图解CPU、GPU、TPU、NPU、LPU
如今,人工智能主要由五种硬件架构驱动,分别是CPU、GPU、TPU、NPU和LPU(语言处理单元)。每种架构在设计理念上各有侧重,在灵活性、并行性和内存访问效率之间做出了截然不同的权衡,适配不同的人工智能应用场景,共同支撑起当前人工智能技术的快速迭代与落地。
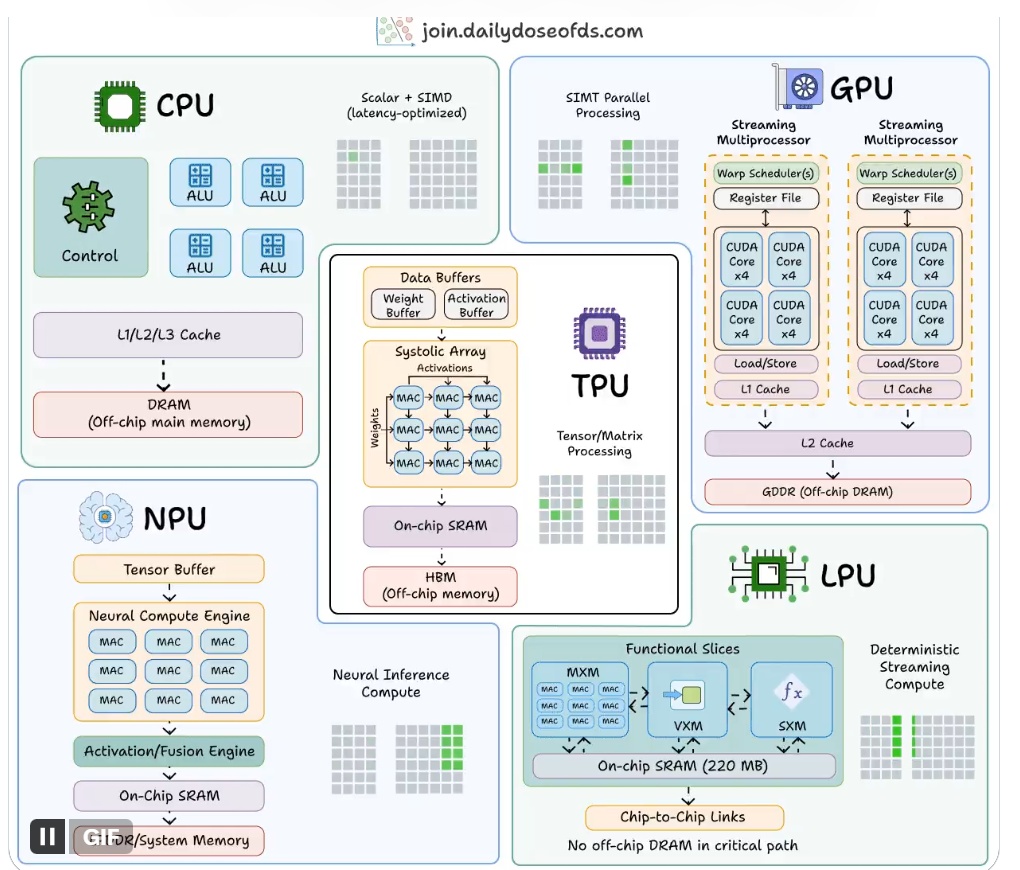
CPU(中央处理器) 是人工智能计算的基础支撑,专为通用计算场景设计,通常包含4-64个高性能核心(消费级多为4-16核,服务器级可达64核及以上)。每个核心都具备独立的运算、逻辑判断和数据处理能力,擅长处理复杂逻辑运算、分支跳转及各类系统级任务。其核心优势在于极高的灵活性,能够兼容几乎所有编程语言和计算任务,在人工智能系统中主要承担操作系统调度、数据预处理、任务分配等辅助性角色,是整个计算体系的“中枢调度员”。
硬件结构上,CPU配备了L1、L2、L3三级缓存,其中L1缓存集成在核心内部,读写速度最快(纳秒级),L2为核心专属缓存,L3为多核心共享缓存。三级缓存的设计旨在缓解CPU与片外DRAM主内存之间的速度差距。但DRAM主内存的读写速度远低于缓存,且数据传输需经过复杂路径,这导致CPU在处理人工智能领域大量存在的矩阵乘法、卷积运算等重复性数学运算时,容易出现数据传输瓶颈,运算效率低下,因此不适合作为人工智能核心运算硬件,更多发挥辅助调度作用。
GPU(图形处理器) 与CPU的设计理念截然不同,采用“众核架构”,将计算任务分散到数千个甚至上万个小型计算核心上。这些核心虽然单个运算能力较弱,无法处理复杂的逻辑分支,但具备极强的并行执行能力,能够对不同数据同步执行相同指令。这种特性使其成为人工智能模型训练的绝对主导硬件。深度学习模型(如CNN、Transformer)的核心运算就是矩阵乘法和卷积运算,这类运算逻辑简单、可高度拆解,能分配给GPU的多个核心并行处理,运算效率是CPU的数十倍甚至上百倍。
为支撑大规模并行计算,GPU配备了片上高带宽内存(HBM),其读写速度远高于CPU的DRAM内存,能快速为数千个核心提供连续的数据支撑,避免数据传输成为性能瓶颈。目前,GPU的核心数量普遍达数千个以上,例如NVIDIA的主流AI显卡核心数量可突破6000个。NVIDIA、AMD的GPU产品占据了人工智能训练硬件的主流市场,广泛应用于深度学习模型训练、科学计算、图像渲染等场景。
TPU(张量处理单元) 是谷歌专为神经网络设计的专用芯片,在GPU基础上实现更高专业化,核心目标是提升神经网络运算效率、降低功耗。其核心是乘加(MAC)单元网格,采用“波浪式”数据处理模式,减少数据传输次数,提升效率。与GPU不同,TPU执行过程由编译器精准控制,无硬件调度开销,适配大规模神经网络的训练与推理。谷歌的TPU已应用于自身搜索、翻译等业务,主要以云服务形式提供算力支撑。
NPU(神经处理单元) 是面向边缘设备的优化架构,核心是在低功耗下实现高效推理,适配智能手机、物联网设备等功耗受限的终端。它不追求高性能,注重功耗与体积控制,架构围绕包含MAC阵列和片上SRAM的神经计算引擎构建。NPU不使用HBM,采用低功耗系统内存,功耗控制在个位数瓦,片上SRAM减少片外内存访问,降低功耗。苹果神经网络引擎、英特尔NPU等均遵循此设计,支撑设备端人工智能任务落地。
LPU(语言处理单元) 是Groq公司推出的高度专用架构,专为语言模型推理优化,核心是“极致低延迟”。它彻底移除片外内存,所有权重存储在片上SRAM,避免内存访问延迟,运算过程由编译器调度,无缓存未命中和调度开销。LPU的缺点是片上SRAM容量有限,运行大型模型需数百个芯片集群,增加成本与复杂度,但在实时对话等低延迟场景优势显著,目前正处于市场推广阶段。
总体而言,人工智能计算从CPU的通用灵活,演进到LPU的高度专用,每一步都以牺牲部分通用性换取效率、功耗或延迟的优化。五种架构各有侧重、相互补充,构成人工智能硬件完整生态,支撑不同场景落地。下图并排展示了这五种技术的内部架构,可直观看出其结构差异。
本文转自媒体报道或网络平台,系作者个人立场或观点。我方转载仅为分享,不代表我方赞成或认同。若来源标注错误或侵犯了您的合法权益,请及时联系客服,我们作为中立的平台服务者将及时更正、删除或依法处理。

联系电话:
010-61853490
新闻投稿:
server@icviews.cn
商务合作:
business@icviews.cn
问题反馈:
19800315212(微信同号)


半导纵横公众号

半导纵横小程序