微电子学院曾晓洋/薛晓勇课题组在SRAM存内计算数据高效存储和更新方面取得重要进展
存内计算会大幅度减少数据在处理器和存储器之间的频繁搬运,可以有效解决传统冯·洛伊曼计算架构的存储墙、功耗墙问题。实现存内计算,要么在主存内部集成定制逻辑,要么在SOC或者集成芯片内部把数据(比如权重)缓存利用阵列自带逻辑或者近存逻辑。前一条技术路径主要是三星、海力士等主存大厂在推进,因为要在DRAM内部做定制化设计,当然也可以在主存控制器方面做一些工作实现近存计算。后一条技术路径依赖在SOC或集成芯片内部的嵌入式存储器(SRAM、eDRAM、eNVM、eFlash等)实现计算,这一路径对存储的容量和成本提出了很高的要求,因为目前AI加速等应用的参数量过于庞大(端侧可能少点),把所有必要的数据缓存在片上会遭遇很大的可靠性和成本挑战。
在可预见的将来,由于嵌入式存储器在容量、可靠性、成本方面相比DRAM仍存在较大差距,以嵌入式存储器为载体的存内计算要实现大算力还存在比较大的挑战,而且存内计算的通用性相对受限。因此,研究人员认为以嵌入式存储为载体的存内计算以加速器的形式配合其他的计算资源比如GPU、FPGA或CPU实现大算力更为合理。同时,嵌入式存储要具有较高的存储密度和较低的写入功耗,从而在算法参数量比较大时实现数据的低开销存储和更新。基于上述考虑,复旦大学微电子学院和集成芯片与系统全国重点实验室曾晓洋、薛晓勇课题组提出可以实现数据高效存储和更新的SRAM存内计算及配套电路技术,相关成果以“A 28-nm 36Kb SRAM CIM Engine with 0.173 μm2 4T1T Cell and Self-load-0 Weight Update for AI Inference and Training Applications”为题被集成电路设计领域的顶级期刊IEEE Journal of Solid-state Circuits录用。论文链接:https://ieeexplore.ieee.org/document/10535738。
在该工作中,研究人员设计了一个在28nm工艺代容量为36Kb的SRAM存算一体加速引擎,可应用于SOC或集成芯片实现AI推理和训练加速。针对存内计算的需求,定制了一个仅包含5个晶体管(4T+1T)的SRAM单元结构,以接近6T单元的尺寸获取8T单元所具有的非破坏读功能。该4T1T SRAM单元尺寸仅为0.173um2,相比代工厂(Foundry)8T SRAM单元尺寸小40%以上。该4T1T SRAM单元还可通过上电自载0节省更新能耗和延迟,较好地迎合了目前神经网络权重较为稀疏的特点。另外,该工作提出三项电路措施提升存内计算的效率、精度和适用性:共享路径双模读取(SPDMR)以更少的电路开销支持FF(前向通路)和BP(反向传播);比特交织权重映射(BIWM)在不减慢FF的情况下加快了BP路径;具有分层读字线(RWL)和读位线(RBL)的IR压降感知自适应箝位器(IRDAA-C)实现在阵列内部远/近单元上施加精确的电压。该存算一体加速引擎在1位权重/1位激活的精度配置下对FF/BP分别实现263.1/412.1 TOPS/W的能量效率、2.5/4.9 TOPS/mm2的面积效率,权重更新能耗减少74.4~78.3%。
复旦大学微电子学院和集成芯片与系统全国重点实验室为上述论文的第一完成单位,博士生赵晨阳为第一作者,薛晓勇副研究员为通讯作者,其他作者包括曾晓洋教授、周鹏教授、韩军研究员、博士生方晋北等。该工作得到了科技部重点研发计划STI 2030重大项目(2022ZD0209200)、国家自然科学基金(62274038、61934002、62222119)、上海市科委探索者计划(21TS1401200)以及中兴通讯产学研合作基金(1A20230201004)的资助。
 论文提出的可以实现数据高效存储和更新的4T1T SRAM单元
论文提出的可以实现数据高效存储和更新的4T1T SRAM单元
 SRAM存内计算加速引擎架构
SRAM存内计算加速引擎架构
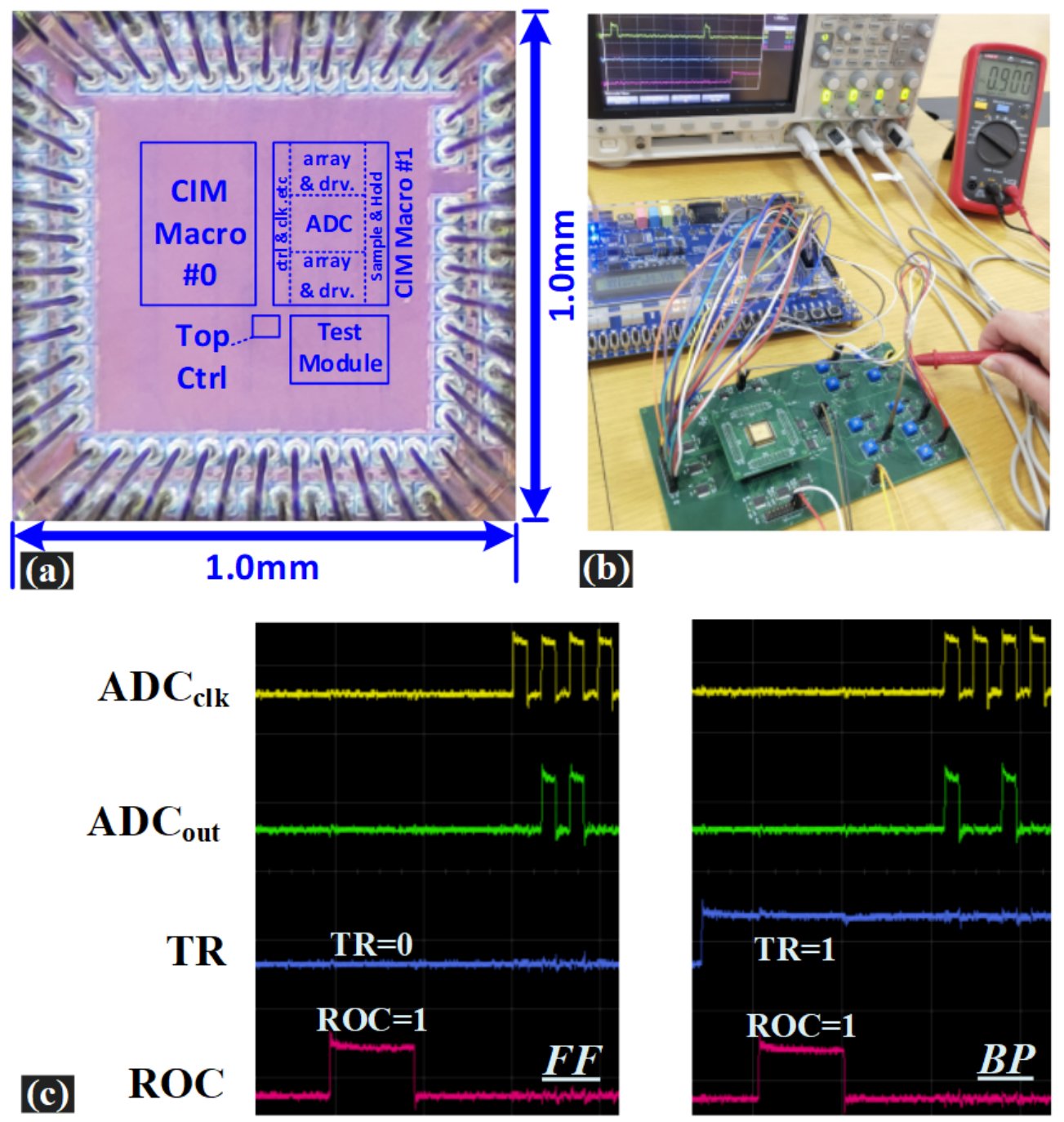 SRAM存内计算测试芯片及关键测试结果
SRAM存内计算测试芯片及关键测试结果
本文转自媒体报道或网络平台,系作者个人立场或观点。我方转载仅为分享,不代表我方赞成或认同。若来源标注错误或侵犯了您的合法权益,请及时联系客服,我们作为中立的平台服务者将及时更正、删除或依法处理。




联系电话:
010-61853490
新闻投稿:
server@icviews.cn
商务合作:
business@icviews.cn
问题反馈:
19800315212(微信同号)


半导纵横公众号

半导纵横小程序