宇树王兴兴,迈过具身智能ChatGPT时刻
全球最受瞩目的“科技春晚”——英伟达GTC 2026大会正式开幕。宇树科技创始人王兴兴在GTC大会演讲中表示,具身智能要迎来ChatGPT时刻,意味着在80%的陌生场景中,通过语音或文字指令,机器人能够顺利完成大约80%的任务。为了解决上述问题并真正实现具身智能,不能单靠一家公司,需要更多的全球合作
在演讲中,王兴兴先是介绍了宇树科技极具代表性的各个机器人,Unitree G1、Unitree A2、Unitree H2、Unitree As2。在这些机器人演进过程中,就不得不提到RL模型。RL模型是让机器人自主学习最优控制策略的核心框架,本质是通过与环境交互试错,学习 “状态→动作” 的映射关系,最终实现特定任务(如机械臂抓取、移动机器人导航、无人机避障等)。
王兴兴表示,宇树RL控制模型开发历程大致可以分为五个阶段,2023 V1.0,基本行走和跑步:相对固定的姿态动作;2024 V2.0,行走、跑步、舞蹈和功夫等,全身流畅的动作序列;2025 V3.0,格斗等,全身任意流畅的动作序列,任意组 合,抗干扰;2025 V4.0,任意动作下,被强力干扰倒地后,快速自恢复;2025 V5.0,全身动态遥操作,任意动作。

谈及此次主题具身智能如何迈过ChatGPT时刻,王兴兴认为当前面临三大核心挑战。一是要提高模型对任务的表达能力,突破泛化瓶颈。模型本身的表达能力、运动表达能力一定要强,要实现这个目标,多模态模型、感知及编码器和解码器等都需要继续改进;二是要提升模型对多元数据的利用率,增强知识迁移。与语言模型有所不同,机器人模型是非常稀缺的,在此情况下,若依靠海量数据才能把模型训练出来,整个利用率是有点低的,因此要尽可能在模型训练或者预训练阶段,先把基础模型训练出来,提高对真机数据的利用率;三是提高强化学习规模效应,实现多任务近最优能力。目前业内大多做法是在机器人强化学习训练好了之后,数据就丢掉了,每次新动作都要重新训练,是否可以把这些数据收集起来放到一个大模型里,二次利用,尽可能多训练。
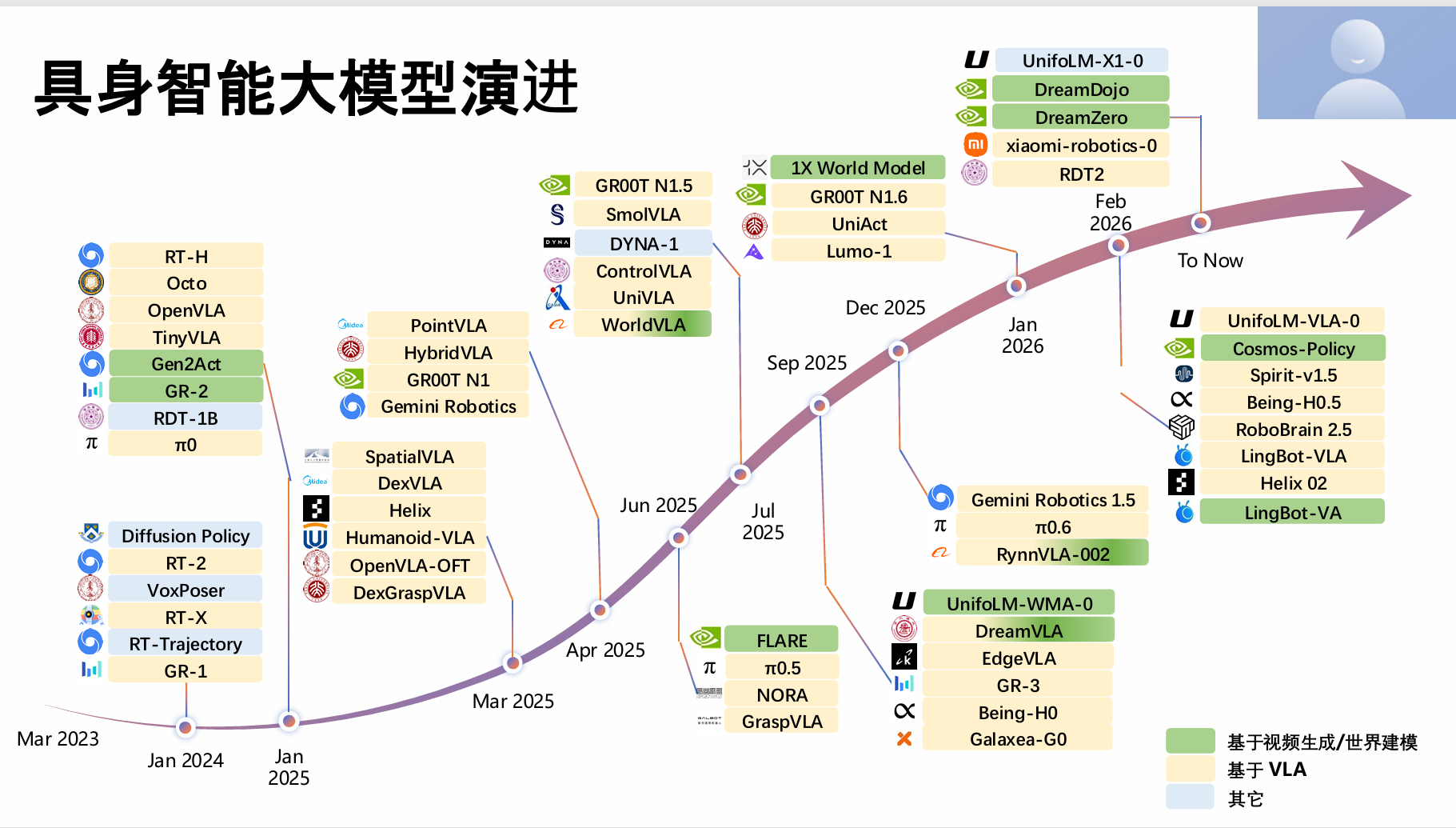
在具身智能大模型领域,赛道很火热,各种各样模型层出不穷。在这些不同类型的模型中,王兴兴更看好世界模型和视频生成模型,天花板很高,未来会是主流的方向。宇树科技开源了基于视频生成的模型UnifoLM-WMA-0,以及通用人形机器人视觉 - 语言 - 动作(VLA)大模型UnifoLM-VLA-0。
最后,王兴兴提到具身智能的ChatGPT时刻是在80%的陌生场景中,通过语音或文字指令,机器人能够顺利完成大约80%的任务。为了解决上述问题并真正实现具身智能,我们需要更多的全球合作。
本文转自媒体报道或网络平台,系作者个人立场或观点。我方转载仅为分享,不代表我方赞成或认同。若来源标注错误或侵犯了您的合法权益,请及时联系客服,我们作为中立的平台服务者将及时更正、删除或依法处理。

联系电话:
010-61853490
新闻投稿:
server@icviews.cn
商务合作:
business@icviews.cn
问题反馈:
19800315212(微信同号)


半导纵横公众号

半导纵横小程序