PCIe 7.0为什么那么重要?
在大模型与生成式 AI 爆发式发展的当下,算力芯片的性能正以指数级攀升,但数据互联瓶颈已取代单芯片算力极限,成为制约 AI 产业持续突破的关键。在传统 AI 计算架构中,超 70% 的训练时长被消耗在芯片间通信环节,“内存墙” 与 “互联墙” 的双重桎梏,导致海量算力无法充分释放,出现大规模闲置。
作为全球通用的高速互连标准,PCI Express(PCIe)始终是 AI 计算基础设施的核心底座。而随着 PCIe 7.0 完整规范于 2025 年正式发布,这一标准也正式迈入全面落地的阶段:MACOM 公司推出业界首款针对 PCIe 7.0 优化的线性均衡器和交叉点开关器件,进一步完善了光纤与铜缆互连领域的产品布局;是德科技推出的 XR8 平台、Scale-Up 验证方案,也已实现对 PCIe 7.0 标准的测试覆盖。
实际上,从 PCIe 6.0到7.0的代际跨越,不仅仅是一次普通的速率升级,而是锚定 AI 时代的核心需求,为AI芯片大规模集群提供了底层技术支撑。这一标准主要面向人工智能 / 机器学习、800G 以太网、高性能计算、量子计算及超大规模数据中心等对带宽有极致要求的领域,首批支持设备预计于 2026 年起逐步上市。要读懂 PCIe 7.0 的核心进化价值,首先需要厘清 AI 超算领域互联协议的三大核心层级,以及传统架构的固有局限。
AI网络互联的三个层级
AI 网络的互联体系,可按照传输距离、带宽与延迟等,划分为三个层级:
Scale-inside(片内互联):芯片内部不同芯粒(Die)之间的互联,要求极致带宽(单链路可达 10TB 级)与纳秒级超低延迟,传输距离通常在毫米级。
Scale-up(节点内 / 片间互联):面向单服务器节点内不同算力芯片之间的互联,典型场景为 GPU 与 GPU、各类 xPU(GPU/NPU/TPU 等)之间的高速通信,NVLink、UALink 等厂商专用协议均归属于这一层级。其传输距离在米级,带宽需求达 TB 级,主要实现节点内多芯片的高效协同,最大化单节点的算力规模。
Scale-out(网间互联):针对服务器集群之间的跨节点互联,典型代表为InfiniBand、RoCE 等数据中心级网络协议。传输距离可达百米级,是支撑万卡级甚至更大规模集群的弹性扩展,保障跨节点、跨机柜的高速数据同步,是超大规模 AI 分布式训练的关键。
长期以来,传统互联协议大多局限于单一层级,难以实现跨层级的高效协同,形成了相互割裂的互联格局。而 PCIe 7.0 正在打破这一层级壁垒,实现对多个互联层级的覆盖。
AI时代,PCIe 7.0 为什么重要?
PCI-SIG 于 2025 年正式发布 PCIe 7.0 完整规范,在延续 PCIe 6.0 核心架构的基础上实现了全方位升级,其核心特性与 AI 场景的核心需求深度绑定,不仅精准破解了行业现存的互联痛点,更实现了跨互联层级的历史性突破。
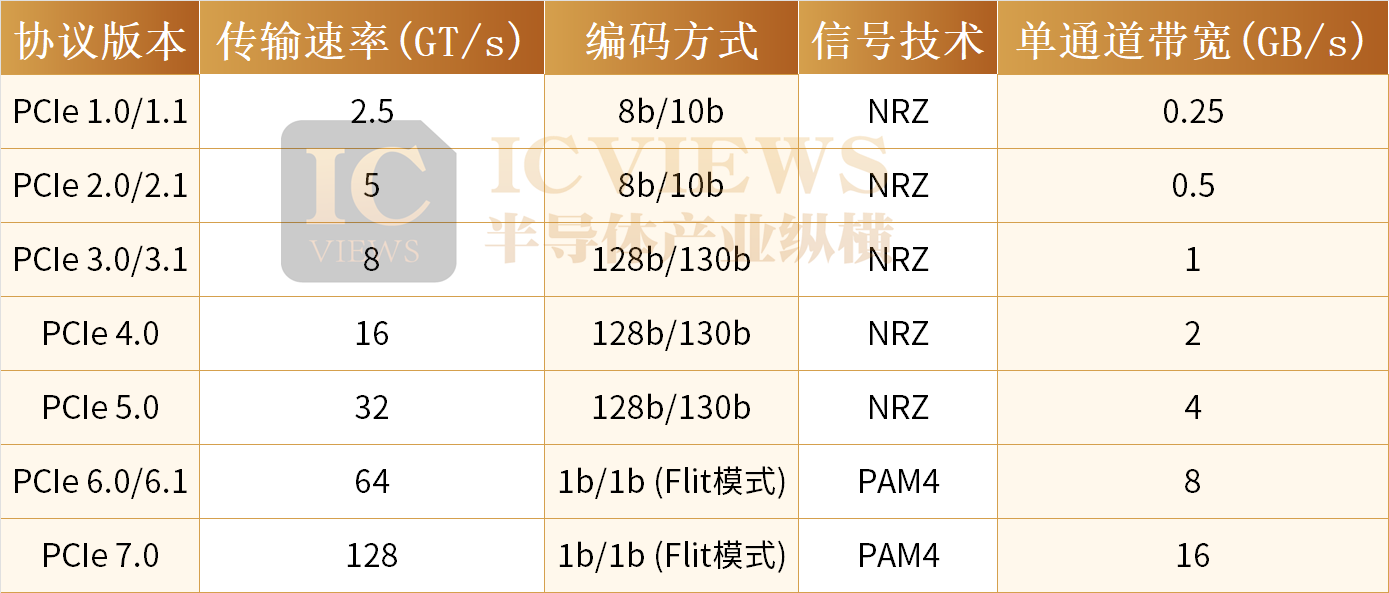
(一)PCIe 7.0相对PCIe 6.0的升级
第一、带宽翻倍,突破数据吞吐天花板。PCIe 7.0 单通道数据传输速率达到128 GT/s,相比上一代PCIe 6.0实现翻倍。在x16通道配置下,可提供高达512 GB/s的双向理论带宽。标准延续了PCIe 6.0引入的四级脉冲幅度调制(PAM4)信令和基于流控制单元(Flit)的1b/1b编码模式。
第二、协议层和物理层改进,实现极致低延迟。针对 AI 分布式训练的极致低延迟需求,PCIe 7.0 在协议层精简了 TLP(事务层数据包)处理流程,引入更高效的 乱序执行机制,提升指令并行度(如发射端口从 10 个增至 12 个);物理层则改进时钟恢复和均衡技术,降低信号抖动对延迟的影响,显著降低了传输延迟。
第三、 信号完整性与长距离传输能力跃升,适配集群化部署需求。PCIe 7.0 全面优化了 FEC(前向纠错)机制与 LTSSM(链路训练与状态机)容错能力,信道损耗容忍度提升至 - 36dB,支持最多 4 个重定时器,铜线传输距离可扩展至 24 英寸以上。与此同时,标准同步推出了 PCIe 光纤规范,彻底突破了铜线传输的物理限制,可实现跨机柜、跨机房的低延迟高速传输。
第四、 能效比与电源管理深度优化,破解数据中心功耗瓶颈。PCIe 7.0 通过降低信号电压摆幅、优化低功耗子状态、支持动态通道带宽调整,实现了对功耗的细粒度控制。根据 Synopsys 实测数据,其互联能效比前代标准最高提升 50%;同时增强了 L1 低功耗状态的快速唤醒能力,实现了低功耗与低延迟的动态平衡,完美适配 AI 推理场景的突发流量特性。
第五、 原生安全增强与全生态兼容,保障基础设施稳定运行。安全层面,PCIe 7.0 强化了 IDE(集成数据加密)机制,通过 AES-GCM 算法实现端到端全数据包加密,同时新增 Flit 错误日志寄存器,进一步提升了链路容错能力;兼容性层面,标准保持了对 PCIe 1.0 至 6.0 的全向后兼容,支持链路自动速率协商,可实现现有数据中心基础设施的平滑升级。
第六、 深度适配 CXL 4.0,为内存池化提供核心底座。PCIe 7.0 是 CXL 4.0 标准的物理层底座,基于 128 GT/s 的链路速率实现了 CXL 互联带宽的翻倍,原生支持跨多机架的全局内存池化,为 AI 计算场景下的内存资源解耦提供了核心底层支撑。
(二)打破层级壁垒,实现AI时代跨层级互联
AI 大模型训练与推理的核心需求,可归纳为 “高带宽、低延迟、高可靠、大规模协同”。PCIe 7.0打破了传统互联协议的层级局限,实现了对 Scale-up、Scale-out 两大层级的覆盖。
首先,带宽与低延迟的双重升级,深度适配 Scale-up 层级的核心需求。PCIe 7.0 x16 通道 512 GB/s 的双向带宽,已逼近 NVLink 等厂商专用片间互联协议的性能水平,纳秒级的端到端延迟也与 Scale-up 层级的需求高度匹配。这一突破使得 PCIe 7.0 可替代部分私有协议,直接实现节点内 GPU/NPU 之间的高速 P2P(点对点)通信,大幅提升了节点内多芯片的协同效率,同时为 Scale-up 层级构建了开放、通用的互联解决方案,打破了私有协议的生态壁垒。
其次,长距离传输能力与光纤规范的加持,实现了向 Scale-out 层级的能力突破。传统 PCIe 协议受限于传输距离,仅能覆盖 Scale-up 节点内互联场景,跨节点、跨机柜的 Scale-out 集群互联,长期依赖 InfiniBand 等专用网络协议。而 PCIe 7.0 通过信号完整性优化、重定时器扩展支持,结合全新的光纤规范,将有效传输距离延伸至百米级,可直接支撑 Scale-out 层级的万卡集群互联,实现超节点之间的高速数据同步,彻底打破了 PCIe 协议仅能用于节点内互联的固有局限。
PCIe 7.0 的代际进化,打破了此前 PCIe 协议的层级边界,实现了从 Scale-up(节点内)到 Scale-out(网间)的跨层级覆盖。传统超节点架构高度依赖 NVLink 等厂商私有互联协议,普遍存在生态封闭、部署成本高、跨厂商适配性差等痛点,而 PCIe 7.0 为超节点构建了通用、开放的标准化互联底座。凭借 x16 通道 512 GB/s 的双向带宽,PCIe 7.0 可完全满足超节点内 GPU/NPU 的高速 P2P 通信需求。
(三)基于PCIe 7.0的CXL 4.0,内存池化能力持续提升
除了打破层级壁垒,PCIe 7.0 的核心价值还体现在与 CXL 4.0 的深度融合上。CXL可实现存储池化与高速互连,进而提升计算效率。CXL规范自1.0以来,逐步增加新功能,至4.0版本采用PCIe 7.0,显著提升内存共享能力。从最初的CXL 1.0,让x86服务器能够访问外部设备中的PCIe 5.0链接内存,到CXL 2.0增加了内存池化功能,再到CXL 3.0引入了交换机和PCIe 6.0支持,CXL一直在不断进化。如今,CXL 4.0更是采用了PCIe 7.0技术,带宽翻倍至128 GT/s,同时引入了原生x2宽度和捆绑端口设计,支持4个重定时器以扩展链路距离。这些改进使得CXL 4.0在内存共享领域达到了新的高度。
英伟达正开始加速布局CXL互联能力,阿里云亦推出CXL存储池化服务器,提升推理吞吐。随CXL技术持续在AI领域渗透,有望拉动CXLMXC和CXLSwitch芯片需求。目前,CXL互连芯片相关厂商:包括澜起科技、聚辰股份、RAMBUS、ALAB等。
PCIe 7.0 与 CXL 4.0 的深度融合,可实现跨多机架的全局内存池化,将集群内所有内存资源整合并进行动态调度,GPU 可直接访问池化后的远端内存,访问延迟逼近本地内存水平。
PCIe 8.0:前瞻布局下一代 AI 计算的互联底座
在 PCIe 7.0 逐步进入商用落地阶段的同时,PCI-SIG 已同步启动 PCIe 8.0 标准的研发工作。该标准计划于 2028 年发布正式规范,将为下一代超大规模 AI 计算提供全新的互联底座,进一步强化并拓展跨层级互联的核心能力。
2025年6月,PCI-SIG宣布启动PCIe 8.0规范的制定工作。2025年8月,PCI-SIG正式公布了该规范的开发计划。2025年9月,版本0.3的草案完成并向会员开放。按照开发惯例,规范还将经历Version 0.5、0.7、0.9等阶段,最终在2028年推出1.0正式版本。
PCIe 8.0规范延续了自PCIe 6.0/7.0以来采用的PAM4(4级脉冲幅度调制)信号技术,并继续使用Flit模式编码。规范沿用并优化了前向纠错机制,以应对更高速度下的信号衰减与码间干扰,提升信号完整性与抗干扰能力。
DesignCon 2026大会上,产业链厂商已率先展示了 PCIe 8.0 的相关技术成果,印证了其技术可行性:Synopsys 首次展示了 PCIe 8.0 级别的电气性能(包括眼图测试、接收端性能等),验证了其单通道 256 GT/s 的传输速率能力,x16 全链路下双向带宽可高达 1TB/s——需要说明的是,此次展示仅为基于现有芯片和技术实现的物理层 PHY IP,是信号完整性与物理层面的早期里程碑,距离完整的 PCIe 8.0 控制器仍有一定距离。同期,Marvell 也同步展示了 PCIe 8.0 SerDes 方案,演示采用了 TE Connectivity 提供的 AdrenaLINE Catapult 连接器,共同推动 PCIe 8.0 技术的落地进程。
结语
从 PCIe 7.0 的正式落地到 PCIe 8.0 的前瞻布局,高速互连技术的演进始终与 AI 产业的发展同频共振。如果说 AI 芯片是智算时代的 “心脏”,为产业发展提供澎湃算力;那么 PCIe 标准就是智算时代的 “血管系统”,唯有血管通畅无阻,海量算力才能得到充分释放。
PCIe 7.0 的核心突破,在于彻底打破了传统互联协议的层级壁垒,实现了从 Scale-up 到 Scale-out 的跨层级覆盖;而 PCIe 8.0 则在前瞻布局中进一步放大这一优势,将跨层级互联能力推向新的高度,为下一代超大规模 AI 计算与 AGI 的落地铺平道路。
此内容为平台原创,著作权归平台所有。未经允许不得转载,如需转载请联系平台。

联系电话:
010-61853490
新闻投稿:
server@icviews.cn
商务合作:
business@icviews.cn
问题反馈:
19800315212(微信同号)


半导纵横公众号

半导纵横小程序