AI推理,重塑数据中心架构
业界已逐渐形成共识:AI 推理正在从根本上重塑数据中心架构。随着推理负载成为主流,数据中心网络不再仅仅是服务器之间的通信层,它正日益成为分布式内存与存储层级的一部分,直接影响性能、效率与成本。
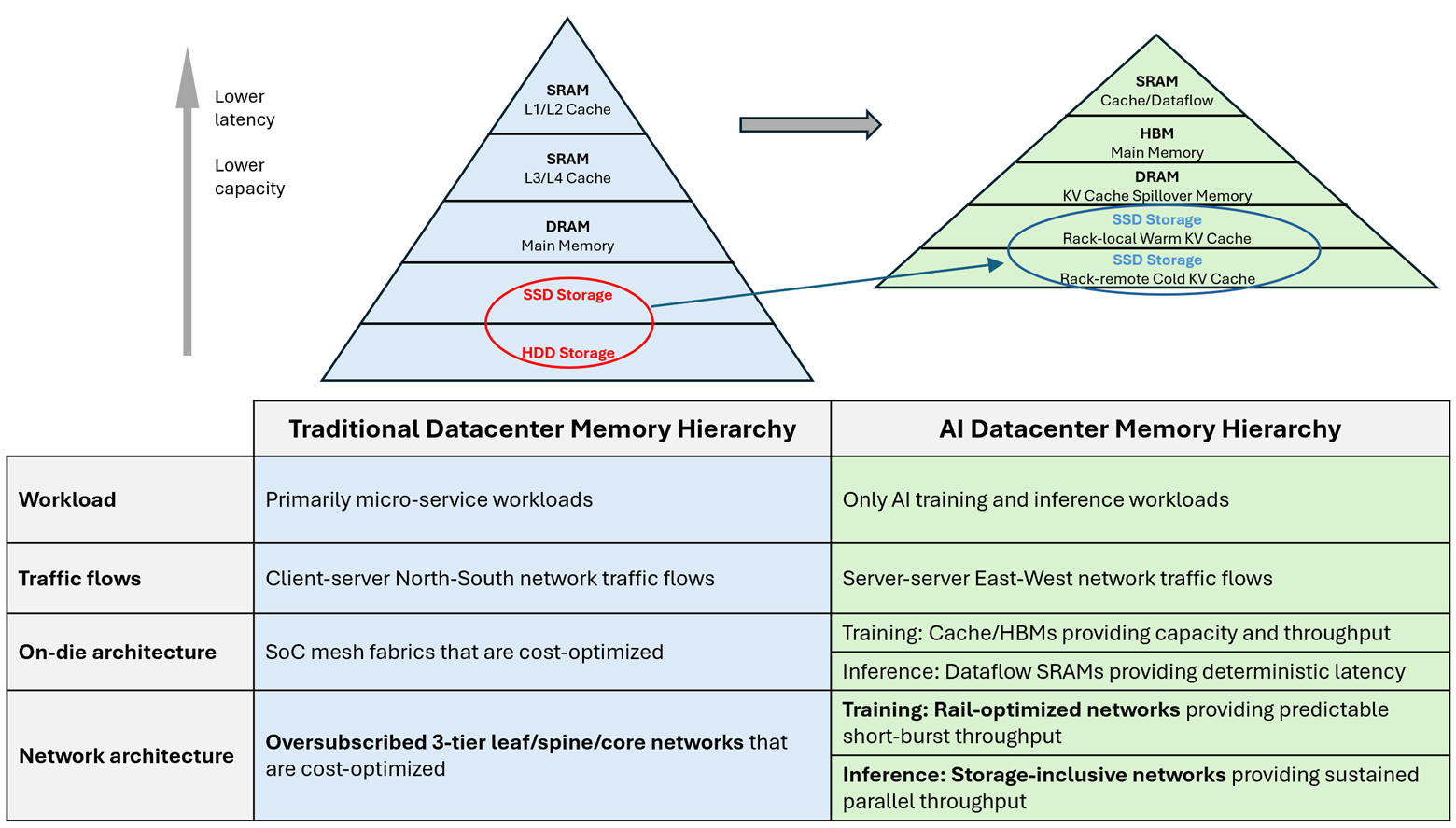
传统数据中心与概率性行为
在传统数据中心时代,微服务与客户端-服务器交互是主流负载。流量模式总体呈概率性、突发性,且以南北向流量为主。内存访问与数据读取由缓存缺失概率决定,而非确定性访问模式。
这种概率性行为塑造了片上与网络架构。片上互联结构(如 SoC 网状网络)之所以流行,是因为它们针对平均情况做了成本优化,而非面向最坏情况的确定性设计。在网络层面,超额配比的三层叶 — 脊 — 核心网络得到广泛部署。延迟固然重要,但尾部延迟并无严苛要求,短暂的拥塞事件可以被接受,因为流量稀疏且突发持续时间短。
在这种环境下,缓冲机制与ECMP等统计流量分发方案表现良好。即使多条流汇聚,局部网络拥塞通常也是短暂的;借助网络链路缓冲吸收小规模局部过载突发,系统级性能平均仍可维持。
AI 训练与短时突发通信
大规模 AI 训练从根本上改变了数据中心内部的流量模式。训练负载带来了结构化、服务器到服务器的东西向通信,并以集合通信操作为主。这些集合操作在 GPU 之间产生高度同步、带宽密集的短时通信突发。
训练负载的特性推动了全栈架构变革。片上方面,HBM 等高带宽内存变得至关重要,为训练算法提供足够容量与吞吐量。网络层面,面向轨道优化的互联架构逐渐成为一种性价比较高的方案,可在紧耦合 GPU 之间提供向上扩展域内无阻塞、带宽有保障、低延迟的通信能力。
一个重要但常被低估的点是:训练互联架构依靠缓冲与内部加速来应对瞬时入站拥塞(incast)—— 即多个源以线速向同一超额配比目标发送流量的场景。在集合通信阶段,许多 GPU 链路可能短暂指向同一目标,但拥塞是瞬时的。缓冲区吸收突发流量,流量快速排空,后续阶段通信模式随之改变。调度器有助于任务对齐,但无需完美避免入站拥塞,系统仍可良好运行。
AI 推理带来持续性内存与存储流量
推理负载带来了截然不同的压力模式。推理所需的内存与存储规模超出单芯片容量,导致需要频繁从池化内存与存储系统中加载 KV 缓存状态。这些访问会产生持续性长流(elephant flows)。与训练的突发流量不同,这些流长生命周期、连续不断。单次推理请求可能需要从远端 DDR 或基于闪存的 SSD 层级流式读取数十 GB 的 KV 缓存数据,且同类请求持续不断到来,结果是相同网络路径承受持久压力。
在面向短时突发训练或概率性微服务流量设计的网络中,这会导致持续性拥塞,而非瞬时拥塞。缓冲机制不再能挽救系统,因为持续性流最终会溢出任何合理大小的缓冲区。对于 KV 缓存大量读写带来的长时持续性长流,ECMP 的随机性无法起到分流作用,而其他路径则完全闲置。
这正是关键架构转变发生之处:存储不再是通过南北向路径偶尔访问的外部服务,它本身成为基于高性能网络的内存架构的一部分,而网络必须被设计为可大规模支撑并行、长生命周期的吞吐量。
相似拓扑,更严苛要求
从高层看,推理网络可能仍类似面向轨道优化的设计。高带宽域将GPU与邻近的内存、存储资源相连,而域间互联则更为受限,以控制成本与复杂度。从这个意义上说,推理架构建立在训练所积累的经验之上。
然而,这些域内部的性能承诺必须改变。推理需要确定性、持续性的吞吐量,而非时间维度上的平均吞吐量。内存与存储端点必须被视作与向上扩展系统中的片上内存控制器类似的节点,互联架构需在持续负载下提供可预测的访问能力。
在训练集群扩展中已变得重要的高radix 交换机,如今承担着更为关键的角色。通过实现更扁平、更宽的互联架构,它们减少瓶颈,限制长时竞争,并使大规模内存与存储池集成到无阻塞高性能域成为可能。
展望未来
AI 训练教会行业如何针对短时突发通信模式高效扩展计算与数据移动能力。而 AI 推理正在教会行业如何在持续负载下扩展内存与存储访问能力。随着推理成为主流负载,性能将越来越不由原始算力决定,而是由 GPU 通过网络访问分布式内存与存储的效率决定。
这一转变要求网络层面的创新。更高链路速率、更高 radix 交换机、更扁平的无阻塞架构正变得至关重要,以在不依赖统计随机性的前提下提供极致性能保障,同时仍能控制基础设施成本、功耗与研发周期。
数据中心网络不再只是连接系统的通道,它正在成为决定AI性能的内存架构。
本文转自媒体报道或网络平台,系作者个人立场或观点。我方转载仅为分享,不代表我方赞成或认同。若来源标注错误或侵犯了您的合法权益,请及时联系客服,我们作为中立的平台服务者将及时更正、删除或依法处理。




联系电话:
010-61853490
新闻投稿:
server@icviews.cn
商务合作:
business@icviews.cn
问题反馈:
19800315212(微信同号)


半导纵横公众号

半导纵横小程序