刚刚,黄仁勋又让整个硅谷睡不着了
圣何塞SAP中心,凌晨2点。黄仁勋再次穿着那件似乎永远不会旧的黑皮衣走上台。这场长达2小时的演讲中,老黄扔出了狂扔“核弹”。
第一颗炸弹:Vera Rubin平台。七款全新芯片全面投产,Vera Rubin平台由七款突破性芯片、五个机架和一个巨型超级计算机组成。同时发布Vera CPU,效率是传统机架式CPU的两倍,速度提升50%。
第二颗炸弹:1万亿美元。 黄仁勋在台上宣布,英伟达目前看到了至少1万亿美元的需求订单,覆盖到2027年。
第三颗炸弹:Token成为商品。“Token是新的商品。”黄仁勋公开详细阐述了AI工厂的商业模式——Token的分层定价体系,从免费层到premium层。
第四颗炸弹:为OpenClaw社区发布 NemoClaw。这款开源项目“在几周内就做到了linux 30年才做到的事”,黄仁勋断言:“每一家公司都需要OpenClaw战略。”
这场发布会留下了太多需要消化的信息。芯片、工厂、机器人、AI Agent......每一个词都可能是下一个万亿市场的入口。如果你今晚错过了这场直播,这篇文章会告诉你黄仁勋到底说了什么。
01芯片核武器库
Vera Rubin来了。
Vera Rubin是英伟达为“代理式AI”(Agentic AI)专门设计的新一代计算平台。
与上一代Blackwell 平台相比,Vera Rubin展现了惊人的效能跃进。该系统仅需1/4的GPU 即可完成混合专家大模型(MoE)的训练,且每瓦推论吞吐量飙升高达10 倍,成功将单Token的生成成本降至十分之一。在基础设施配置上,新一代的NVL72机架通过第六代NVLink连接了72块Rubin GPU与36块Vera CPU。黄仁勋特别指出,第六代NVLink交换系统是极度难以实现的技术,但英伟达成功达成了这项创举。

此外,Vera Rubin系统采用100%液冷设计,使用45°C的温水进行冷却,彻底移除了传统繁杂的缆线。这不仅大幅减轻了数据中心的冷却压力与能源成本,更将过去需要花费两天才能完成的安装时间,惊人地缩短至仅需两小时。
该平台整合了Vera CPU、Rubin GPU、NVLink 6 交换机、ConnectX - 9 超级网卡、BlueField - 4 DPU和Spectrum-6 以太网交换机,以及新集成的Groq 3 LPU。这些芯片协同工作,构成一台强大的AI 超级计算机,为 AI 的各个阶段提供支持——从大规模预训练、后训练和测试时扩展,到实时智能推理。
黄仁勋表示:“Vera Rubin 是一次代际飞跃——它由七款突破性芯片、五个机架和一个巨型超级计算机组成,旨在为人工智能的各个阶段提供强大支持。”
Vera CPU强势登场
本次大会的一大亮点,是英伟达首度展现其在中央处理器(CPU)领域的强大野心。英伟达最初于2022年GTC大会上发布了第一代Grace CPU,今晚老黄正式发布了Vera CPU和Vera CPU机架,标志着英伟达正式进军CPU直销领域,成为传统CPU市场中英特尔和AMD的有力竞争对手。
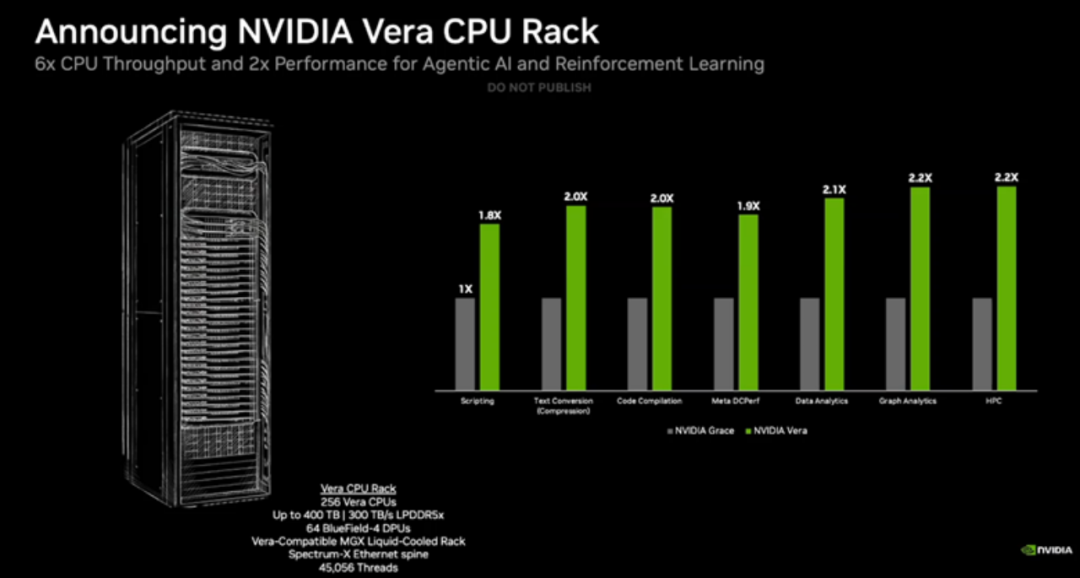
Vera CPU的定位是大规模数据处理、AI 训练和智能体推理场景,其效率是传统机架式CPU 的两倍,速度提升50%。
为了应对AI使用工具时所需的极速反应,Vera CPU专为极高的单线程效能、强大的资料处理能力与极致的能源效率而设计。单颗Vera芯片配备了88个核心与144个线程,采用英伟达深度定制化的Arm v9.2-A Olympus核心,其指令级平行度(IPC)实现了1.5倍的代际提升。
更具革命性的是,该架构首发引入了"空间多线程(Spatial Multithreading)"黑科技,通过实体隔离流水线组件,让多个线程能真正在单核上同时运行,彻底消除了传统多线程技术因资源排队而造成的算力损耗。Vera CPU也是全球首款采用LPDDR5的数据中心CPU,提供无与伦比的单线程效能与每瓦效能。
作为NVIDIA Vera Rubin NVL72平台的一部分,Vera CPU通过NVLink-C2C互连技术与GPU配对,提供1.8 TB/s的相干带宽(是PCIe Gen 6带宽的7倍),实现CPU和GPU之间的高速数据共享。
英伟达表示,阿里巴巴、CoreWeave、Meta和Oracle云基础设施,以及戴尔科技、HPE、联想、超微等全球系统制造商都与NVIDIA合作部署Vera。同时,英伟达发布了Vera CPU机架,提供基于NVIDIA MGX的密集型液冷基础设施,集成256个Vera CPU,可提供可扩展、节能的容量以及世界一流的单线程性能,从而大规模释放智能AI的潜力。
Vera CPU目前已全面投产,预计将于今年下半年开始交付。
收购Groq后,LPU登场
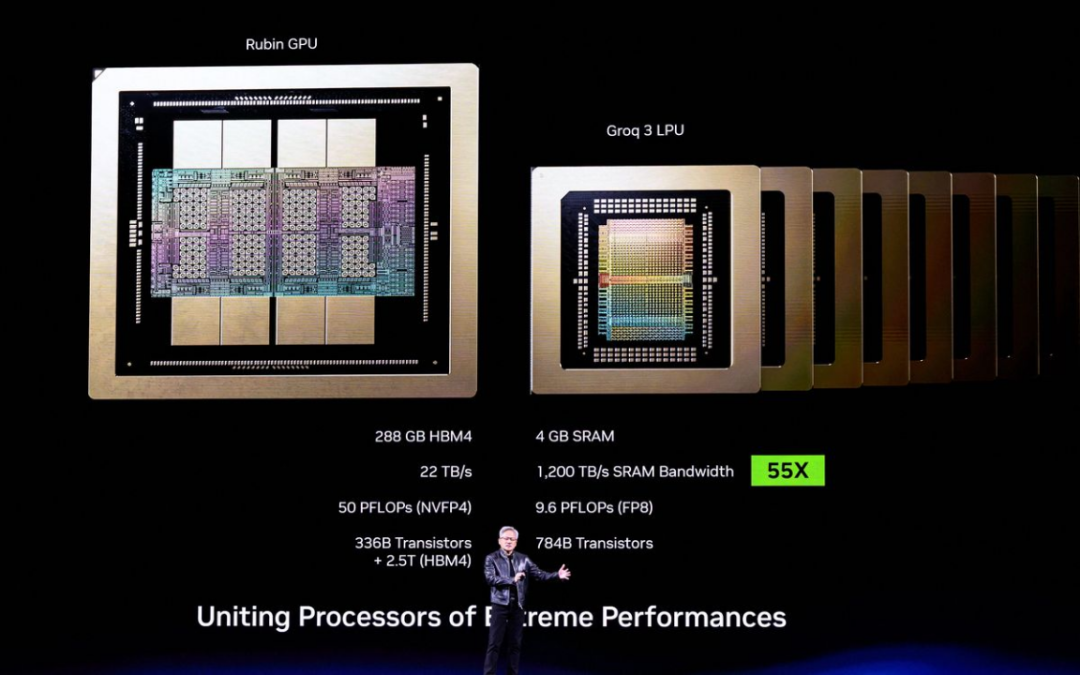
英伟达收购了开发Groq芯片的团队,并将其技术与Vera Rubin深度整合。
为什么需要LPU?
与大多数依赖HBM作为工作内存层的AI加速器不同,Groq 3 LPU每个芯片都集成了500MB的SRAM。这种内存也用于CPU和GPU的超高速缓存。虽然与每个Rubin GPU上容量高达288GB的HBM4相比,这显得微不足道,但这块SRAM可提供150 TB/s的带宽,远高于HBM的22 TB/s。对于带宽敏感型AI解码操作而言,Groq 3芯片带宽的大幅提升为推理应用带来了诱人的优势。
两种处理器的统一:LPU + Vera Rubin。“我们想出了一个绝妙的主意,”黄仁勋解释道,“我们将推理过程完全重新架构。我们把适合Vera Rubin的工作放在Vera Rubin上,然后把解码生成、低延迟、带宽受限的部分卸载到LPU上。”
这两种极端处理器的统一:一个为高吞吐量,一个为低延迟,产生了令人震惊的效果:每兆瓦功耗的推理吞吐量最高可提升35倍,万亿参数模型的收益机会最高可提升10倍。
“35倍,”黄仁勋重复了一遍,“这是世界从未见过的。”
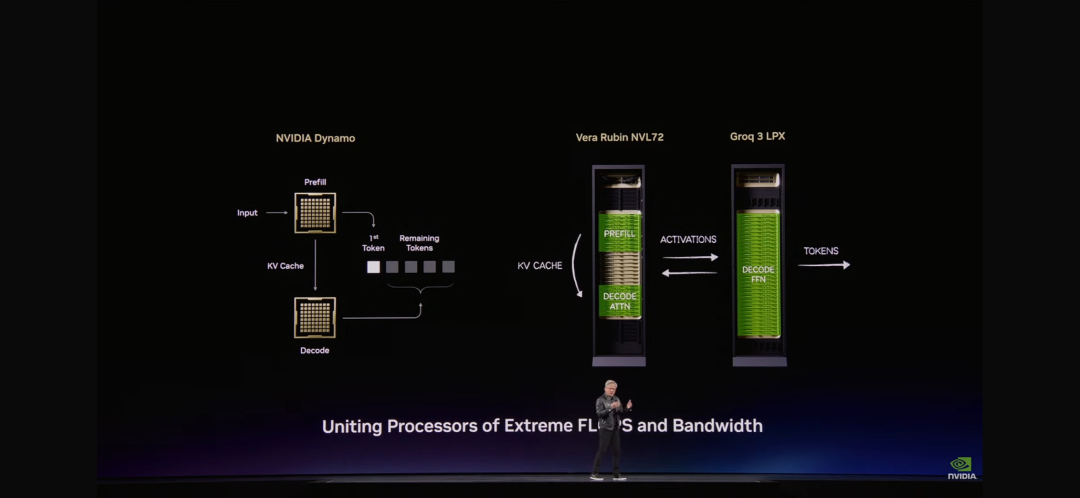

英伟达构建了包含256个Groq 3 LPU的Groq 3 LPX机架。该机架提供128GB的SRAM和40 PB/s的推理加速带宽,并通过每个机架640 TB/s的专用扩展接口将这些芯片连接起来。
大规模部署时,LPU 集群可作为一个巨型单处理器,实现快速、确定性的推理加速。与Vera Rubin NVL72 集成,Rubin GPU 和 LPU 通过联合计算每个输出标记的 AI 模型每一层,显著提升解码速度。
LPX采用全液冷设计,基于MGX基础设施构建,可无缝集成到将于今年下半年推出的下一代Vera Rubin AI工厂中。
重塑网络与AI 原生存储架构
在网络连接与集群扩展方面,英伟达展示了全新一代的Kyber机架,这是一款专为Rubin Ultra 运算节点设计的系统。有别于传统的水平插拔,Kyber 采用垂直插入设计,通过背板的中板(Midplane)连接,成功在单一NVLink 网域内连接多达144 个GPU,突破了传统铜缆连接的距离限制。
同时,英伟达也与台积电合作,独家量产名为COUPE的革命性共同封装光学(CPO)技术,并应用于全球首款CPO Spectrum-X 交换器中,让光学信号直接与芯片对接。
英伟达重新设计了整个存储系统:BlueField - 4 STX 存储机架。可将 GPU 内存无缝扩展到整个 POD(物理数据中心)。STX 由 BlueField-4 提供支持,BlueField-4 结合了Vera CPU和ConnectX-9 SuperNIC,可提供高带宽共享层,该层针对存储和检索大型语言模型和智能 AI 工作流生成的海量键值缓存数据进行了优化。
太空计算也来了

在GTC大会上,老黄还发布了NVIDIA Space-1 Vera Rubin模块,标志着英伟达正式推出太空计算服务。与NVIDIA H100 GPU相比,该模块上的Rubin GPU可为基于太空的推理提供高达25倍的AI计算能力,从而为ODC(分布式计算中心)、高级地理空间智能处理和自主太空操作提供下一代计算能力。
根据英伟达官方新闻稿,Vera Rubin 空间模块专为在太空直接运行 LLM 和高级基础模型的轨道数据中心而设计,它采用紧密集成的CPU-GPU 架构和高带宽互连,旨在实时处理来自太空仪器的大量数据流。
黄仁勋说到:“太空计算,这片最后的疆域,已经到来。随着我们部署卫星星座并深入探索太空,智能必须存在于数据产生的任何地方。”

这场发布会还展示了完整的芯片路线图。“每年一个全新架构,”黄仁勋总结道,“这就是英伟达的速度。”
02 1万亿美元:英伟达看到的需求
“5000亿美元。”这是去年GTC大会上,黄仁勋公布的英伟达看到的高置信度需求和采购订单。
当时他认为这个数字已经非常惊人。“但现在,一年过去了,就在我现在站的位置,我看到了至少1万亿美元的需求,覆盖到2027年。”
为什么需求会这么大?“因为推理的转折点已经到来。”黄仁勋在演讲中详细解释了原因。
过去两年发生了什么?“三件事情。”黄仁勋回顾道。第一,ChatGPT开启了生成AI时代。“它不只是理解和感知,还能翻译和生成独特的内容。”第二,推理AI(o1/o3)出现了。 “它能反思,能思考,能规划,能把一个无法理解的问题分解成能理解的步骤。这让ChatGPT真正起飞了。”第三,claude code出现了:第一个代理式模型。“它能读文件、写代码、编译、测试、评估、迭代。claude code彻底改变了软件工程。”
黄仁勋说了一个关键数据:"过去两年,AI的计算需求增加了大约1万倍。AI现在必须思考。为了思考、为了执行、为了阅读,它都必须推理。每一次交互,它都在推理。过去的训练时代已经过去了。现在是推理的时代。”这就是1万亿美元需求的来源。每一个公司都在建设AI工厂,每一个工厂都需要Token生产。
Token是新的商品
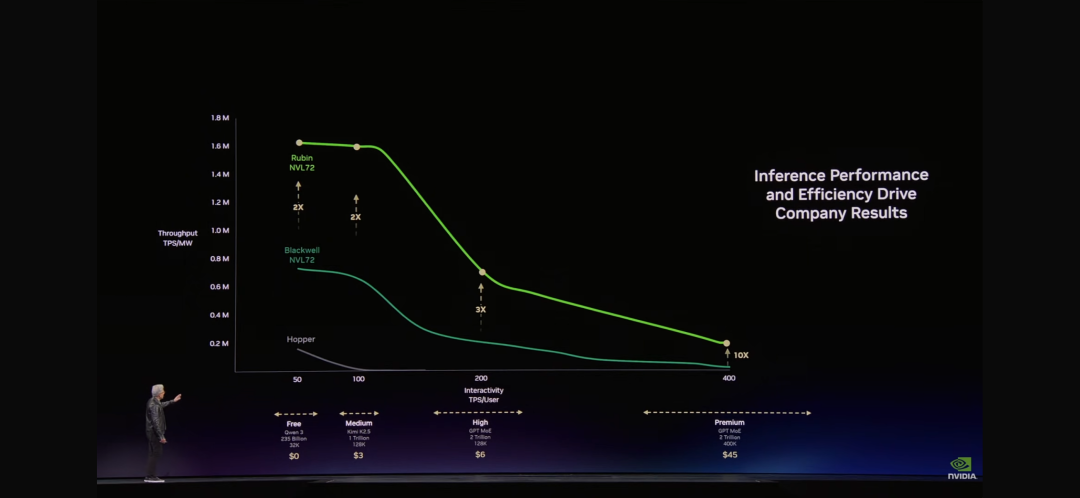
“Token是新的商品。”当黄仁勋在GTC 2026上说出这句话时,整个AI行业的商业模式正在被重新定义。在黄仁勋展示的那张“最重要的图表”上,横轴是Token速率,纵轴是吞吐量。这张图表将决定未来每一个CEO的决策——因为它直接关系到AI工厂的营收。
黄仁勋详细解释了AI工厂的商业模式,其中提到了Token的分层定价:
免费层:高吞吐量、低速度——用于吸引用户 第一层:中等速度——$3/百万Token 第二层:高速度、长上下文——$45/百万Token premium层:超高速度——$150/百万Token
“就像任何行业一样,"黄仁勋解释道,"更高的质量,更高的性能,更低的容量。Grace Blackwell在你的免费层提升了巨大吞吐量,但在你最能变现的层级,它提升了35倍。Vera Rubin又在这个基础上提升了10倍。
“假设你用25%的电力在免费层,25%在中等层,25%在高层层,25%在premium层。你的数据中心只有1吉瓦。你需要决定如何分配。”黄仁勋算了一笔账:免费层吸引用户,premium层服务最有价值的客户。这种组合,按照这张图表计算——Blackwell可以产生5倍的营收,Vera Rubin又是5倍。
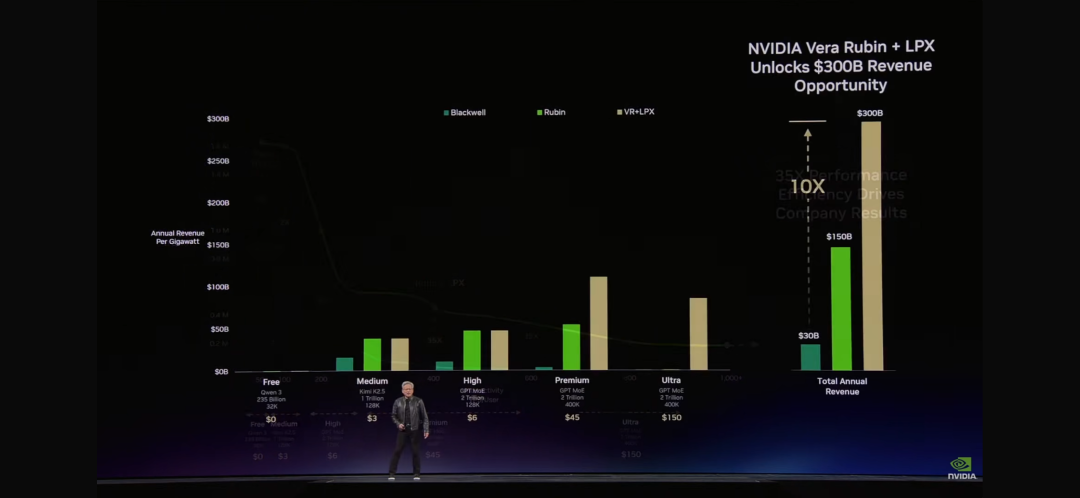
"你应该在Vera Rubin上尽快行动,"黄仁勋建议道,"因为你的Token成本会下降,吞吐量会上升。"
"在两年时间内,在一个1吉瓦的工厂中,使用我之前展示的数学,摩尔定律只能给我们带来几个步骤的提升。但有了这个架构,我们的Token生成速率将从2200万提升到7亿——提升350倍。"这就是“极致协同设计”的力量。黄仁勋称之为“垂直整合然后水平开放”的策略。
03 黄仁勋夸赞龙虾
"OpenClaw是人类历史上最受欢迎的开源项目。它在几周内就做到了Linux 30年才做到的事。"
当黄仁勋宣布英伟达支持OpenClaw时,全场再次沸腾。OpenClaw是一个Agentic系统(代理式系统)的操作系统。它连接大型语言模型,管理资源,访问工具和文件系统,执行调度,创建子代理,这些能力让它几乎就是一个完整的操作系统。
“在OpenClaw出现之前,个人电脑因为Windows而成为可能,“黄仁勋说道,”现在,OpenClaw让创建个人Agent成为可能。其含义是深远的。”
Agentic系统可以访问敏感信息、执行代码、与外部通信,这带来了巨大的安全挑战。英伟达推出了NemoClaw,使用NVIDIA Agent Toolkit软件,只需一条命令即可优化 OpenClaw。它安装OpenShell,提供开放模型和隔离的沙箱,为自主代理增加数据隐私和安全保障。
04 结语
从一块GPU到一座AI工厂,黄仁勋用十年时间完成了英伟达的进化。GTC 2026的大幕已经拉开。看完这场发布会,你最关心的问题是什么?
你觉得英伟达的下一个十年会被"神化"还是"拉下神坛"?
评论区聊聊。
此内容为平台原创,著作权归平台所有。未经允许不得转载,如需转载请联系平台。



联系电话:
010-61853490
新闻投稿:
server@icviews.cn
商务合作:
business@icviews.cn
问题反馈:
19800315212(微信同号)


半导纵横公众号

半导纵横小程序