台积电A14,制程详解
台积电在其欧洲OIP论坛上展示的一张幻灯片清晰地阐述了其将于2028年推出的A14(1.4nm级,正面供电)制程工艺相比其前代产品N2(2nm级,正面供电)的优势。结果表明,A14在相同功耗和复杂度下性能提升16%,在相同时钟频率和复杂度下功耗降低27%。然而,为了充分发挥下一代制造技术的潜力,芯片设计人员可能需要使用更智能的电子设计自动化(EDA)工具。

当代工厂发布新的工艺技术时,通常会公布一系列特性,以展现不同代际工艺之间的相对差异。随着生产节点的不断推进,芯片制造商往往会获得更多关于其性能的数据,并随着时间的推移逐步明确其特性。台积电的A14工艺正是如此。此前,该公司表示,与N2工艺相比,在相同的功耗和晶体管数量下,A14工艺的性能将提升10%至15%;在相同的时钟频率和复杂度下,功耗将降低25%至30%;混合芯片的晶体管密度也将提升约20%。而从幻灯片来看,新节点的性能将略高于预期,但功耗方面则保持在预期值的中等水平。
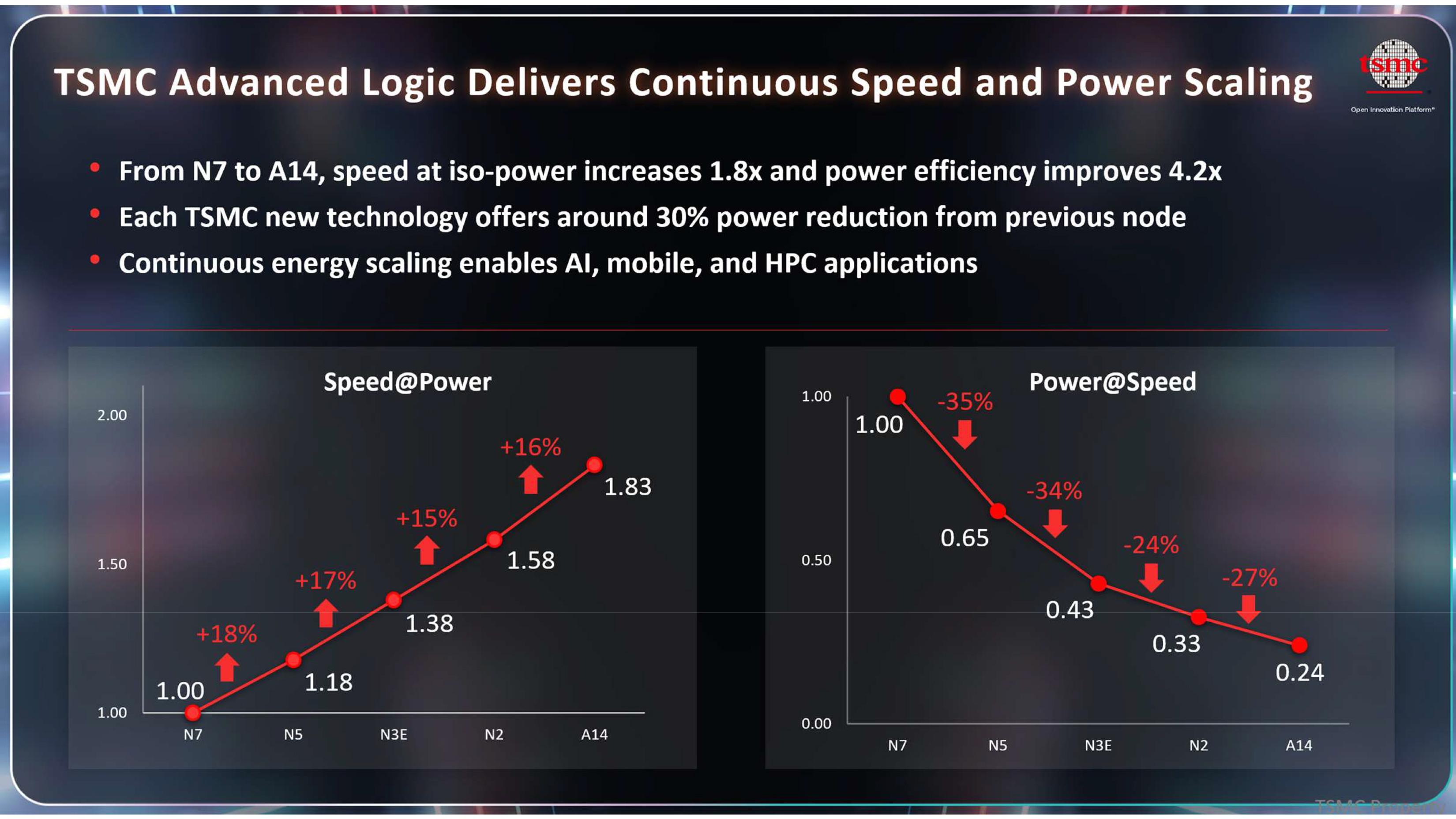
台积电展示这张幻灯片是为了说明其工艺技术的可扩展性,旨在表明尽管摩尔定律增速放缓并面临严峻挑战,但它仍然有效。然而,这张幻灯片仅列出了主要的主流制程节点,而省略了N3B(主要由苹果和英特尔使用)以及N3P和N2P等节点间升级。虽然提及N3X、N2X和A16是合理的,因为这些制程技术针对特定应用,但缺少节点间升级的信息在一定程度上模糊了它们的重要性及其带来的进步,也未能突出多年来取得的显著进展。
根据幻灯片显示,从N7(2018年工艺节点)升级到A14(2028年工艺节点),在相同功耗水平下性能提升1.83倍,能效提升4.2倍,这看起来非常显著。然而,这两项技术之间相隔十年之久。台积电还指出,每一代新的主要工艺节点相比上一代节点都能降低约30%的功耗。相比之下,主要节点的性能提升幅度仅为15%至18%,这在一定程度上表明,台积电在设计这些制造工艺时,更关注的是功耗控制。
有趣的是,除了台积电的制程节点之外,还有其他方法可以提高设计的能效。例如,芯片设计人员可以使用人工智能增强的 Cadence Cerebrus AI Studio 和 Synopsys DSO.ai 等自动化布局布线 (APR) EDA 工具,这些工具利用强化学习技术探索更广泛的优化空间,涵盖各种制造工艺和布局,并自动调整设计参数和布局方案,从而提升性能、降低功耗并缩小面积 (PPA)。
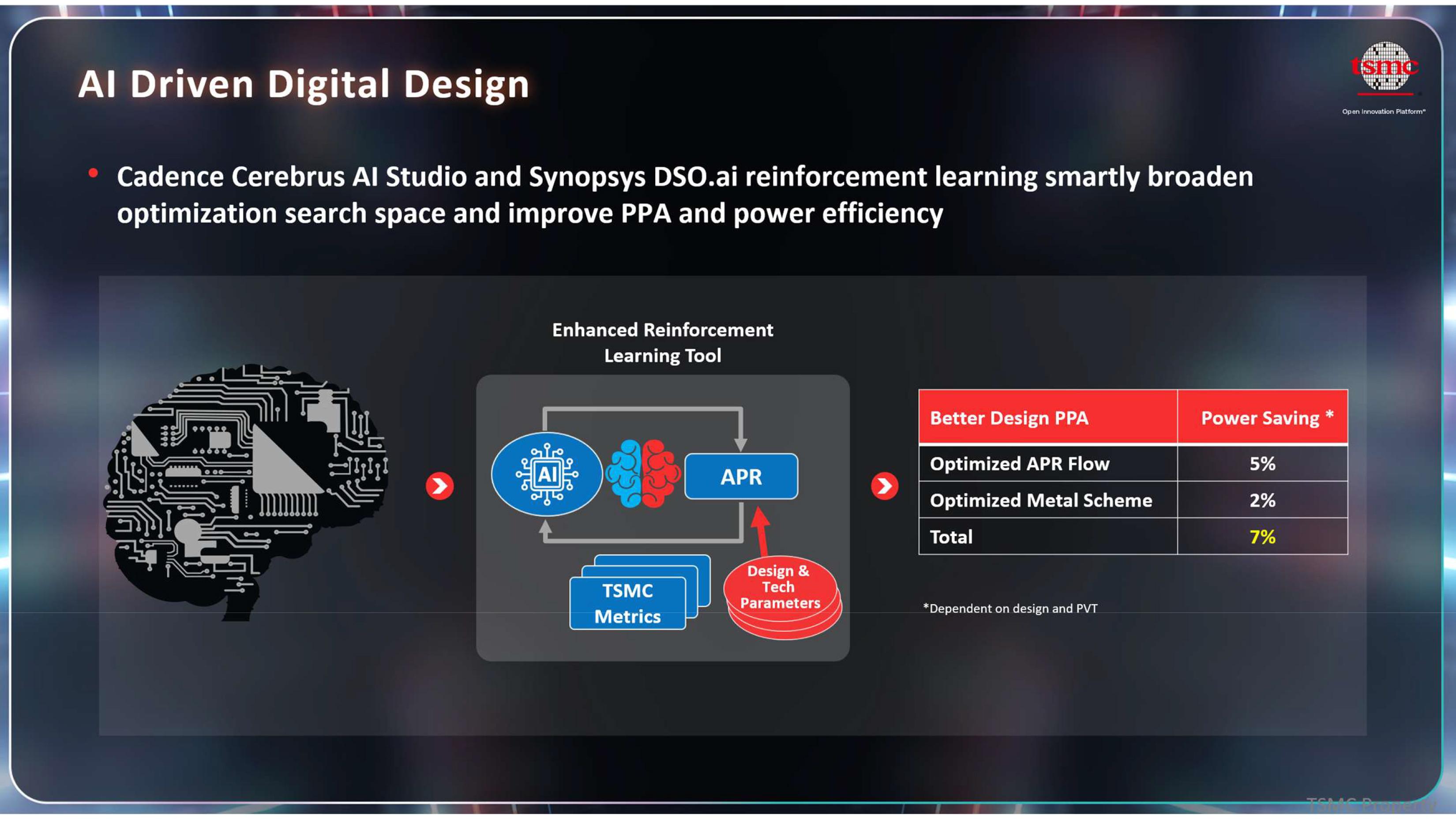
根据幻灯片显示,这种方法通过优化APR流程可节省5%的功耗,通过优化金属层方案可额外提升2%的性能,总功耗节省达7%,与台积电通过节点间优化所能达到的节能效果相当。当然,此类数据仅供参考,因为并非所有设计都能优化到如此程度。不过,不可否认的是,EDA工具(尤其是更智能的APR工具)在利用现代制造技术实现更高性能和更低功耗方面发挥着越来越重要的作用。
据悉,目前 A16 制程的唯一客户为英伟达,台积电高雄 P3 厂将于 2027 年量产,以匹配英伟达的产品规划。业内据此推测,苹果迈入 2 纳米工艺世代后,下一代制程或将跳过 A16,直接升级至 A14。供应链消息显示,台积电扩充 3 纳米产能,正是为承接英伟达 3 纳米制程产品的大额订单。而增建三座 2 纳米晶圆厂的动作,则是对竹科宝山 F20、高雄 F22、台中 F25 以及美国厂 F21 的制程与产能规划进行的同步调整。
从台积电上调资本开支、加速先进制程研发进度、推进产能扩增计划等一系列动作不难看出,其近期针对 3 纳米及以下先进制程的布局蓝图,已根据客户需求完成快速调整。
南科晶圆厂方面,以 N4/N5 制程为主的 F18A 厂,P1、P2、P3、P7 等厂区合计月产能达 16 万片,F15 厂也已加入生产序列;而建设中的 F18A P9 厂则放缓施工进度,其待处理订单将转移至美国亚利桑那州工厂生产。以 N3B 及 N3E 制程为主的 F18B 厂,P4、P5、P6、P8 等厂区合计月产能由 13 万片提升至 16 万片。
值得关注的是,台积电近期已初步规划,在南科周边仍处于土地征收阶段的特定区域,再新建三座 2 纳米晶圆厂。为配合此次产能调配,台积电同步调整了竹科宝山 F20、高雄 F22 及台中 F25 厂区的 2 纳米及以下制程与产能规划。
本文转自媒体报道或网络平台,系作者个人立场或观点。我方转载仅为分享,不代表我方赞成或认同。若来源标注错误或侵犯了您的合法权益,请及时联系客服,我们作为中立的平台服务者将及时更正、删除或依法处理。

联系电话:
010-61853490
新闻投稿:
server@icviews.cn
商务合作:
business@icviews.cn
问题反馈:
19800315212(微信同号)


半导纵横公众号

半导纵横小程序