司已经从技术层面解决了现有光子计算方案失败的根本原因。“我们通过三维空间计算实现了可扩展性,因此能够实现大规模并行计算。我们可以采用行业标准元器件和材料,尽管会做定制化改造,但无需为全新材料走完一整套设计周期。”
Lumai的光学加速器并未采用集成光子学方案。输入向量被编码到1024个激光光源中,再通过透镜进行复制。编码后的数据流随后穿过一块电子显示屏,屏幕像素的明暗变化对应权重编码。光线穿过显示屏即可完成乘法运算,最后由一枚透镜将运算结果叠加求和。
这套系统的计算过程几乎不消耗能量,但需要能耗用于光电、电光信号转换,以及为激光器和探测器供电。Lumai表示,其技术性能可达当前GPU的50倍,同时功耗降低90%。Burr表示:“目前数据中心的发展瓶颈在于功耗。我们的方案通过大幅提升能效,突破这一瓶颈,可以在同等功耗预算下提供更强算力、处理更多令牌。”

LumaiIris服务器内部构造(来源:Lumai)
Lumai的能效优势,部分源于可单次处理2048×2048大型矩阵运算。Burr称:“光学方案中,主要功耗来自光电与电光的来回转换。但优势在于,这部分功耗随矩阵乘法中向量规模呈线性增长,而算力性能却随规模呈平方级提升。因此矩阵尺寸越大,整体能效就越高。”
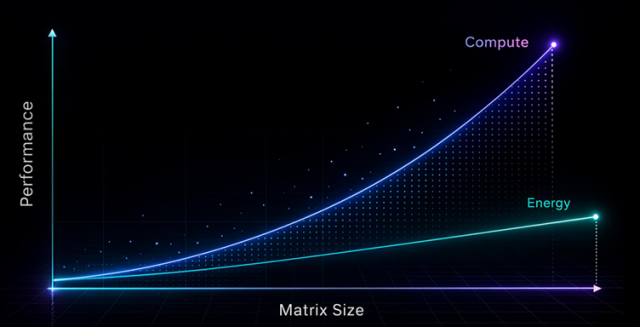
自由空间光学计算在大规模矩阵运算中具备更高能效(来源:Lumai)
Lumai的设备搭载一枚数字处理器CPU,负责处理部分非线性运算,并通过硬件适配调度层将矩阵乘法任务卸载至光学计算系统。该调度层会划分工作负载,决定哪些任务由CPU运行、哪些转为光学运算。Burr提到,对于部分对精度高度敏感的算法环节,会保留在CPU上运行,避免转为模拟域带来精度损耗。他补充道,Llama大模型有90%的工作负载可在光学域完成。
CPU与光学引擎之间,由FPGA负责光电信号相互转换。目前公司正在研发专用ASIC芯片,用以替代现有FPGA及相关器件,将搭载于Lumai下一代产品。
搭载单台第一代光学引擎的Lumai Iris Nova推理服务器,将面向超大规模云厂商客户开放,供其技术评估,目前已可演示运行Llama大模型。

Lumai Iris Nova服务器(来源:Lumai)
Burr表示:“我们重点适配Llama大模型,这也是客户的主流需求。Llama为开源模型,也是业内客户评估性能的通用基准。同时我们也在持续拓展可运行的模型与负载类型。”
Burr预计,Iris Nova服务器将于2026年底部署至客户测试集群。下一代产品Iris Aura将在单机柜内集成多颗光学引擎。后续Iris Tetra将支持集群级大规模部署。据公司介绍,定于2029年推出的Iris Tetra,INT8算力能效可达100TOPS/W,可在10千瓦功耗预算内实现1艾沙运算能力。
Burr称:“我们迭代节奏较快,一部分原因是希望尽快落地商用系统,让客户能够上手评测、部署自有软件,搭建规模化计算集群。”从目前客户反馈来看,新技术采用渐进式落地方式,能够有效规避后续系统集成出现的各类问题。
Burr提到,Lumai的评估服务器Iris Nova已可完整支撑Llama大模型推理;整体而言,这项技术非常适合在分离式数据中心中高效处理预填充任务,因为预填充本身属于算力密集型负载。在多用户并发、智能体AI、企业级大模型等长上下文输入场景中,能效优势尤为突出。
Burr表示:“目前我们同时支持预填充和解码两大环节,Iris Nova也可作为全流程解决方案部署。但随着数据中心架构向分离式演进,加之我们本身极其擅长算力密集型任务,Iris Nova的核心定位显然是预填充加速。具体也取决于大模型类型,部分模型算力消耗极高,原则上我们也可以推出大内存定制版本,专门面向解码场景。但光学计算的核心优势,还是集中在算力计算环节。”
本文转自媒体报道或网络平台,系作者个人立场或观点。我方转载仅为分享,不代表我方赞成或认同。若来源标注错误或侵犯了您的合法权益,请及时联系客服,我们作为中立的平台服务者将及时更正、删除或依法处理。



联系电话:
010-61853490
新闻投稿:
server@icviews.cn
商务合作:
business@icviews.cn
问题反馈:
19800315212(微信同号)


半导纵横公众号

半导纵横小程序