光合这场大会,划了哪些重点?
2025年12月17-19日,光合组织2025人工智能创新大会(HAIC 2025)在江苏昆山正式召开。本次大会汇聚了中国科学院院士、IDC等权威智库专家,以及浪潮信息、中科曙光、商汤科技、麒麟软件等光合组织核心成员单位。

深入探讨了从底层芯片、智算集群到上层大模型应用的全栈国产化路径,并集中发布了多项突破性技术成果与生态战略。关于海光战略、万卡集群、行业落地等,半导体产业纵横观察到以下亮点:
亮点一:关于海光战略
在核心芯片层面,海光信息总裁沙超群带来“双芯”战略发布,即通过“海光CPU+海光DCU”异构协同,为数字中国提供核心计算引擎。
针对当前AI算力市场存在的生态碎片化与技术壁垒问题,海光依托HSL总线互联协议、共建AI软件栈体系等两大举措,将逐步构建起“向上生长联生态、向下扎根筑根基”的AI计算开放架构。

作为这一战略的落地载体, “AI计算开放架构联合实验室”首批项目组协同创新计划正式启动,破解当前AI计算产业的核心痛点,将重点围绕 系统高速互联总线、统一基础软件栈、AI服务器设计规范 等行业共性需求,开展协同研发,以解决国产智算服务器“适配难”、缺少统一类CUDA基础软件栈、异构算力间兼容性不足、系统协同效率低等问题。。
亮点二:关于万卡集群

面对万亿参数大模型训练对算力基础设施提出的严苛要求,中科曙光在会上正式发布了“ScaleX万卡超集群”。曙光高级副总裁李斌详细解析了该集群的技术架构,指出传统集群受限于通信瓶颈与能效问题,已难以满足当前大模型激烈竞争的需求。
此次发布的ScaleX集群基于全球首个单机柜640卡全互联的超节点(ScaleX640)构建。该节点采用正交架构实现柜内全电互联,单机柜支持860kW的供电与冷却能力,实现了高达20倍的算力密度提升,PUE值低至1.04,在冷却、供电及硬件架构上已达到甚至部分超越了国际主流技术路线2027年的规划水平。
通过线性扩展,该集群规模可达10,240张卡,提供超过5 EFLOPS的算力,并实现了训练性能提升30%、推理吞吐提升40%的系统级优化,有效缓解了国产高端算力紧缺的现状。
为了解决大规模集群中的网络瓶颈,曙光还同步发布了国内首款400G原生RDMA网卡芯片和交换芯片——Scale Fabric。该芯片支持超10万卡的单子网扩展,在带宽和延时上对标国际InfiniBand标准,同时组网成本降低约30%。配合存储领域的“超级隧道”与“AI数据工厂”技术,曙光构建了从算力、网络到存储的紧耦合系统,实现MOE大模型训练效率与高通量推理吞吐性能大幅提升30-40%;。
亮点三:关于行业落地
软件生态的成熟度直接决定了算力的可用性。麒麟软件在会上展示了银河麒麟操作系统在AI时代的全新演进。通过构建“应用与模型解耦、模型与AI芯片解耦”的原生AI智能架构,银河麒麟操作系统实现了对海光、英伟达等多种异构算力的统一支持与开放适配。此外,系统还集成了AI可观测性与增强安全功能,包括大模型防护栏与恶意软件检测,为数据中心提供安全底座。
亮点四:关于应用前沿

大会还展示了AI在科学探索与物理世界交互方面的最新成果。中国科学院院士周成虎发布了全球首个地理科学大模型——“坤元”(SigmaGeography)。该模型集成了语义基座、地图自动生成及地理检索技术,被誉为“人工智能地理学家”,能够为地球复杂系统问题提供智能决策支持。
商汤科技则展示了“开悟世界模型3.0”(Kairos 3.0),其具备因果思维链理解、长时动态交互及万千可能性预测三大核心能力,为具身智能机器人的规模化应用提供了“超级大脑”。
智能算力迎来爆发式增长周期
今日,IDC中国区副总裁兼首席分析师武连峰在大会上,对未来智能经济的发展趋势进行了量化解读。IDC数据显示,全球在人工智能技术上的支出未来5年累计将超过5万亿美元,其中中国未来5年的总支出预计达到5000亿美元,未来五年被视为中国智能经济发展的“黄金时期”。
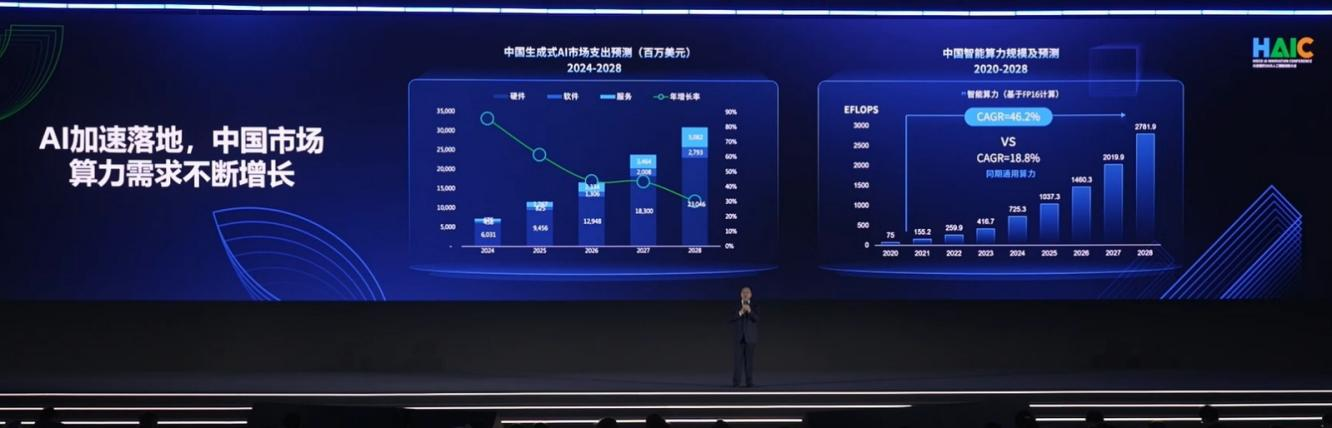
随着大模型技术与应用的持续演进,算力需求呈现出显著的结构性变化。IDC预测,2024年至2028年,中国智能算力规模(基于FP16计算)的复合年增长率(CAGR)将高达46.2%,远超同期通用算力18.8%的增速。中国“十五五”规划建议中已明确提出从新型基础设施建设、产业集群建设、技术自主与核心组件国产化等7个方面促进数智化发展,这为国产算力产业提供了明确的政策指引。
此内容为平台原创,著作权归平台所有。未经允许不得转载,如需转载请联系平台。


联系电话:
010-61853490
新闻投稿:
server@icviews.cn
商务合作:
business@icviews.cn
问题反馈:
19800315212(微信同号)


半导纵横公众号

半导纵横小程序