长江存储新论文,3D NAND闪存技术的演进趋势与挑战
近日,长江存储霍宗亮、夏志良、陈南翔在中国科学发布题为《3D NAND 闪存技术的演进趋势与挑战》的论文。二维闪存技术自问世以来经历了三十余年的迭代发展,制程尺寸持续微缩,存储单元间的串扰问题日益严重,产品可靠性面临严峻挑战。为突破二维闪存的物理微缩极限,三维闪存 (3D NAND) 技术应运而生, 开启了NAND闪存发展的全新纪元。该技术通过从平面结构向三维结构的转变,实现了存储密度的革命性提升,使制造工艺从以光刻为主导的平面缩微技术,转向以刻蚀为核心的三维集成技术。
3D NAND闪存架构的挑战与演进
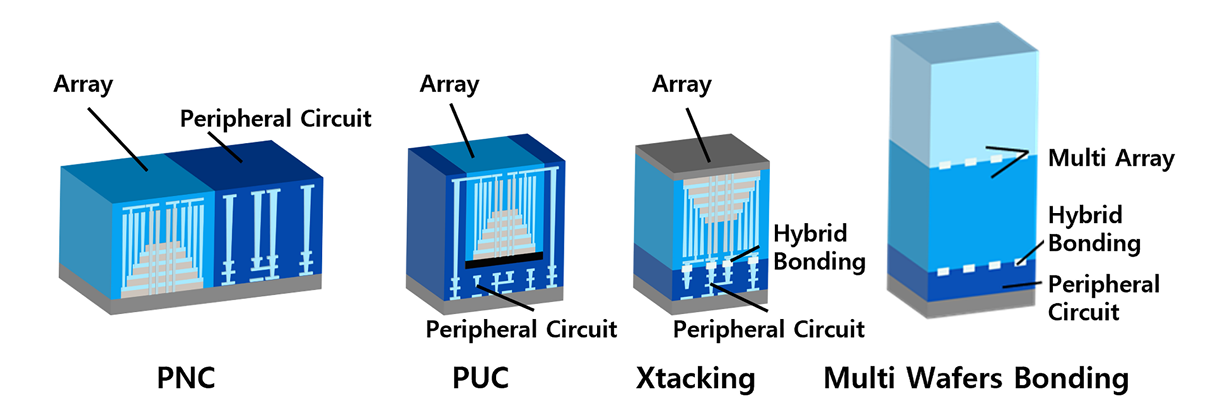
3D NAND 闪存的三维堆叠相当于将2D NAND闪存结构垂直竖起后轴心旋转360度,形成了环形栅极存储单元阵列。其核心挑战在于如何高密度地集成存储阵列与外围电路,并克服由此带来的制造复杂性及可靠性问题。
针对这些挑战,长江存储提出的晶栈架构实现了存储阵列和外围电路独立优化,带来了存储密度和性能的大幅提升,驱动了架构的持续演进。晶栈1.0实现了存储阵列与外围电路的异质集成,晶栈2.0实现了双堆栈架构,晶栈3.0首创了晶背信号与电源引出架构,晶栈4.0实现了无台阶自对准字线形成与引出架构。
3D NAND 闪存架构演变
2018年,长江存储提出了晶栈架构,其核心理念在于将存储阵列与外围电路分离在两片晶圆上并行制备、独立优化,这种分合设计为各自的制造工艺提供了更大的灵活性,实现了更宽的热预算窗口以及优异的器件兼容性,基于此架构实现了64层3D NAND闪存的大规模量产,成功突破了业界的专利壁垒,为3D NAND闪 存持续演进奠定了基础。
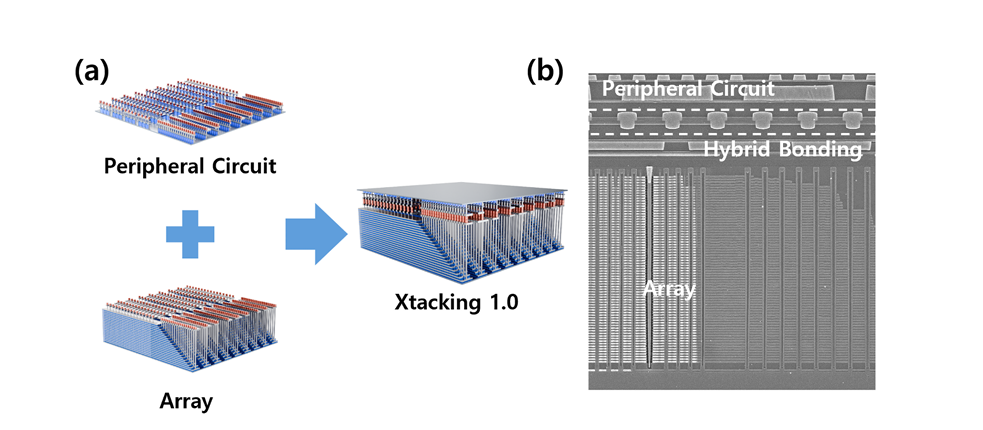
晶栈1.0 (a) 架构示意图; (b) 产品截面图
晶栈1.0 的核心工艺包括原子级晶圆平整技术、高精度光刻对准技术以及百亿级铜通孔的精准互连技术。该技术需严格控制晶圆表面平整度,以最小化键合界面空隙,防止键合过程中的电气失效。通过定制化设计规则和辅助图案,实现了优异的全局至局域平面均匀性。
当阵列堆叠层数突破100层后,单次沟道孔刻蚀遇到工艺挑战,晶栈2.0引入了双堆栈架构,利用纳米级光刻对准工艺,显著降低了单次沟道孔刻蚀的工艺难度,在刻蚀设备受限的条件下,延续了高密度阵列堆叠向更高层数发展的趋势。此外为提升外围电路的信号传输速度,晶栈2.0应用了镍硅化物工艺实现外围电路晶体管源/漏极接触,大幅降低了接触电阻,从而显著改善了3D NAND闪存性能。
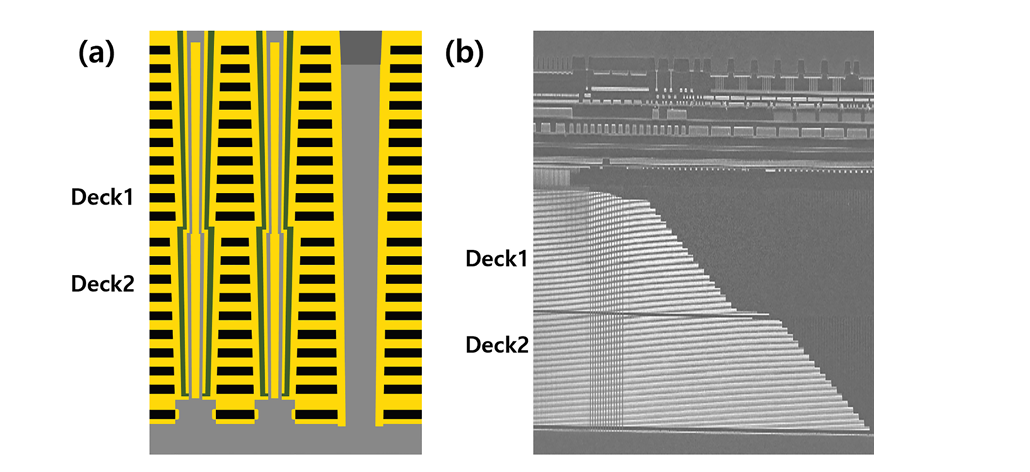
晶栈2.0 (a) 架构示意图; (b) 产品截面图
长江存储晶栈3.0架构,实现了晶背信号与电源引出方案(backsidesourceconnect, BSSC)。将阵列底部高深宽比复杂三维工艺转为二维平面工艺,开创了晶背信号与电源引出的新方法,从根本上攻克了源极引出的技术瓶颈,绕过了高深宽比深孔或深槽刻蚀工艺,有效解决了多排沟道孔及高层数堆叠结构中的源极引出难题。
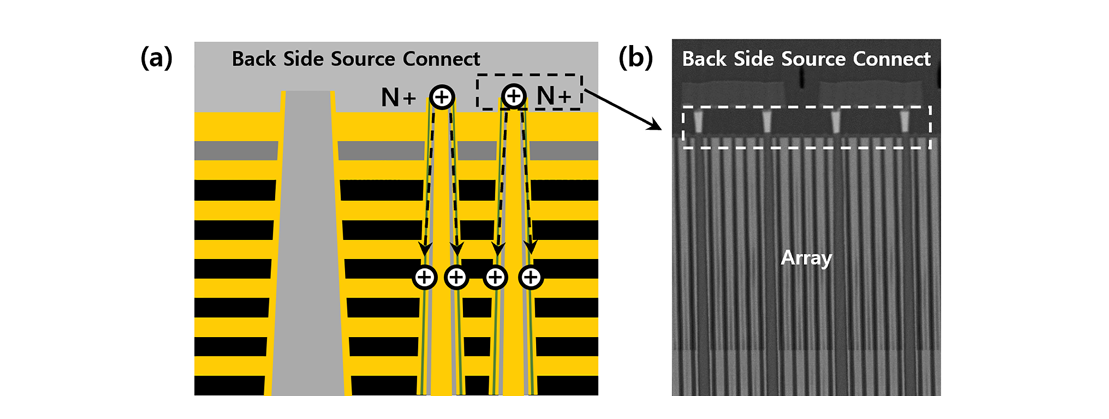
晶栈3.0(a) 架构示意图; (b) 产品截面图
晶栈4.0创新性地开发了一种将台阶、支撑孔和接触孔合而为一的新架构:无台阶自对准字线形成与引出架构,该架构采用自对准字线技术与循环精准刻蚀自停止工艺,实现了高精度的逐层字线引出。晶栈4.0通过浅、中、深孔的光刻与刻蚀组合,结合数值编码设计,将传统台阶制造与金属接触孔刻蚀一步集成,成功克服了传统接触孔刻蚀的工艺挑战。在此创新架构中,字线驱动电路位于金属接触孔的正对面,显著降低了金属互连的复杂度,并缩减了字线驱动电路所需的面积。
随着3D NAND闪存堆叠层数的持续增加,晶栈4.0架构展现了优异的工艺延展性。通过进一步优化架构与工艺,有望实现多层字线的同步引出,从而进一步缩小台阶区域面积,为更高层数的3D NAND 闪存的结构设计铺平道路。
3D NAND闪存微缩的挑战和解决方案
晶栈架构从1.0到4.0的迭代演进,在存储密度、接口速度、工艺优化、可靠性、成本控制以及系 统级定制化等方面展现出显著优势。展望未来,3D NAND闪存技术将持续遵循微缩规则,并融合新架构、新工艺、新材料,向高密度、高性能和高可靠性的方向演进。
高密度3D NAND闪存
三维尺寸微缩(X/Y/Z 三个维度) 对于3D NAND闪存至关重要, 它能够有效减小存储区块尺寸、提升单位面积存储密度并降低单位比特成本。
其中,X维度微缩主要通过缩小沟道孔的关键尺寸和横向间距实现。此外,将台阶区域移至存储阵列中心的设计,显著降低了台阶区的面积占比,并简化了后端互连绕线的复杂度。Y维度微缩涉及多个关键尺寸的减小,沟道孔的关键尺寸和孔间距;栅极分割槽的关键尺寸和沟道孔到栅极分割槽的间距;单个存储块内栅极分割槽的数量。Z 维度(垂直方向) 堆叠层数的增加是提升单位面积存储容量的主要路径,不过增加垂直堆叠层数需兼顾沟道孔刻蚀能力与器件性能。
近期,工艺研究者在成熟刻蚀体系基础上,创新性地引入了氟化氢刻蚀气体, 成功实现单次刻蚀深度达10µm的沟道孔,为3D NAND闪存在Z维度增加堆叠层数奠定了工艺基础。通过持续减薄栅极层和氧化物层的厚度,可在降低单次沟道孔刻蚀难度的同时,显著提升单位面积存储容量并降低单位比特成本。然而,Z维度的微缩仍面临字线间漏电以及存储器件可靠性下降的风险。除上述Z维度的拓展路径外,还可以采用更多堆栈架构,如三堆栈、四堆栈甚至五堆栈,实现存储密度的提升。这种多堆栈架构能够有效降低超高层数3D NAND闪存中沟道孔刻蚀的高深宽比难度,显著改善刻蚀工艺窗口,成为全球技术发展主流方向。
除架构优化与物理尺寸微缩外,改变存储单元本身的属性, 即实现多值存储同样也是关键途径。技术演进方面包括: (1) 经过持续迭代, 3D NAND 闪存已成功实现4比特/单元(quad-level cell,QLC) 技术, 相比 TLC, QLC 理论上可将单位面积存储密度提升约33%;(2) 超越QLC的存储单元技术,可通过调控电荷捕获层的缺陷能级(例如,在SixNy 层中插入高带隙材料,如AlxNy 或h-BN)实现更多能级分离,从而实现5比特/单元(penta-level cell,PLC) 存储,这种设计不仅有助于改善编程性能,相比 TLC 和 QLC,更能显著提升存储密度和容量;(3) 沟道孔分割技术通过将单个存储单元灵活扩展为多个存储单元,显著提升了单位面积的存储密度,但该技术仍面临位线间距急剧缩小带来的工艺挑战以及器件可靠性问题,需要引入新的维度以进一步提升存储密度。
高性能3D NAND闪存
低电阻金属栅极,当堆叠层数增至300层时,金属钨字线方案已难以满足高频操作下的低电阻要求。此时,研究者转向采用金属钼(Mo)或金属钌(Ru)作为栅极的替代材料。相较于钨,钼和钌在同等减薄条件下具有更低的电阻率,这主要得益于其自由电子更长的平均自由程。此外,钼和钌的沉积工艺不含氟元素,因此无需TiN阻挡层,这进一步降低了金属栅极的整体电阻。
新型沟道材料,研究者开发了微波辅助金属诱导横向结晶(microwave-assisted metal induced lateral crystallization,MA-MILC) 技术。该技术成功实现了155层堆叠、高度达6.5µm的单晶硅沟道器件的制备,其核心机制在 于利用NiSi相变过程显著降低单晶硅成核势垒,从而实现单晶硅沟道的连续生长。新材料的探索与应用已延伸至器件的多个层面,不仅涵盖电荷捕获层与沟道材料,还包括字线材料、阻挡层材料以及牺牲层材料等。铟镓锌氧化物(IGZO) 凭借其独特的材料特性,宽带隙、高载流子迁移率以及可实现垂直单晶生长的能力,被视为替代多晶硅沟道的理想候选材料。不过,IGZO材料也面临显著挑战,其空穴迁移率极低,导致基于栅致漏极泄漏效应的擦除机制难以在IGZO沟道3D NAND闪存中实现,尽管研究者尝试在IGZO沟道外侧引入P型多晶硅层以提供擦除所需的空穴,但这种方案不可避免地增大了沟道孔尺寸,从而降低了存储密度。
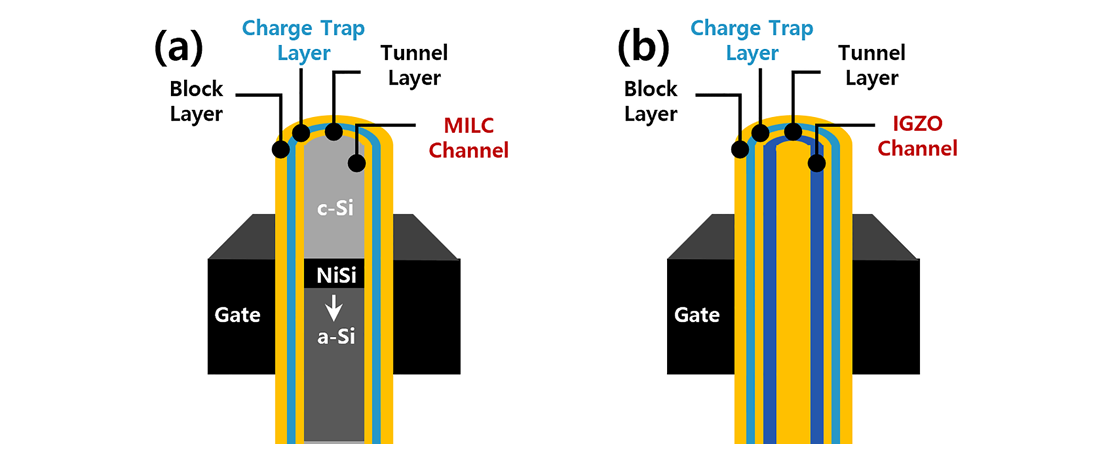
存储单元沟道创新方案 (a) MILC 方案; (b) IGZO 方案
高可靠性3D NAND闪存
存储单元栅介质材料,电荷捕获型3D NAND闪存器件由金属栅极、高介电常数(high-k) 介质、阻挡层、电荷捕获层、 隧穿层、沟道及氧化物填充层组成。论文提到,除了传统材料以外,研究者也在寻找新型材料,如铪基铁电材料,其介电常数远高于传统氧化硅,可在保障同等绝缘效果的前提下进一步缩减介质层厚度。
分离型电荷存储工程,随着3D NAND闪存堆叠层数的快速增加以及金属栅极间距的持续微缩,存储单元间的串扰加剧,横向电荷损失(lateral charge loss) 问题也日益凸显。为抑制横向电荷损失,研究者提出了纵向物理分割电荷捕获层的方案,形成分离式电荷存储单元。该设计虽有效减少了横向电荷损失,但同时也带来了沟道电流密度下降和步进脉冲编程(incrementalsteppulse programming,ISPP) 斜率降低的问题。此外,为减轻相邻存储单元间的串扰,研究者引入了字线层间空气介质层(airgap)技术。该技术能有效降低延迟并改善编程与读操作中的串扰。然而,空气介质的引入也带来工艺挑战,如边缘电场增强(edgefield enhancement) 和高介电常数材料侧壁刻蚀等不可控效应,可能加剧擦除饱和现象。

互连金属桥结构 (a) 结构示意图; (b) 产品截面图
结构应力优化工程,在3D NAND 闪存制造中,除存储器件本身的可靠性优化外,晶圆所承受的宏观应力对芯片的机械应力及可靠性具有决定性影响。应力管理策略主要有两个方面:一是宏观层面,可通过优化工艺设备或在晶圆背面沉积具有补偿应力的薄膜等手段进行有效控制;二是微观层面,应力集中问题尤为突出,可能在存储块内部薄膜中形成脆弱点,成为潜在的漏电通道,严重损害芯片良率和器件可靠性。基于材料与工艺集成的思路,通过优化全局应力预算、调控各薄膜层的应力分布以及精确管理热处理工艺窗口,可实现局部应力的平衡与抵消。
3D NAND闪存的未来展望
随着生成式AI驱动的大数据革命兴起,新兴市场对3D NAND闪存提出了超高数据传输带宽的需求。高带宽闪存(highbandwidth flash, HBF) 可使图形处理器 (GPU) 能够快速访问海量存储于3D NAND闪存中的数据,有效弥补高带宽内存(highbandwidthmemory, HBM)容量相对有限的不足,成为未来大模型存储主流载体,从而加速人工智能训练与推理的发展。
HBF由多层堆叠的3D NAND闪存构成, 通过硅通孔(through silicon via, TSV) 和微凸点 (micro bump) 或混合键合 (hybrid bonding) 技术将各层信号传输至中介层,实现与高算力芯片的2.5D互连架构。依托晶栈架构在混合键合技术领域积累的深厚技术沉淀与成熟量产经验,传统微凸点HBF向混合键合HBF的技术转换得以加速推进。凭借混合键合技术在工艺可扩展性与架构设计自由度等方面的独特优势,且能够进一步突破散热效率、互连密度及集成度等核心性能瓶颈,该技术将加速HBF与高算力芯片3D高速互连架构的开发进程,助力研制出更具市场竞争力的芯片产品。
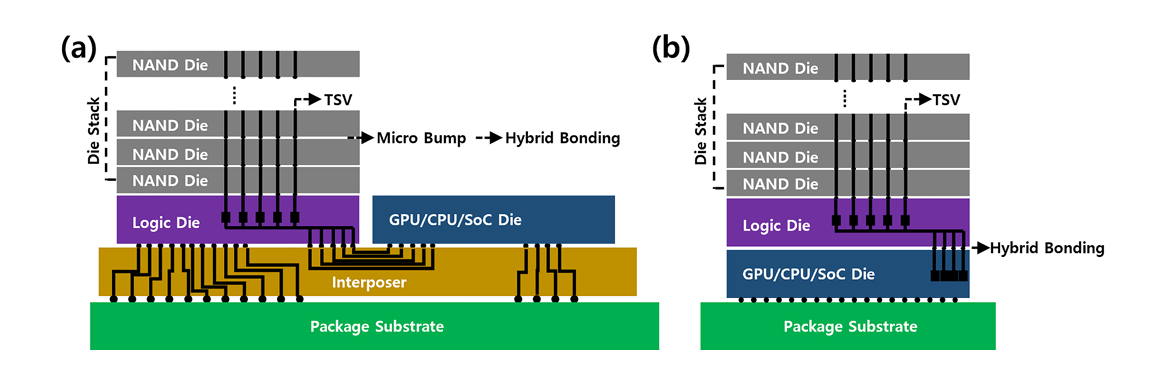
基于高带宽闪存架构的高性能计算芯片架构示意图 (a) 2.5D 架构; (b) 3D 架构
晶栈架构为先进半导体技术的后续迭代研发与产业化落地进程,筑牢了坚实的技术根基,同时提供了可靠的工程化保障。
本文转自媒体报道或网络平台,系作者个人立场或观点。我方转载仅为分享,不代表我方赞成或认同。若来源标注错误或侵犯了您的合法权益,请及时联系客服,我们作为中立的平台服务者将及时更正、删除或依法处理。


联系电话:
010-61853490
新闻投稿:
server@icviews.cn
商务合作:
business@icviews.cn
问题反馈:
19800315212(微信同号)


半导纵横公众号

半导纵横小程序