AI硬件,突破内存墙
从通用计算转向 AI 专用硬件,其核心驱动力是深度学习模型特有的计算与能耗需求。随着这些模型规模扩展至万亿参数,传统架构遭遇存储墙瓶颈:存储器与处理单元之间数据搬运所消耗的能耗,已远超计算本身的能耗。
标准 CPU 与 GPU 架构为何无法满足 AI 负载需求?
中央处理器(CPU)受限于面向通用任务设计的窄位宽向量处理单元与复杂缓存层级,在高并发 AI 运算中会引入显著延迟。图形处理器(GPU)虽具备更高并行度,但其基于冯・诺依曼架构的设计,会带来巨大功耗与内存带宽限制。
为解决这些问题,硬件架构师正采用多层级设计思路,覆盖材料、电路、架构与封装等多个层面。
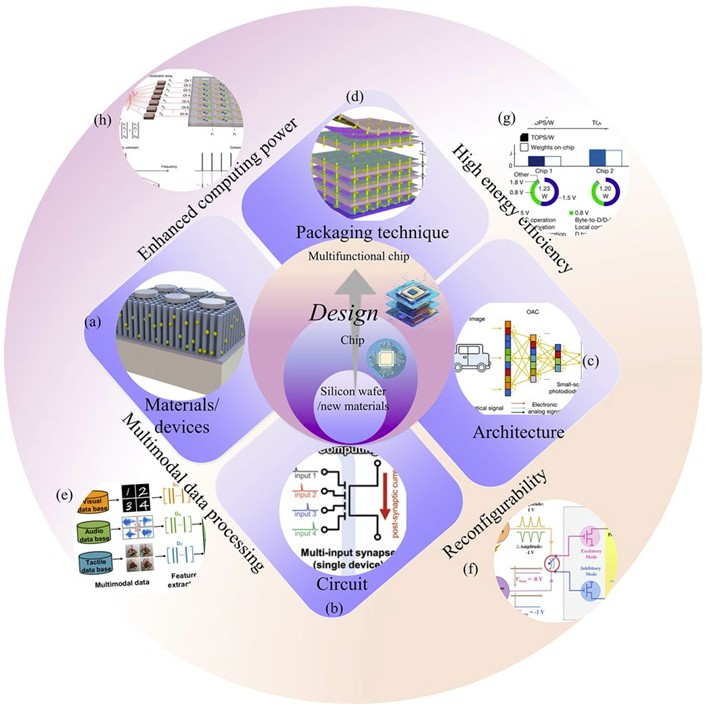
图 1 先进 AI 芯片的多层级设计空间,涵盖材料、电路、架构与封装
设计工作通常围绕四大技术支柱展开,这也是多层级设计理念的核心拆解方向。计算吞吐量:采用光子计算、大规模并行化等架构范式,提升每秒运算次数。能效:运用存内计算(CIM)及阻变存储器(ReRAM)、相变存储器(PCM)等非易失性存储技术,降低数据搬运的能耗成本。架构可重构性:设计可针对不同神经网络拓扑与持续演进算法进行优化的硬件。多模态数据融合:通过 3D 单片集成整合不同处理单元,实现低延迟同步处理视觉、听觉与文本数据。
AI 硬件加速的核心架构组件有哪些?
向领域专用架构转型离不开多个基础组件,下表按其功能与应用场景进行了分类:
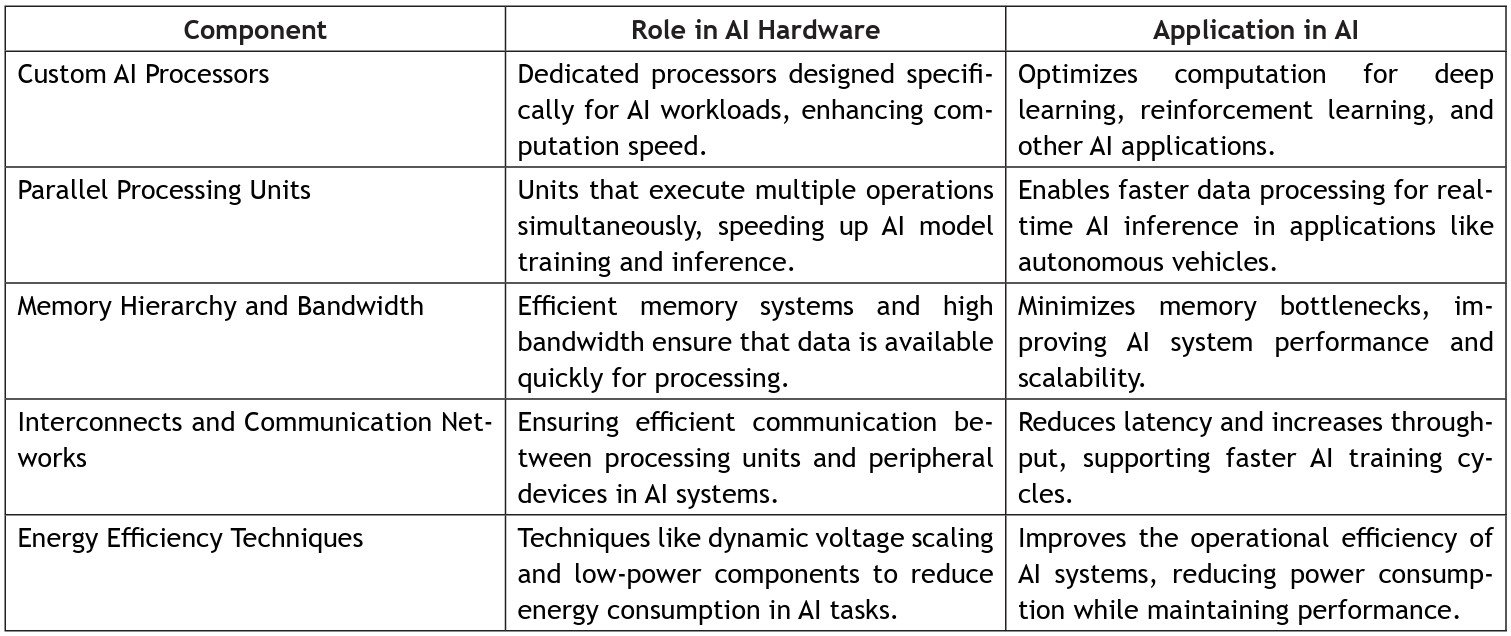
表 1 领域专用 AI 加速器的关键架构组件及功能定位
并行处理单元:用数千个小型并发单元替代通用控制逻辑,最大化矩阵密集型任务的吞吐量。
存储层级优化:采用高带宽互联与大容量片上缓存,保证计算单元的数据供给,减少对片外 DRAM 的访问需求。
能效管理:通过动态电压与频率调节、低精度运算(如 INT8、FP8、FP4)等技术,使硬件在特定热功耗范围内工作,同时推理精度无明显下降。
数据中心环境如何实现高吞吐量?
数据中心推理通常采用专用集成电路(ASIC),例如谷歌张量处理单元(TPU)。该架构的内部数据通路与控制接口框图。
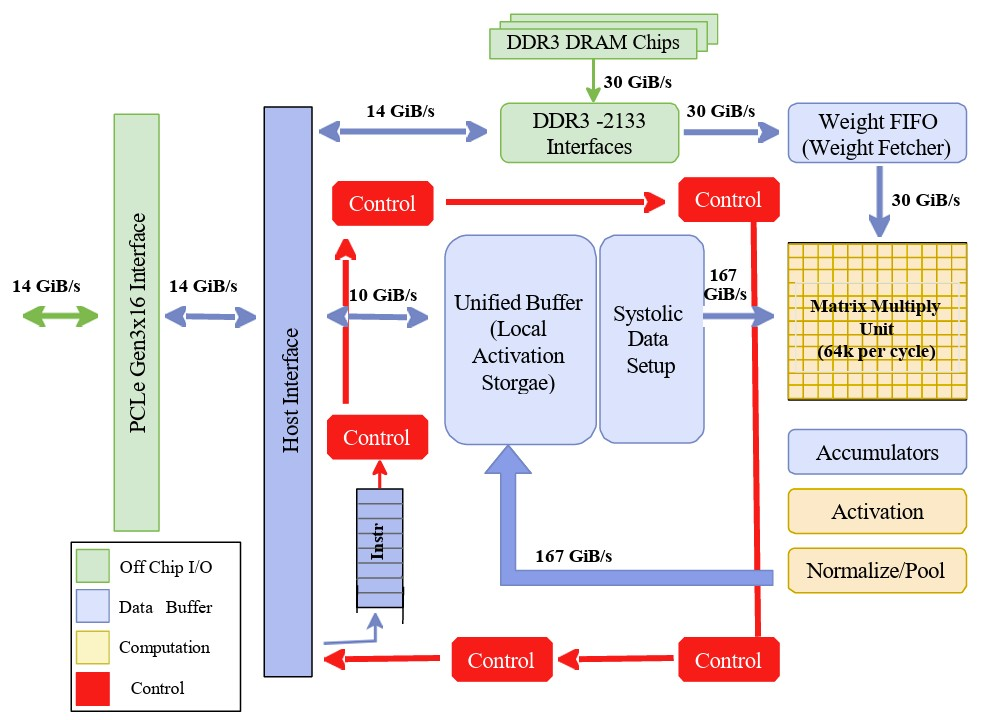
图 2 谷歌张量处理单元(TPU)系统级架构,重点标注矩阵乘法单元与脉动数据流
云端 ASIC 中的矩阵乘法单元采用脉动数据流架构。数据以规整节奏流经算术逻辑单元阵列,中间结果在 ALU 之间直接传递,而后再写回存储器。
该设计最大化数据复用率,使处理器每个时钟周期可执行数万次运算,满足大规模矩阵 - 向量乘法的需求。
边缘加速器与云端系统在功耗管理上有何差异?
边缘加速器需在极为严苛的功耗限制下工作,功耗通常低于 25 毫瓦。这要求算法 - 硬件协同设计,即软件与芯片同步设计以优化资源利用。典型案例为 Navion 芯片,其集成的前端与后端架构如图所示。
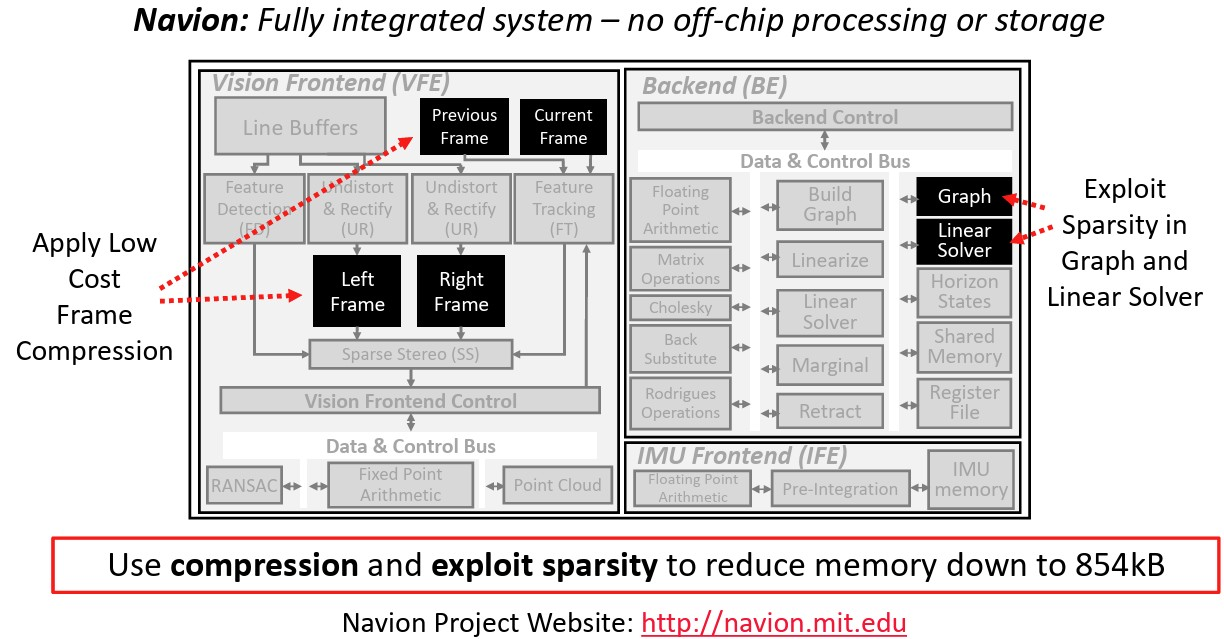
图 3 采用算法 - 硬件协同设计的 Navion 芯片架构,针对边缘机器人视觉惯性里程计(VIO)进行优化
为摆脱对片外 DRAM 的依赖,工程师在 Navion 架构中采用了多项关键技术。硬件级数据压缩:在图像采集端直接压缩视觉数据,减小存储所需内存占用。稀疏性利用:硬件专门针对视觉惯性里程计算法中后端位姿图与线性求解器的天然稀疏性进行设计,降低片上存储占用并减少处理周期。前端耦合:视觉前端与惯性测量单元前端深度集成并共享存储,将片上存储需求降至约 854KB。
总结
AI 硬件设计的进步,本质上是为应对冯・诺依曼架构固有的存储墙问题。通过多层级设计理念,工程师可从材料、电路到封装层面全面优化性能。
在云端,这一思路催生出基于脉动阵列的高吞吐量 ASIC,支撑大规模并行矩阵运算。在边缘端,极小的功耗预算要求紧密的算法 - 硬件协同设计,通过帧压缩与稀疏性利用,在不使用片外存储器的前提下保证功能精度。该领域的未来发展方向,将是异构计算的协同调度,以及向存内计算全面转型,从根本上消除数据搬运瓶颈。
本文转自媒体报道或网络平台,系作者个人立场或观点。我方转载仅为分享,不代表我方赞成或认同。若来源标注错误或侵犯了您的合法权益,请及时联系客服,我们作为中立的平台服务者将及时更正、删除或依法处理。

联系电话:
010-61853490
新闻投稿:
server@icviews.cn
商务合作:
business@icviews.cn
问题反馈:
19800315212(微信同号)


半导纵横公众号

半导纵横小程序