AWS掷出算力核弹,Trainium3深度解析
亚马逊在年度AWS re:Invent大会上正式发布了Trainium3 (Trn3),并宣布推出Trainium4 (Trn4)。亚马逊在数据中心定制芯片领域拥有最悠久、最广泛的历史。
今天,本文将深入探讨 Trainium3 芯片的飞跃式性能提升,包括微架构、系统和机架架构、扩展性、性能分析器、软件平台以及数据中心加速等。
Amazon Basics GB200
借助 Trainium3,AWS 始终专注于优化总体拥有成本 (TCO) 下的性能。他们的硬件核心理念很简单:以最低的 TCO 实现最快的上市速度。AWS 不拘泥于任何单一的架构设计,而是最大限度地提高运营灵活性。这体现在他们与多家合作伙伴在定制芯片方面的合作,以及对自身供应链的管理,包括从多家组件供应商采购。
在系统和网络方面,AWS 遵循“亚马逊基础架构”理念,以性能与总体拥有成本 (TCO) 为导向进行优化。诸如使用 12.8T、25.6T 还是 51.2T 带宽横向扩展交换机,或者选择液冷还是风冷等设计选择,都只是实现特定客户和数据中心最佳总体拥有成本的手段。
对于横向扩展网络,虽然 Trn2 仅支持 4x4x4 三维环形网格横向扩展拓扑,但 Trainium3 添加了一种独特的交换式架构,该架构与 GB200 NVL36x2 拓扑结构有些类似,但也存在一些关键差异。添加这种交换式架构的原因是,对于前沿的混合专家 (MoE) 模型架构而言,交换式横向扩展拓扑具有更高的绝对性能和更高的总拥有成本 (TCO) 性能。
即使对于这种扩展架构中使用的交换机,AWS 也决定不做决定:在 Trainium3 的生命周期内,他们将采用三种不同的扩展交换机解决方案,首先是 160 通道、20 端口的 PCIe 交换机,以便快速上市,因为目前高通道和端口数的 PCIe 交换机的可用性有限;之后切换到 320 通道 PCIe 交换机;最终切换到更大的 UALink,以实现最佳性能。
亚马逊的软件
在软件方面,AWS 的 North Star 扩展并开放了其软件堆栈,以面向大众,不再仅仅针对内部 Bedrock 工作负载(例如运行 vLLM v1 私有分支的 DeepSeek/Qwen 等)和 Anthropic 的训练和推理工作负载(运行自定义推理引擎和所有自定义 NKI 内核)优化每 TCO 的性能。
事实上,他们正在进行一项大规模、多阶段的软件战略转型。第一阶段是发布并开源一个新的原生 PyTorch 后端。他们还将开源其内核语言“NKI”(神经元内核接口)的编译器,以及内核和通信库 matmul 和 ML ops(类似于 NCCL、cuBLAS、cuDNN 和 Aten Ops)。第二阶段包括开源其 XLA 图编译器和 JAX 软件栈。
通过开源其大部分软件栈,AWS 将有助于扩大 CUDA 的应用范围,并启动一个开放的开发者生态系统。我们认为,CUDA 的护城河并非由建造城堡的英伟达工程师构筑,而是由数百万外部开发者通过为 CUDA 生态系统做出贡献而挖掘的。AWS 已经意识到这一点,并正在推行同样的战略。
Trainium3 最初仅支持逻辑神经元核心 (LNC) = 1 或 LNC = 2。LNC = 1 或 LNC = 2 是亚马逊/Anthropic 的顶级 L337 内核工程师所期望的,但 LNC = 8 才是更广泛的机器学习研究科学家群体在广泛采用 Trainium 之前所更倾向的选择。遗憾的是,AWS 计划在 2026 年年中之前不会支持 LNC = 8。下文将详细阐述 LNC 的概念以及不同模式对于研究科学家采用 Trainium 的重要性。
Trainium3 的上市又开辟了另一个战线,Jensen 现在除了要面对另外两个战场——性能/总拥有成本 (TCO) 极高的 Google TPUv7和性能/总拥有成本 (TCO) 强劲的AMD MI450X UALoE72 (尤其是在 OpenAI 获得“股权返还”后,AMD 最多可持有 10% 的股份)——之外,还必须应对这个战线。
我们仍然相信,只要英伟达继续加快研发步伐,以光速前进,他们就能继续保持行业霸主的地位。詹森需要比过去四个月的速度更快。就像英特尔在CPU领域安于现状,而AMD和ARM等竞争对手却一路领先一样,如果英伟达也安于现状,他们将会更快地失去领先地位。
在本文中,我们将讨论支持可切换式扩展机架的两款 Trainium3 机架 SKU:
- 空冷式 Trainium3 NL32x2 开关机(代号“Teton3 PDS”)
- 液冷式 Trainium3 NL72x2 开关式(代号“Teton3 MAX”)
我们将首先简要回顾Trainium 2架构,并解释Trainium 3引入的变更。文章前半部分将重点介绍各种Trainium 3机架式SKU的规格、芯片设计、机架架构、物料清单(BOM)和功耗预算,然后再探讨其纵向扩展和横向扩展网络架构。文章后半部分将重点讨论Trainium 3微架构,并进一步阐述亚马逊的软件战略。最后,我们将讨论亚马逊和Anthropic的AI数据中心,并结合总体拥有成本(TCO)和每TCO性能分析,总结全文。
Trainium3 服务器类型和规格概述
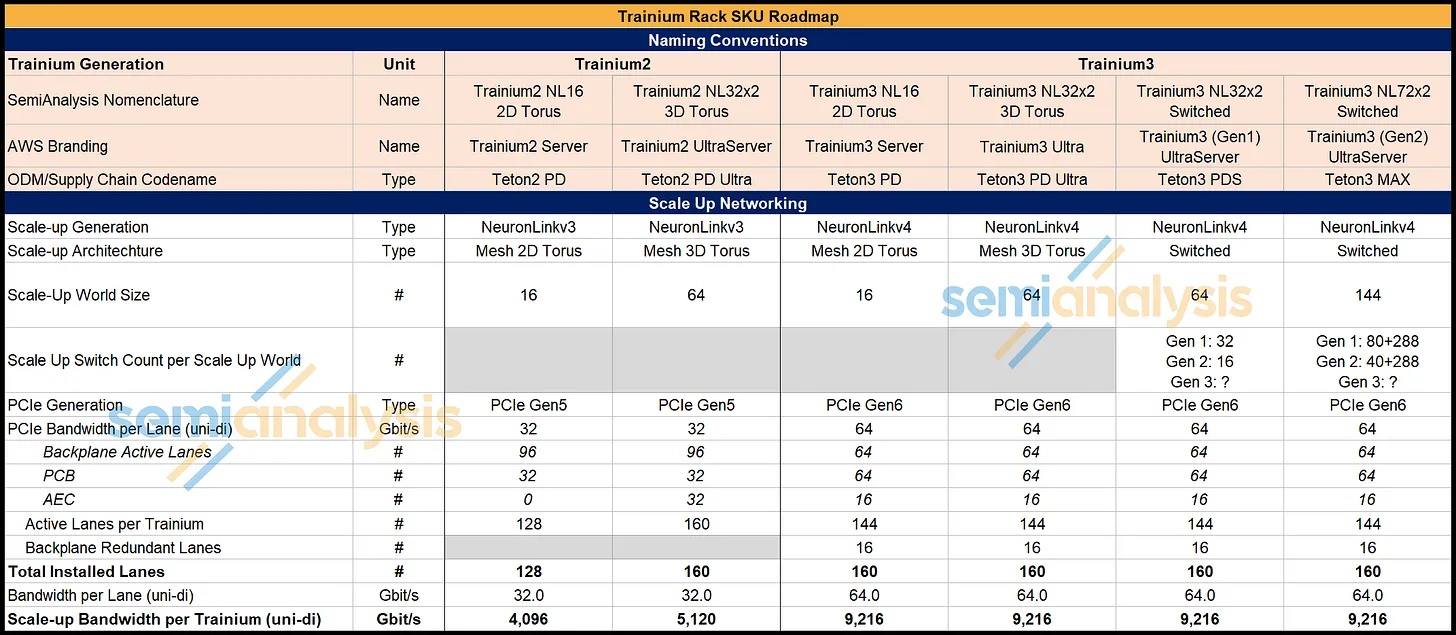
Trainium2 和 Trainium3 之间共有四个不同的服务器 SKU,供应链通常使用它们的代号来指代它们,这与 AWS 的品牌名称不同。
读者可能会发现,要理清各种不同的代际和机架尺寸组合,并在AWS品牌和ODM/供应链使用的代号之间来回切换,实在令人困惑。我们恳请AWS:负责产品营销和命名的人员应该停止使用这些令人费解的名称。理想情况下,他们应该效仿Nvidia和AMD的命名规则,采用产品名称后半部分分别表示扩展技术和GPU数量,例如GB200中的NVL72指的是NVLink,GPU数量为72。
下表旨在为读者提供清晰的解释,帮助他们理解不同群体使用的各种命名规则,避免混淆:
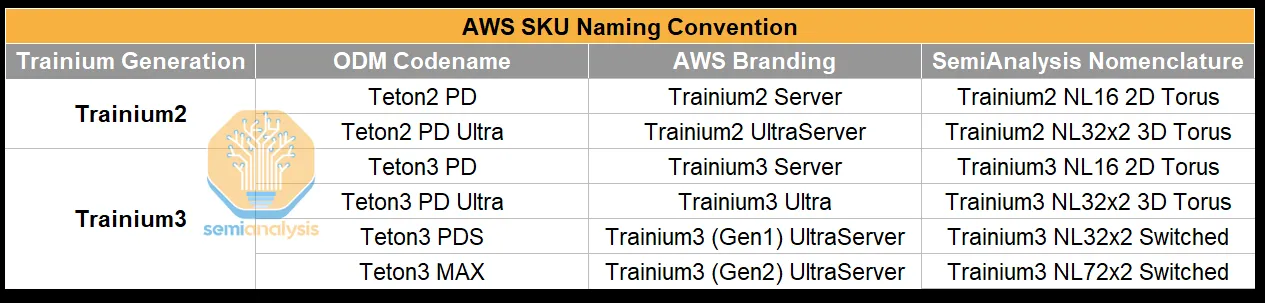
来源:SemiAnalysis、AWS
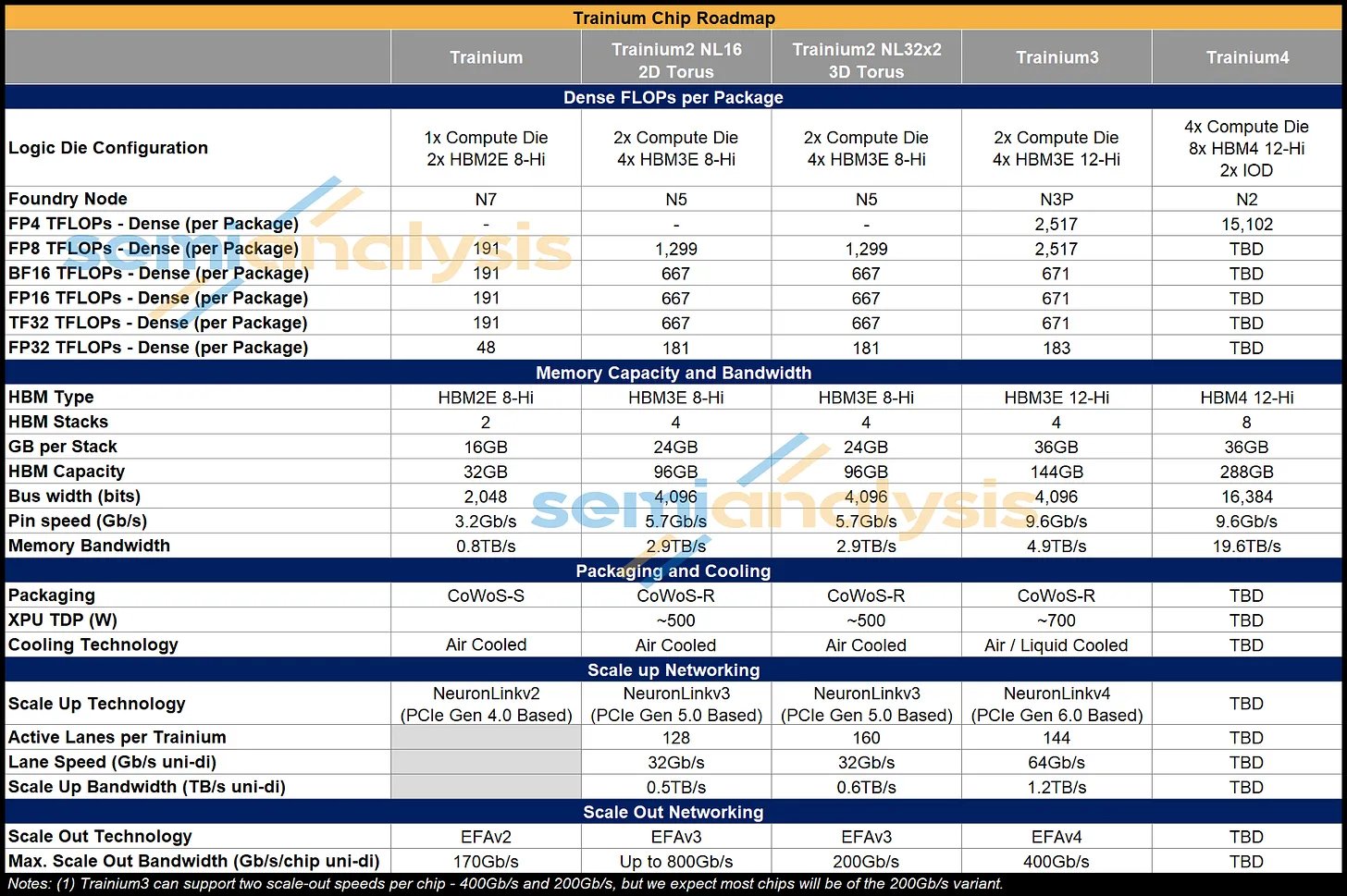
Trainium3 在规格方面实现了几项显著的代际升级。
OCP MXFP8 的 FLOPs 吞吐量翻倍,并且增加了对 OCP MXFP4 的支持,但性能与 OCP MXFP8 相同。有趣的是,对于更高精度的数字格式(例如 FP16 和 FP32),其性能与 Trn2 保持一致。在微架构部分,我们将描述这些权衡的影响。
来源:SemiAnalysis、AWS
Trainium3 的 HBM3E 升级至 12 层,使每个芯片的内存容量达到 144GB。尽管 Trn2 仍然使用 4 层 HBM3E,但 AWS 通过将引脚速度从低于平均水平的 5.7Gbps 提升至 Trn3 的 9.6Gbps,实现了 70% 的内存带宽提升,这是我们迄今为止见过的最高HBM3E引脚速度。
事实上,Trn2 中使用的 5.7Gbps 引脚速度更接近 HBM3 的速度,但由于它使用 24Gb 的芯片,在 8 层堆叠中每个堆叠提供 24GB 的容量,因此仍被归类为 HBM3E。速度不足是由于使用了三星提供的内存,其 HBM3E 的性能明显低于海力士或美光。为了在 Trainium3 中实现更快的速度,AWS 正在切换到海力士和美光的 HBM。
与 Trn2 相比,Trainium3 芯片的扩展带宽翻了一番,这得益于其采用 PCIe Gen 6,每条通道的带宽为 64Gbps(单向),而 PCIe Gen 5 每条通道的带宽为 32Gbps。Trainium3 使用 144 条 PCIe 活动通道进行扩展,这意味着在 Gen6 上,每个 Trainium3 芯片支持 1.2 TB/s(单向)的扩展带宽。
横向扩展带宽支持翻倍至最大 400 Gb/s,但大多数生产的 Trainium3 机架仍将沿用 Trn2 使用的每 XPU 200Gb/s 的横向扩展速度。
对于 Trainium4,亚马逊将使用 8 个 HBM4 堆栈,与 Trainium3 相比,内存带宽提高 4 倍,容量提高 2 倍。
Trainium3 机架架构
从机架解决方案层面来看,AWS 在 re:Invent 大会上发布了 Trainium3 (Gen1) UltraServer 和 Trainium3 (Gen2) UltraServer,分别对应 Trainium3 NL32x2 Switched 和 Trainium3 NL72x2 Switched。Trainium3 NL32x2 Switched 和 Trainium3 NL72x2 Switched 的主要区别在于其横向扩展网络拓扑和机架架构——本节将介绍这两个 SKU 在拓扑和架构上的差异,并讨论每种架构最适合和优化的 AI 工作负载。
我们先来看一下每种服务器类型的物理布局。下表列出了每个机架式 SKU 的主要规格:
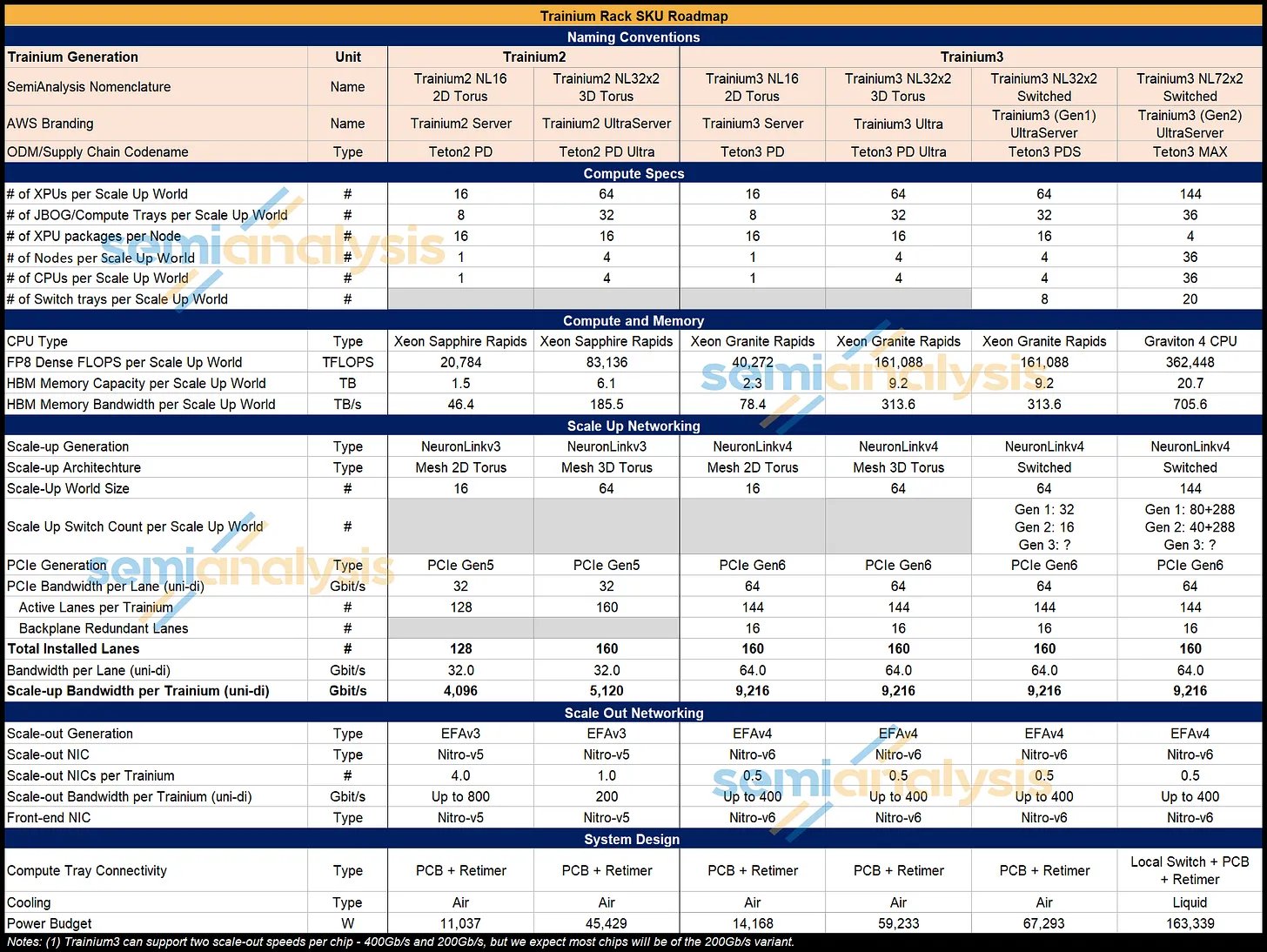
来源:SemiAnalysis、AWS
Trainium2 仅提供前两种机架 SKU 类型——即 Trn2 NL16 2D Torus 服务器和 Trn2 NL32x2 2D Torus 服务器,而 Trainium3 将提供所有四种机架 SKU 类型,其中大部分 Trainium3 将于 2026 年以 Trainium3 NL32x2 交换机 SKU 的形式交付。我们预计,在 Trainium3 的整个生命周期内,大部分 Trainium3 将部署在 Trainium3 NL32x2 交换机 SKU 和 Trainium3 NL72x2 交换机 SKU 中。
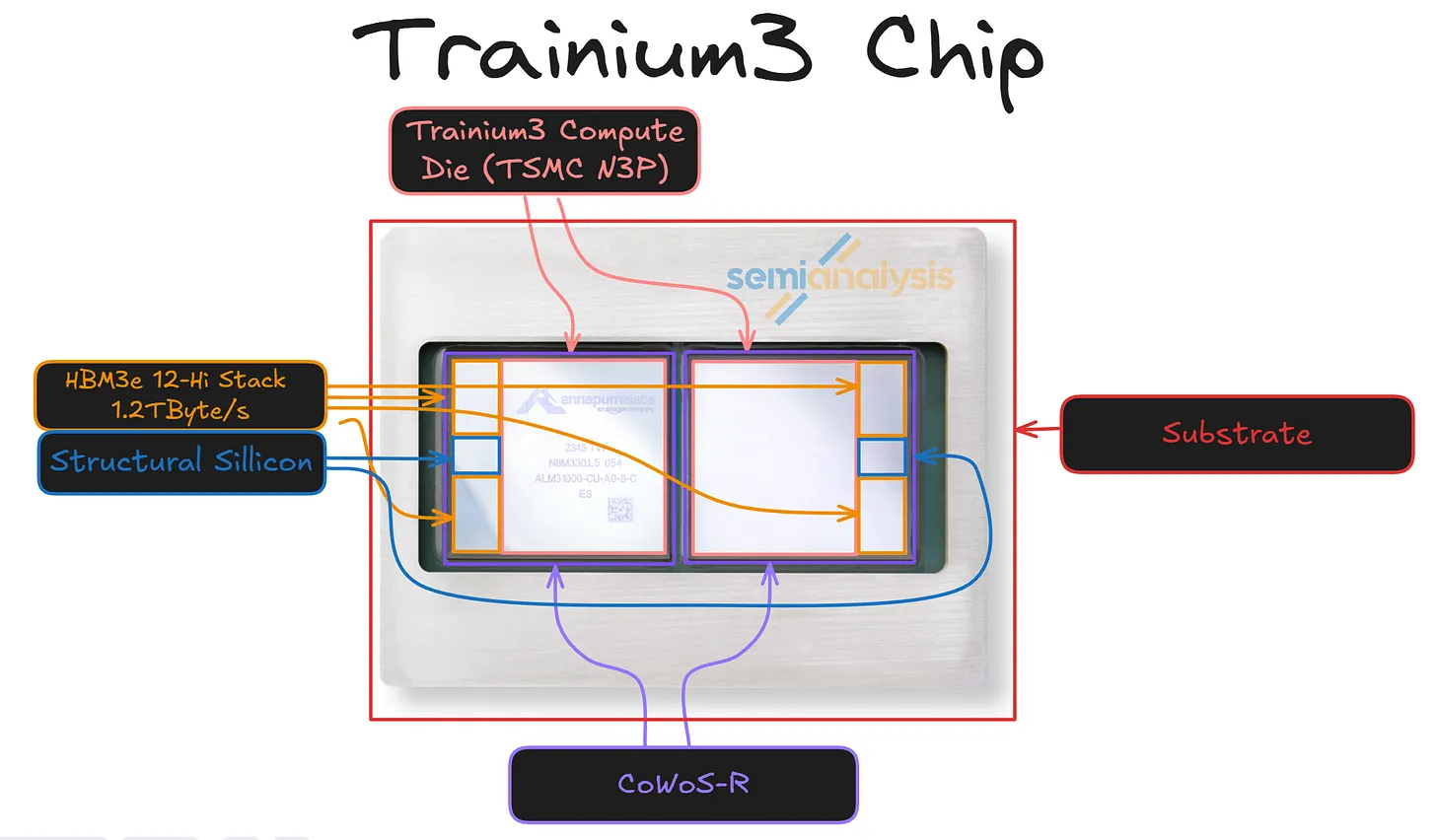
Trainium3 制程和封装
Trainium3 的计算任务将从用于 Trn2 的 N5 节点迁移到 N3P 节点。Trainium3 将成为首批采用 N3P 的服务器之一,其他采用者还包括 Vera Rubin 和 MI450X 的主动中介层芯片 (AID)。N3P 存在一些问题需要解决,这可能会延后项目进度。
来源:AWS、SemiAnalysis
我们认为台积电的N3P是3nm平台上的“高性能计算旋钮”,它在N3E的基础上实现了虽小但意义重大的提升,无需新的设计规则即可提高频率或降低功耗。公开数据显示,N3P保留了N3E的规则和IP,但在相同漏电情况下速度提升约5%,或在相同频率下功耗降低5%—10%,此外,在混合逻辑/SRAM/模拟设计中有效密度提升约4%。这正是超大规模集成电路制造商在大型AI ASIC中所需要的渐进式、低摩擦的增益。
Trainium3 就是一个很好的例子,它说明了为什么这类产品适合采用这种制程工艺。Trainium3 也充分体现了定制加速器为何会占据 3 纳米高性能计算 (HPC) 产能的大部分:高密度矩阵引擎、大容量 SRAM 切片以及超长的片上互连,这些都受益于器件延迟和漏电的每一次微小降低。
N3P 的底层技术与其说是一项单一的突破,不如说是多项设计-技术协同优化 (DTCO) 调整叠加的结果。N3 代 FinFlex 库允许设计人员在模块内混合使用更宽和更窄的鳍片,从而以精细的粒度权衡驱动强度、面积和漏电。台积电还改进了 N3P 底层金属堆叠中的衬线和阻挡层工艺,与之前的 3nm 工艺相比,降低了线路和过孔电阻。这些改进共同提升了裕量,从而支持更高的时钟频率或更低的低电压,尤其是在长全局路径上。
挑战在于,N3P工艺在推进互连线尺寸缩小和图形化的同时,几乎达到了当前EUV光刻工具所能达到的极限。最小金属间距在20纳米左右,高纵横比通孔以及更小的光学尺寸缩小都会加剧后端工艺的变异性和RC值。诸如通孔轮廓控制、蚀刻不足和介质损伤等问题都成为首要的时序问题。对于台积电而言,这意味着更脆弱的工艺窗口、更复杂的在线监控以及更频繁地使用DTCO反馈回路,以确保设计规则与生产线大规模生产的能力保持一致。目前,N3P工艺的缺陷密度改善速度低于预期,这导致芯片设计人员要么需要重新旋印以提高良率,要么只能等待工艺改进。
能够解读芯片标识的读者会发现,上图所示的封装正是Trn2,而我们也正是采用了这款芯片,因为它的封装布局与Trainium3完全相同。该封装由两个CoWoS-R组件构成,而非一个大型中介层。两个计算芯片通过基板相互连接。
Trainium3 将继续采用台积电的 CoWoS-R 平台,该平台在保持成本竞争力的同时,突破了功耗和延迟的极限。与前代产品 Trainium2 不同,Trainium3 没有采用全硅中介层,而是沿用了有机薄膜中介层,该中介层由六层铜 RDL 层构成,覆盖了光罩级尺寸,成本更低,机械柔顺性也优于硅中介层。它仍然支持芯片与中介层之间数十微米的精细布线和微凸点间距,这对于高密度芯片组结构和 HBM 接口至关重要。其下方是二十层 ABF 基板,该基板将电源和 XSR 信号扇出到模块边界处的 130 至 150 微米 C4 凸点,MCM 在此处与电路板连接。
在CoWoS-R架构上,超过六层的多层RDL并非硬性限制,而是一种有意为之的折衷方案。纯有机中介层成本低廉且符合规范,但当我们尝试以32Gbps或更高的速率集成更多通道时,其性能终将达到极限。IPD(集成无源器件)通过在必要位置将小型硅无源元件嵌入有机层中来弥补这一不足。每个RDL中介层中数千个IPD能够实现亚微米级布线密度、极小的微凸点间距,并在芯片噪声最大的区域(例如HBM PHY环和核心结构)实现强大的去耦。
该芯片的前端由Annapurna设计,PCIe SerDes部分则获得了Synopsys的授权。后端物理设计和封装设计由Alchip负责。我们认为Trainium3可能继承了Marvell设计的Trainium2的部分接口IP,但就内容而言意义不大。Marvell还委托其他第三方厂商进行封装设计。
有趣的是,有两个流片项目,一个由Alchip拥有(称为“Anita”),另一个则由Annapurna直接拥有(称为“Mariana”)。在Anita项目中,Alchip直接从台积电采购芯片组件;而在Mariana项目中,Annapurna也直接采购芯片组件。大部分产量将用于Mariana项目。虽然Alchip在Mariana项目中的设计参与度与Anita项目类似,但他们从Mariana项目获得的收入应该会低于Anita项目。亚马逊和Annapurna都非常注重成本控制,并对供应商施加了很大的压力。与博通的ASIC交易相比,Trainium项目留给芯片设计合作伙伴Alchip和Marvell的利润空间要小得多。就每总拥有成本(TCO)的性能而言,Annapurna更加重视降低TCO。
Marvell最终成了这场竞争的最大输家。尽管Trainium2是由他们设计的,但他们在这一代芯片的设计竞赛中输给了Alchip。Marvell的Trainium3版本采用了基于芯片组(chiplet)的设计,将I/O功能放在一个独立的芯片组上,而不是像Trainium2和即将推出的Trainium3那样,将计算功能集成在一个单芯片上。
Marvell 因 Trainium2 的糟糕执行而失去了这个插槽。开发周期过长。Marvell 在设计该封装的 RDL 中介层时也遇到了问题,最终 Alchip 不得不介入,帮助其交付一个可行的方案。

Trainium4路线图预估
Trainium4将由多家设计公司参与,分别基于不同的扩展协议,分两条不同的轨道进行开发。我们早在 7 个月前的 5 月份就详细介绍了 Trainium 4 加速器模型中 UALink/NVLink 的划分。与 Trainium3 一样,Alchip 将继续主导两条轨道的后端设计。
- 第一条轨道将采用UALink 224G。
- 第二条轨道将使用英伟达的NVLink 448G BiDi协议。
英伟达的VR芯片NVL144与Trainium4等NVLink Fusion产品之间很可能存在显著的时间差。对于NVLink Fusion产品线而言,时间线可能会进一步延后,因为Fusion芯片引入了额外的集成和验证要求,而且大多数英伟达混合信号工程师都将把精力集中在Nvidia VR芯片NVL144新产品的推出上。
虽然搭载 NVLink Fusion 的 Trainium4 可能短期内不会面世,但我们相信 AWS 已获得有利的商业条款,不太可能支付英伟达通常约 75% 的毛利率。英伟达有强烈的战略动机来实现与 Trainium4 的互操作性,因为允许 AWS 使用 NVLink 有助于英伟达维持其系统级锁定。因此,英伟达可能会提供比其标准毛利率结构下更具吸引力的价格。
与仅限于固定72封装NVLink域的VR NVL144不同,Trainium4可通过跨机架AEC扩展NVLink的规模,从而实现更大的144+相干域。NVLink 6采用400G双向SerDes,允许在同一根导线上同时进行200G接收和200G发送。这种400G双向信号传输已经接近铜缆的实际极限,尽管一些厂商可能会尝试向前迈半代,推出600G双向信号传输。
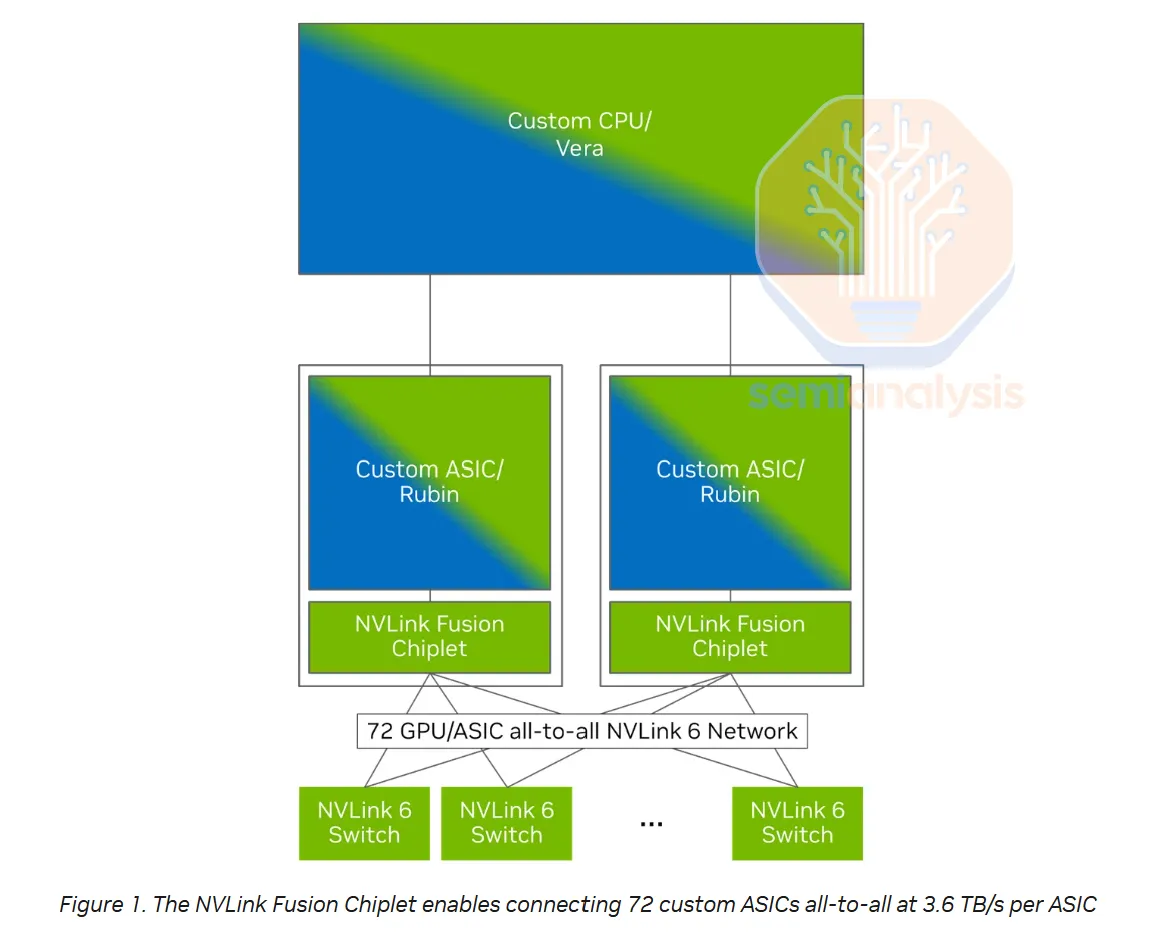
来源:英伟达
Trn2/3 NL16 2D 环面和 NL64 3D 环面
Trainium2 NL16 2D Torus 和 Trainium2 NL64 3D Torus SKU 分别被命名为 Trainium2 Server 和 Trainium2 UltraServer,并在 re:Invent 2024 大会上发布。我们在 Trainium2 深度解析中介绍了这两种架构。
简要回顾一下 Trainium2 SKU——Trainium2 NL16 2D Torus 和 Trainium2 NL64 3D Torus SKU 的主要区别在于扩展世界的大小。Trainium2 NL16 2D Torus 在整个扩展世界大小下占用半个服务器机架,该世界大小包含 16 个 Trainium2 设备,构成一个 4x4 网格的 2D 环面。而 Trainium2 NL32x2 3D Torus 则由四个 Trainium2 NL16 2D Torus 半机架服务器连接而成,总共占用两个机架。这四个 Trainium2 NL16 2D Torus 半机架服务器通过 AEC 连接,从而创建一个包含 64 个 Trainium2 设备的 4x4x4 3D 环面。
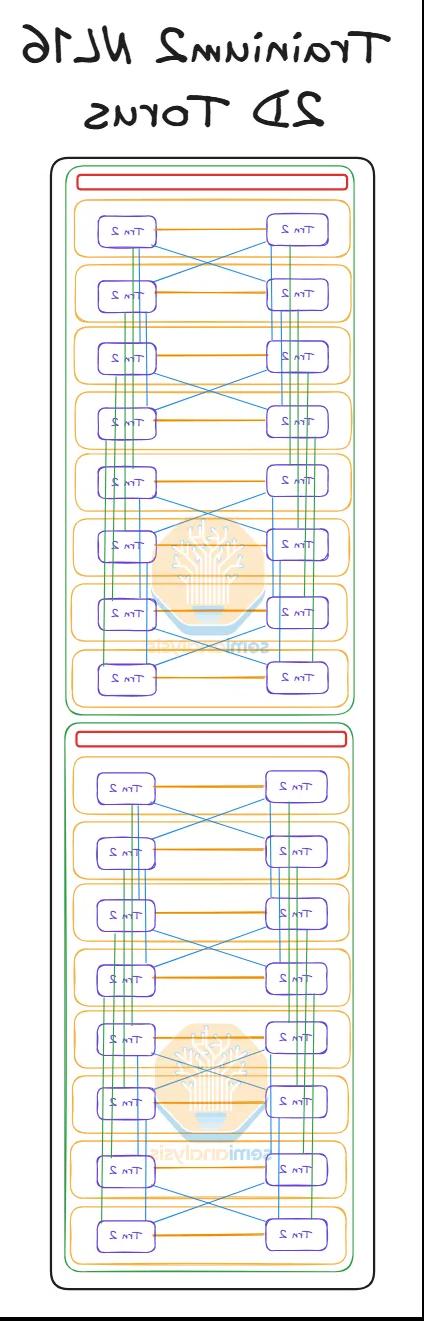
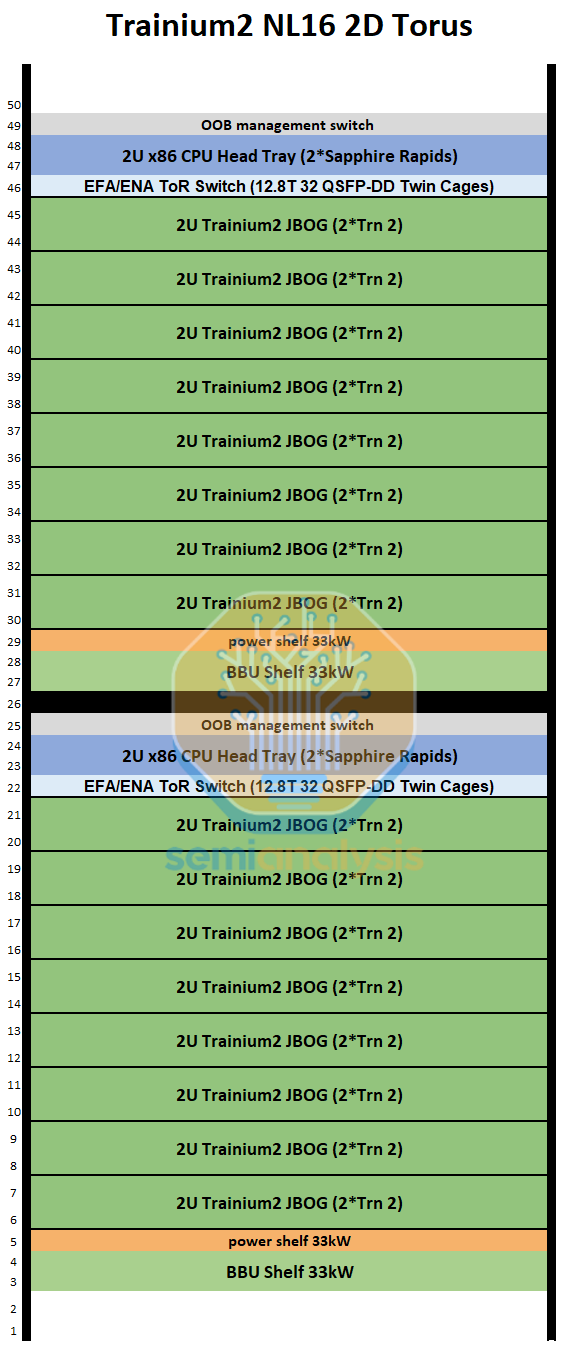
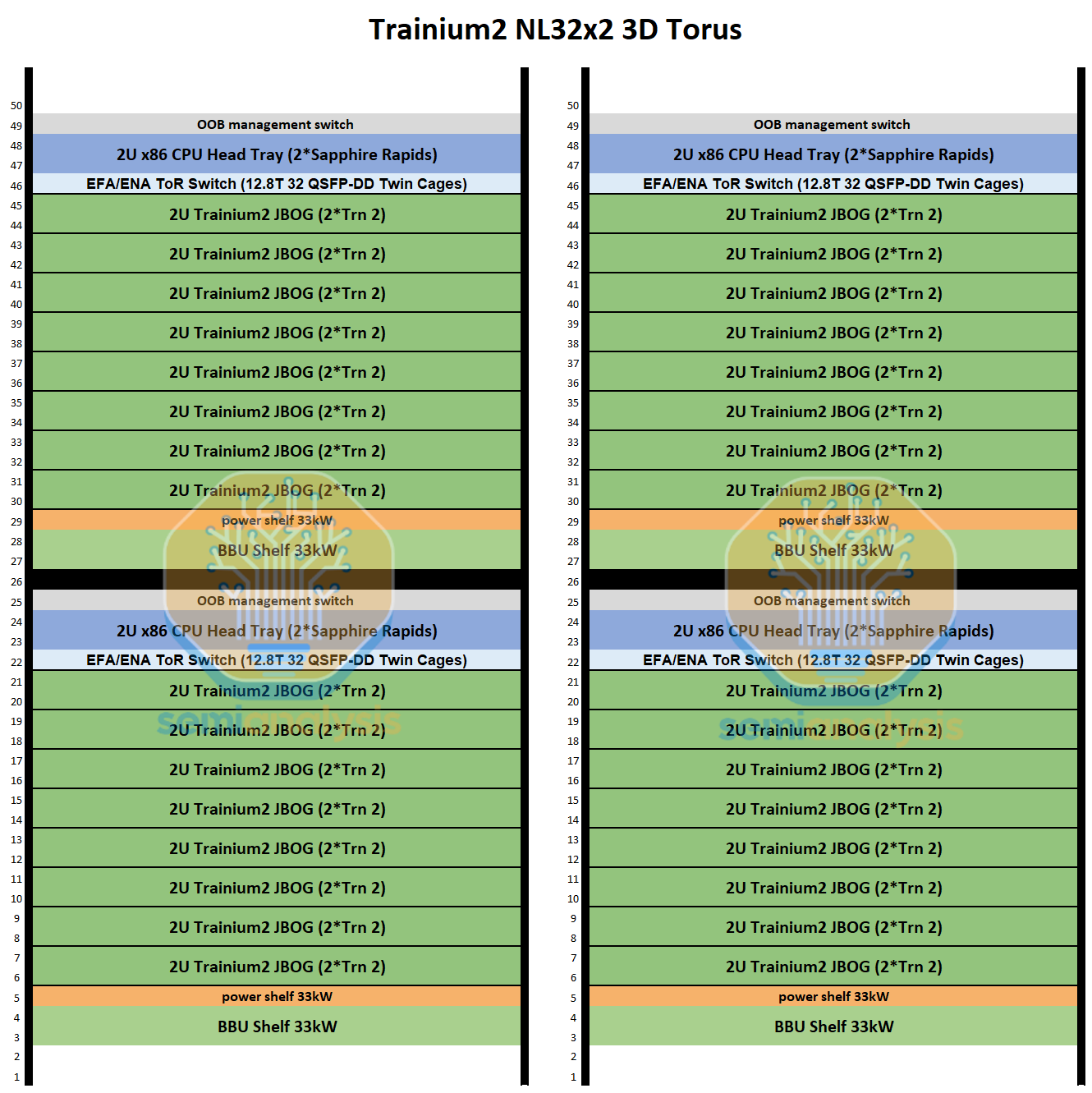
请注意,在上图中,Trainium2 NL16 2D 环形图表示一个完整的机架,但包括图中所示机架内的两个放大世界。
如前所述,Trainium2 目前仅提供 NL16 2D Torus 和 NL32x2 3D Torus 机架式 SKU,分别采用 2D 和 3D Torus 拓扑结构,不提供其他拓扑结构。由于 Anthropic 的 Rainier 项目是 Trainium2 的主要需求来源,因此 Trainium2 的部署将主要采用 NL64 3D Torus 外形尺寸,生产也将遵循其对 NL64 3D Torus 的偏好。这是因为 Anthropic 的推理模型需要更大规模的拓扑结构。
可切换机架规模架构
当英伟达推出采用全对全扩展拓扑结构、扩展规模可达72颗芯片的Oberon架构(GB200 NVL72)时,许多ASIC和GPU制造商调整了未来的机架式设计路线图,以模仿英伟达的Oberon架构。虽然AMD率先发布了类似Oberon架构的MI400 Helios机架式服务器,但AWS将成为除英伟达之外首家实际交付并部署类似全对全交换式扩展架构的厂商,其产品采用Trainium3 NL32x2交换式和Trainium3 NL72x2交换式封装。AMD的首款机架式扩展设计MI450X UALoE72将比Trainium3的机架式扩展设计晚一年发布,预计在年底上市。Meta也将在AMD的MI450X之前推出其首款交换式架构产品。我们将在本文的“3D 环面架构与切换架构”部分解释为什么切换式扩展架构优于环面架构。
在 re:Invent 大会上展出的 Trainium3 UltraServer 对应于 Trainium3 NL72x2 Switched 机架式服务器,但 Trainium3 NL72x2 Switched 只是 Trainium3 全交换机机架式服务器的两种型号之一——另一种型号是 Trainium3 NL32x2 Switched。与 Trainium3 NL72x2 Switched 一样,Trainium3 NL32x2 Switched 也是全交换机式服务器,但它与 Trainium3 NL72x2 Switched 的区别在于,Trainium3 NL32x2 Switched 采用风冷散热,因此其扩展规模较小,功率密度也较低。
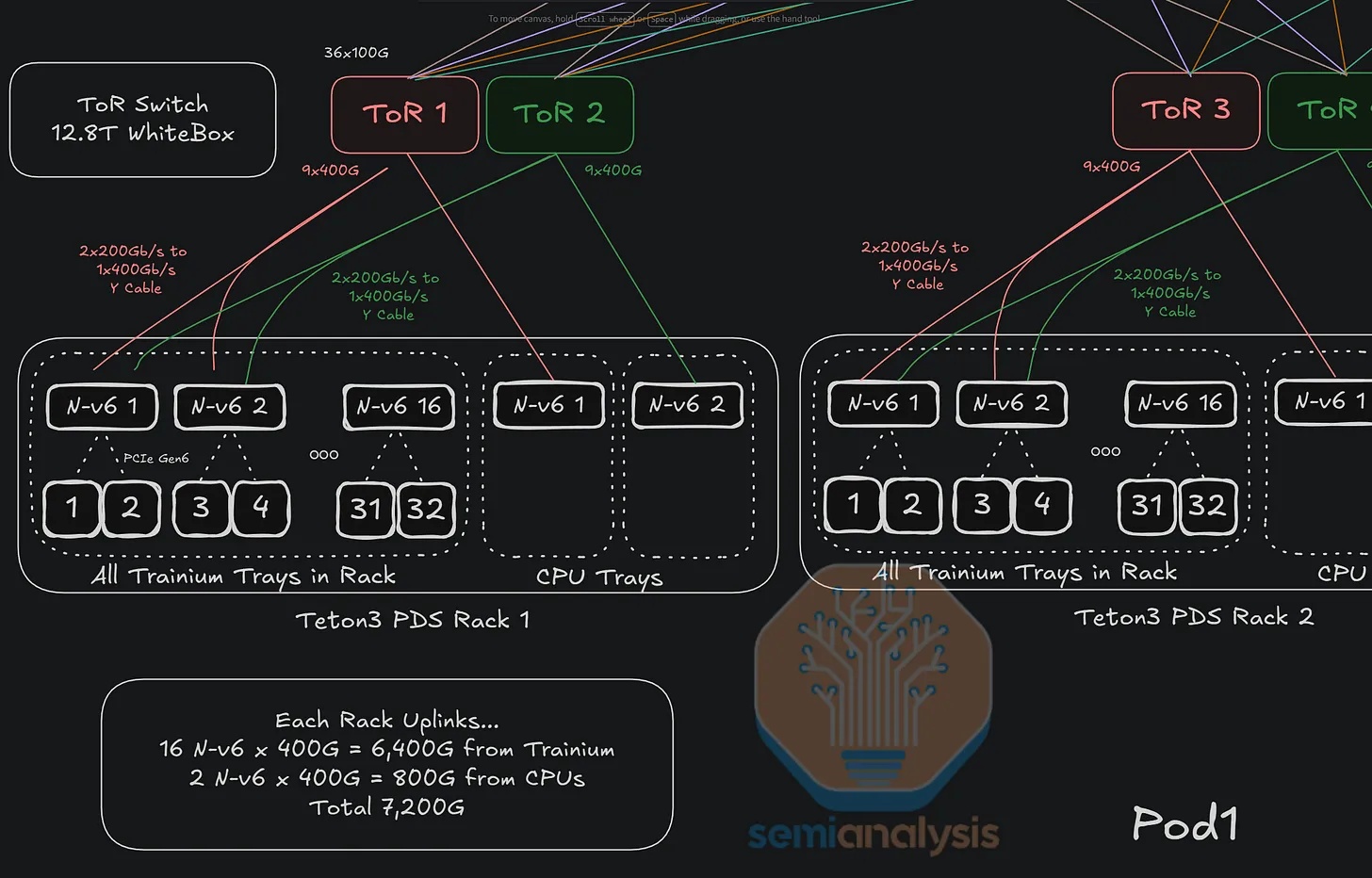
Trainium3 NL32x2 开关式(Teton3 PDS)
机架架构
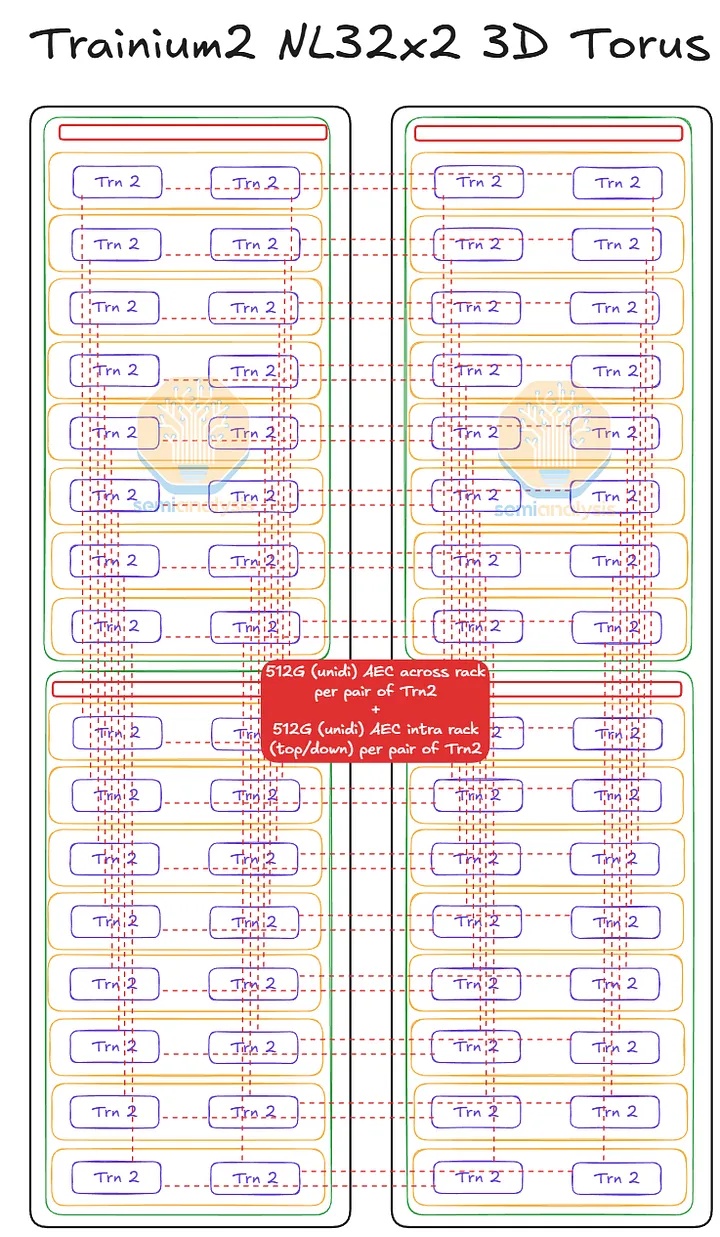
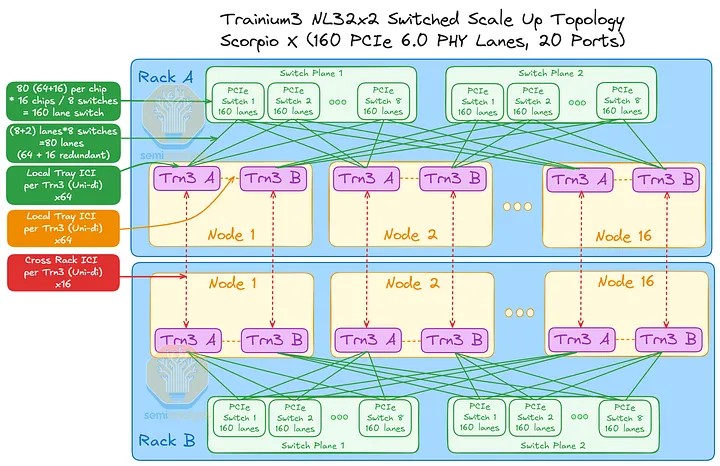
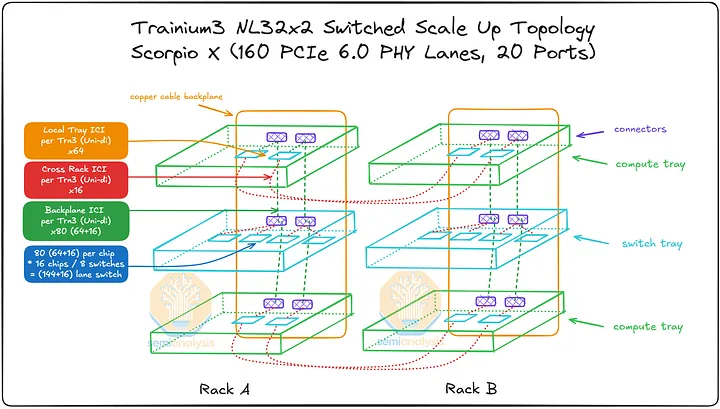
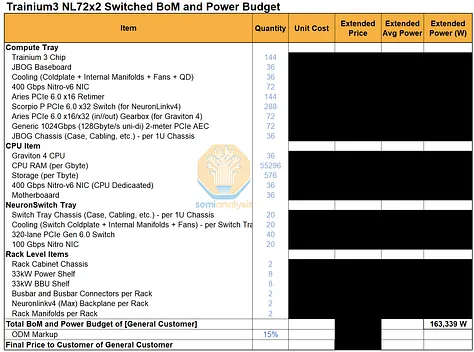
Trainium3 NL32x2 Switched 的机架布局与 Trainium NL32x2 3D Torus 非常相似。两者每个机架都包含 16 个 JBOG(GPU 集群)托架和两个主机 CPU 托架。每个 JBOG 托架包含两个 Trainium3 加速器,因此每个机架总共有 32 个 Trainium3 芯片。一个完整的 Trainium3 NL32x2 Switched 扩展世界由两个机架组成,每个机架包含 32 个 Trainium3 芯片,总共可构建一个包含 64 个 Trainium3 芯片的世界。
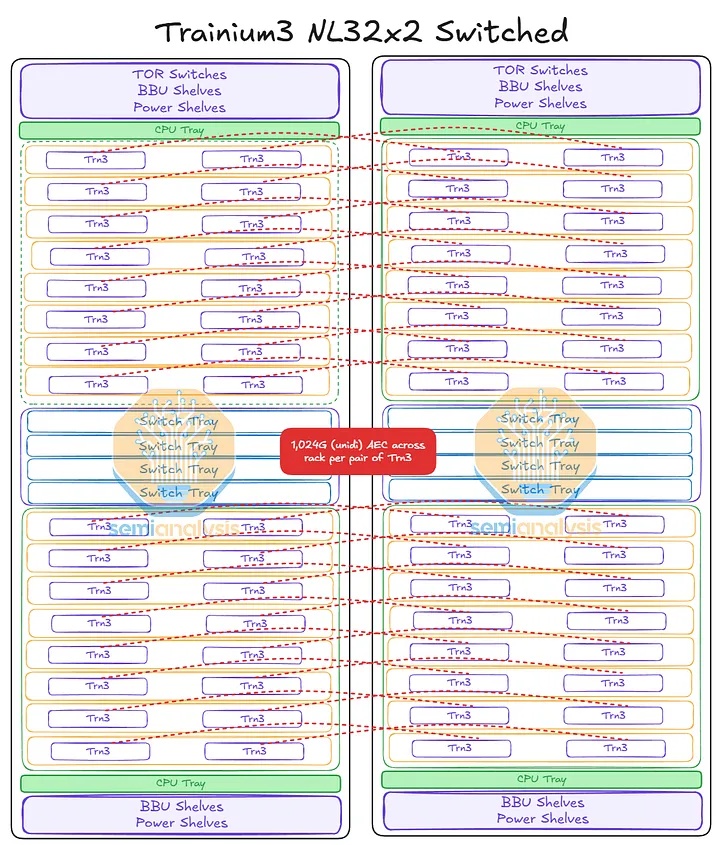
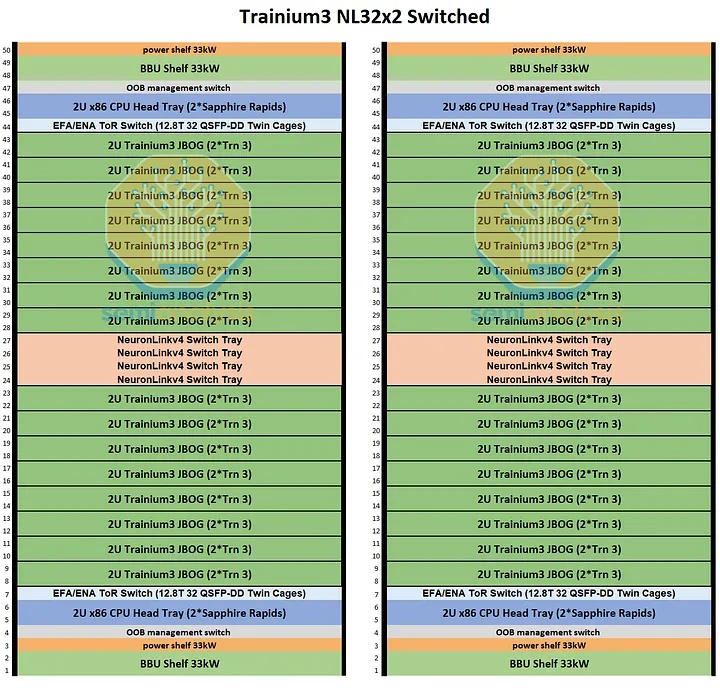
Trainium NL32x2 3D Torus 和 Trainium NL32x2 Switched 的主要区别在于,Trainium NL32x2 Switched 在机架中间增加了可扩展的 NeuronLink 交换机托架,从而实现了全对全交换网络。NeuronLink 交换机托架之所以放置在机架中间,原因与 Nvidia Oberon 机架中 NVLink 交换机托架的放置位置相同,都是为了最大限度地缩短加速器和可扩展交换机之间最长 SerDes 传输距离。此外,Trainium NL32x2 Switched 还将 CPU 托架、电源架、电池备份单元 (BBU) 托架和机架顶部 (ToR) 交换机的位置也进行了调整,从始终位于各自 8 个 JBOG 托架组的顶部,改为位于机架的顶部和底部,从而缩短了 16 个 JBOG 托架和 4 个 NeuronLink 交换机托架之间的距离。此外,还将推出配备五个 NeuronLink 交换机托架的设计,支持热插拔交换机托架,无需停机。这与英伟达的 GB200/300 NVL72/VR NVL144 形成鲜明对比,后者的操作员必须先清空机架上的所有工作负载才能更换交换机托架。亚马逊的理念始终以现场可维护性和可靠性为核心,因为他们在部署和管理中扮演着至关重要的角色。而英伟达则为了追求性能而忽略其他方面,因为这正是他们所追求的。
其他主要区别在于 NeuronLink 拓扑结构和相关的连接组件。Trainium NL32x2 交换式架构将通过跨机架 AEC 连接两个机架,机架 A 中的一颗芯片可直接连接到机架 B 中的另一颗芯片。我们将在本文后面更详细地讨论这种扩展网络。
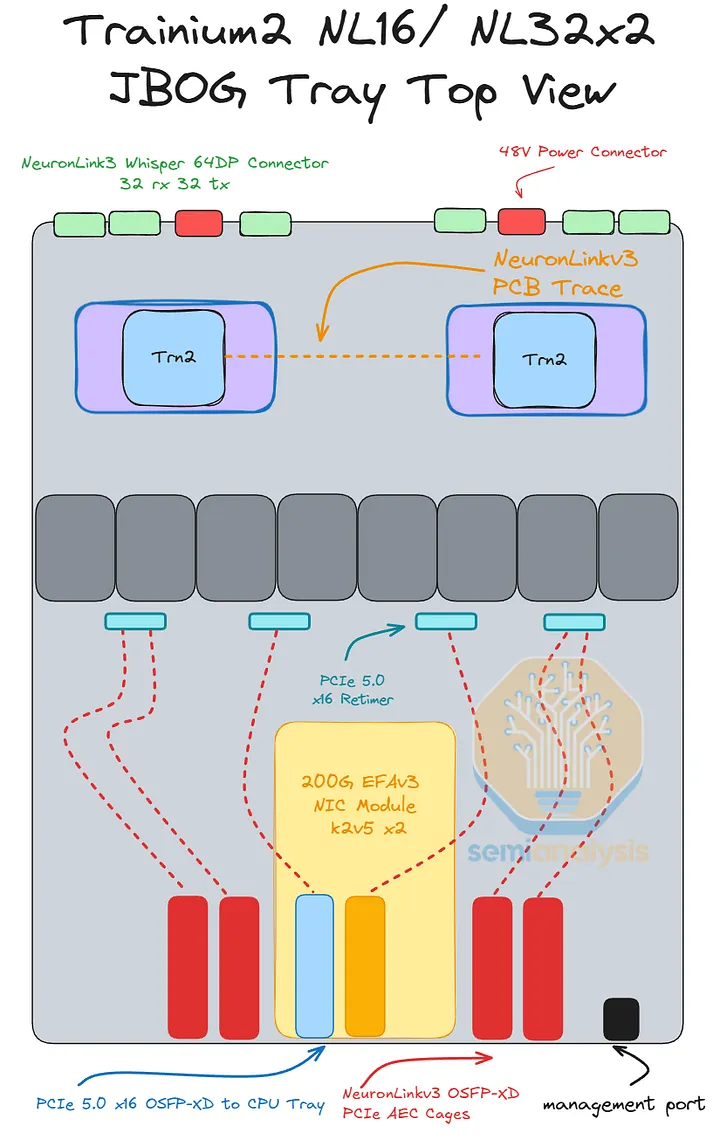
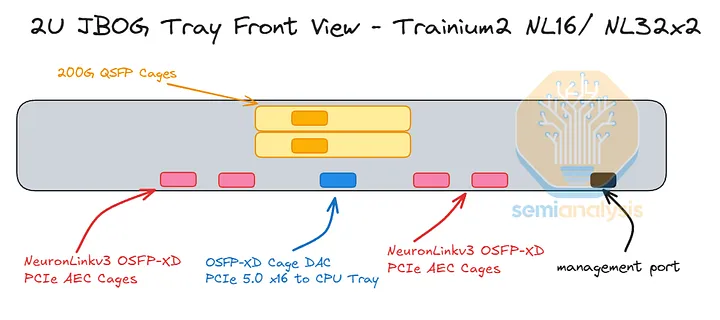
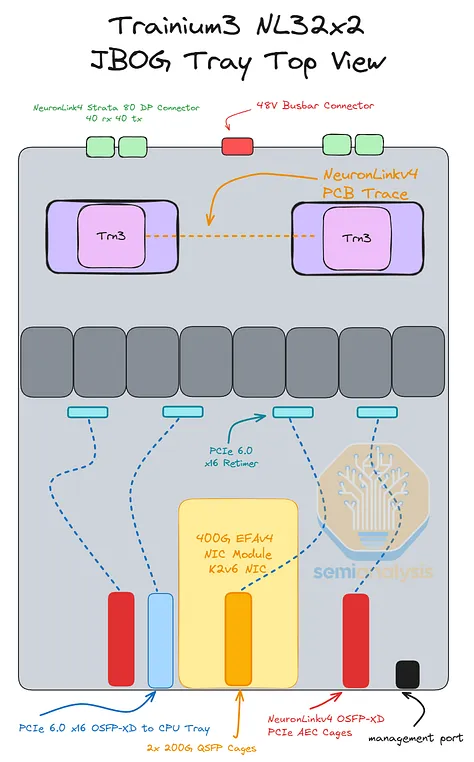
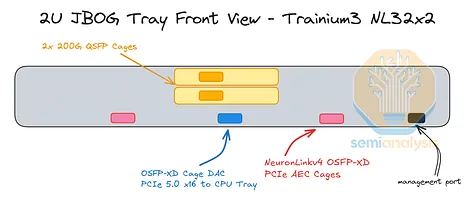
JBOG/计算托盘
Trainium3 NL32x2 Switched 的 JBOG 托盘与 Trainium NL32x2 3D Torus 的非常相似。每个 JBOG 将包含两颗 Trainium3 芯片。Trainium3 NL32x2 Switched 采用基于 PCIe 6.0 的连接方式,相比使用 PCIe 5.0 连接的 Trainium2 NL16 2D Torus 和 Trainium2 NL32x2 3D Torus JBOG 而言,这是一项升级。因此,PCB 材料也需要从 M8 级覆铜板 (CCL)(具体而言,是低 DK2 玻璃纤维布 + HVLP2 铜箔)升级到 M8.5 级覆铜板 (CCL)(低 DK2 玻璃纤维布 + HVLP4 铜箔)。
迄今为止,所有 Trainium 机架均采用无电缆设计理念以提高组装效率,因此所有信号均通过 PCB 走线传输。信号在 PCB 上传输时的损耗远高于通过架空电缆传输时的损耗,因此必须在 JBOG 板中间放置四个 PCIe 6.0 x16 重定时器,以补偿在前置 I/O 端口和两个 Trainium3 封装之间通过 PCB 传输的信号。
Trainium3 的网卡也位于 JBOG 托盘内。对于 AWS 的后端网络 EFAv4,Trainium3 NL32x2 交换式网卡有两种配置可供选择:
- 方案一:每个装有两块 Trainium3 芯片的 JBOG 托架配备一个 Nitro-v6 (2*200G) 400Gbps 网卡模块:每块 Trainium3 芯片提供 200Gbps 的 EFA 带宽。
- 方案二:每个 JBOG 托架配备两个 Nitro-v6 (2*200G) 400Gbps Nitro NIC 模块,每个 Trainium3 芯片提供 400Gbps 的 EFA 带宽。
绝大多数基于 Trainium3 的服务器将采用方方案一。每两块 Trainium3 芯片配备一块 Nitro-v6 400G 网卡,这意味着每块 Trainium3 芯片拥有 200Gbps 的横向扩展带宽。AWS 认为,即使对于目前规模最大的生产级推理模型,每块 GPU 200Gbps 的带宽也足以满足预填充实例和解码实例之间键值缓存传输的重叠需求。对于训练模型,AWS 的理念是,像 Anthropic 这样拥有精英程序员的小型公司会使用流水线并行 (PP) 来降低网络流量,而不仅仅依赖于 FSDP/TP/Ctx 并行/DP。然而,需要注意的是,流水线并行对于大规模训练来说是绝对必要的,但维护和调试使用 PP 的代码库却非常麻烦。
对于 AWS 的前端网络 ENA,CPU 托架内配备了一个专用的 Nitro-v6 (2*200) 400Gbps 网卡模块。为了将每个 JBOG 托架连接到 CPU 托架,服务器正面铺设了一条专用的 PCIe 6.0 x16 DAC 线缆(128Gbyte/s 单向)。Trainium2 NL16 2D Torus 也以相同的方式连接 CPU 托架和 JBOG 托架。
Trainium3 NL32x2 Switched 的 CPU 托架布局与 Trainium2 NL16 2D Torus 的布局非常相似,在Trainium2 文章中有详细说明。
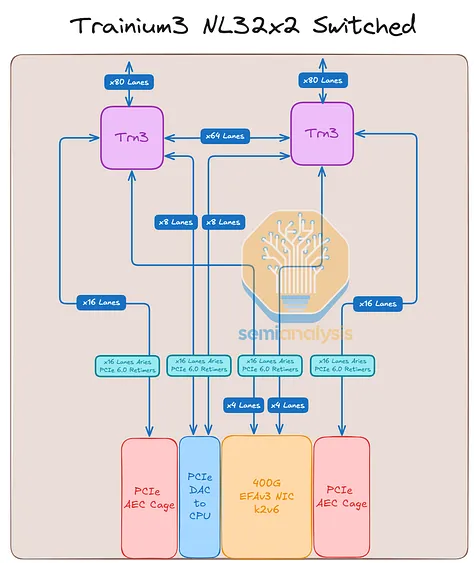
Trainium3 NL32x2 Switched 是 Trainium3 最新推出的产品,支持可切换式扩展架构。由于采用风冷机架设计,其机架功率密度较低。其功率密度与 Trainium3 NL32x2 3D Torus 基本相同,主要区别在于增加了扩展交换机托架。此外,Trainium3 NL32x2 Switched 也是唯一一款支持可切换式扩展架构且可在非液冷数据中心部署的产品。
由于液冷数据中心的部署目前是部署的关键瓶颈,因此采用风冷散热的Trainium3芯片相比其他竞争对手的液冷式可扩展交换加速器,具有上市时间优势。当运营商试图将液冷机架强行部署到风冷数据中心时,他们必须使用效率低下的液冷-风冷侧挂式冷却器。因此,我们预计到2026年部署的Trainium3芯片中,大部分将是Trainium3 NL32x2交换式SKU。
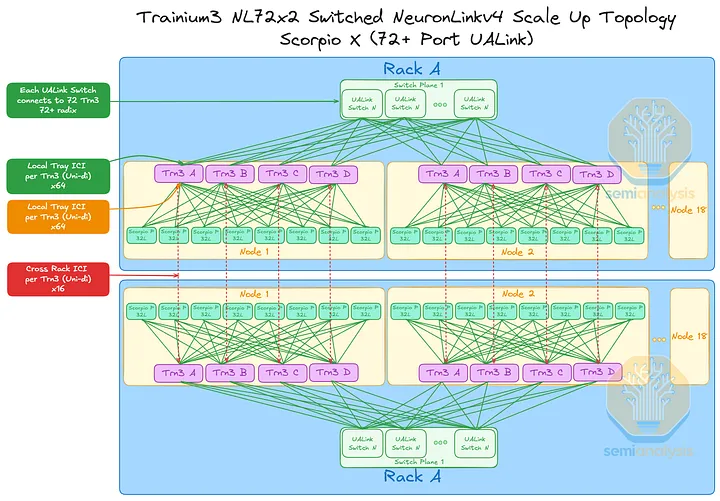
Trainium3 NL72x2 开关式(Teton3 Max)
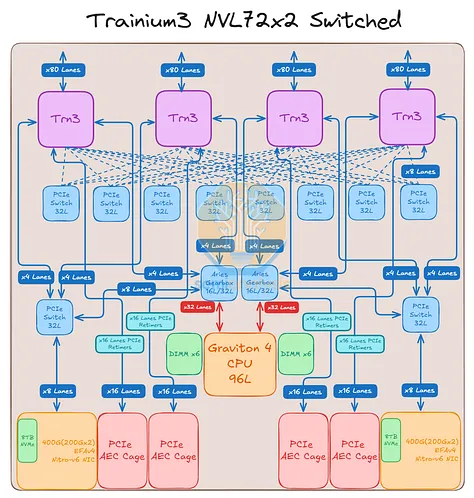
Trainium3 NL32x2 Switched 和 Trainium3 NL72x2 Switched 都采用了全交换架构,但 Trainium3 NL72x2 Switched 的机架式架构与 Nvidia 的 GB200 NVL72 Oberon 架构最为相似。除了 Oberon 和 Trainium3 NL72x2 Switched 都采用液冷散热外,Trainium3 NL72x2 Switched 还将 CPU 集成到计算托架中,就像 Nvidia 将 Grace 和 Vera 与 GPU 集成在同一个计算托架上一样。相比之下,Trainium NL32x2 Switched 仍然使用分离式 CPU 节点。与 Oberon 一样,Trainium NL72x2 Switched 也使用冷板对 Trainium3 加速器和 Graviton 4 CPU 进行液冷散热。Trainium NL72x2 Switched 与 Oberon 架构的主要区别在于它采用了跨机架连接,从而扩展了规模,使其能够跨越两个机架。
机架架构
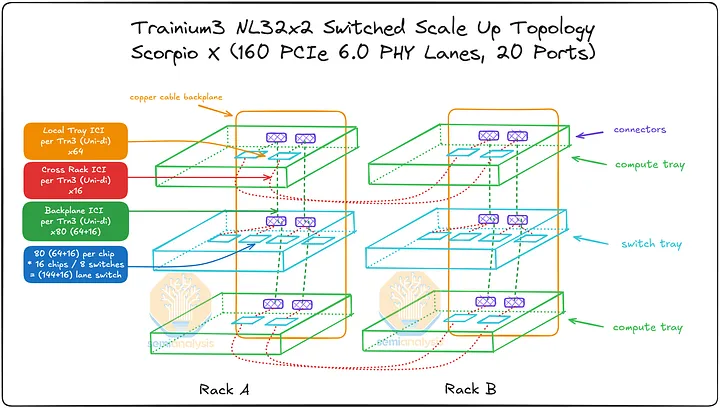
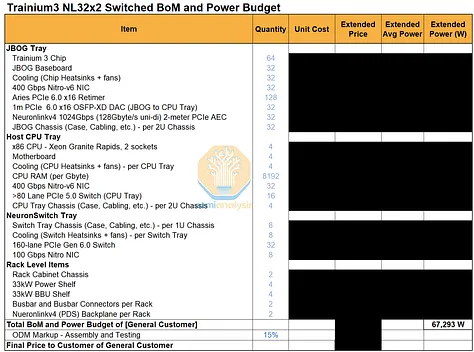
Trainium3 NL72x2 Switched 使用两个机架来实现 144 个 XPU 的全球规模,每个机架包含 18 个计算托架和 10 个位于中间的 NeuronLink 交换机托架。每个计算托架包含四个 Trainium3 和一个 Graviton4 CPU,因此 Trainium3 NL72x2 Switched 的全球规模由两个机架组成,共包含 144 个 Trainium3 和 36 个 Graviton4。与 Trainium3 NL32x2 Switched 一样,Trainium3 NL72x2 Switched 也使用母线供电。背板采用了 TE 和 Amphenol 的混合连接器,因此我们在网络模型中采用了不同的连接器。
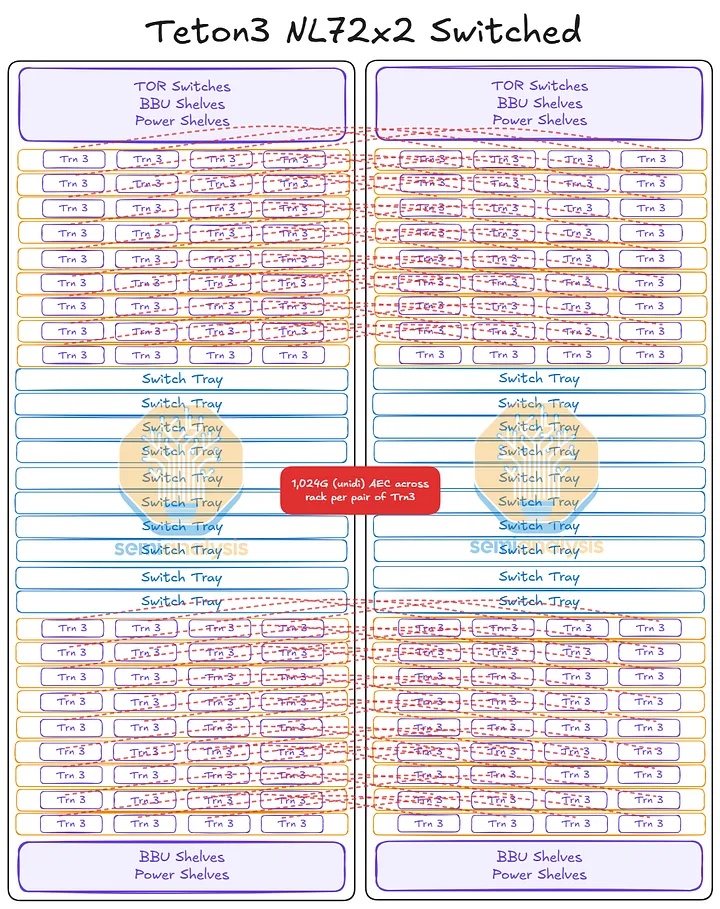
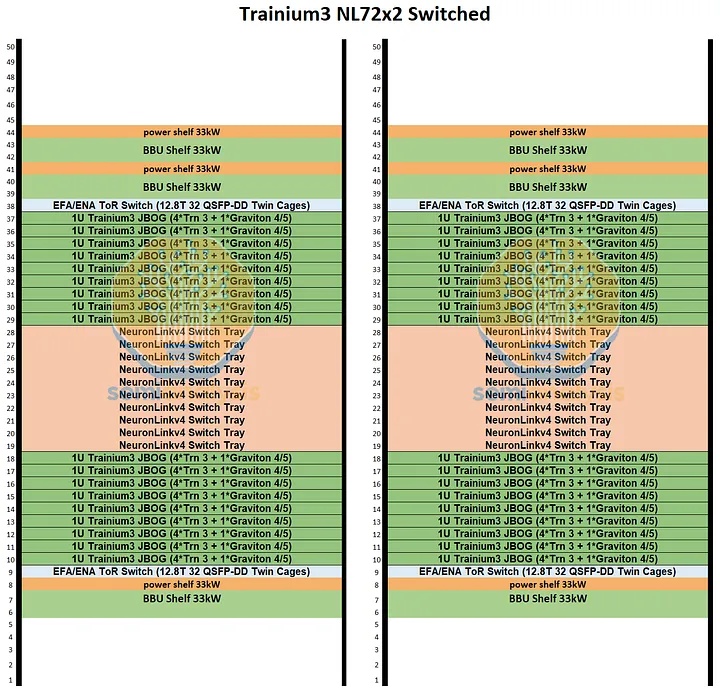
计算机托盘
Trainium3 NL72x2 Switched 的高计算密度和功率密度始于其计算托架,每个计算托架包含四个 Trainium3 芯片。Trainium3 NL72x2 Switched 的连接主要基于 PCIe 6.0,因此其 PCB 材料与上述 Trainium3 NL32x2 Switched 相同。为了增加各个 Trainium3 芯片与前置 I/O 端口之间的信号传输距离,使用了六个 PCIe 6.0 x16 重定时器。需要注意的是,由于其采用无电缆设计以提高生产速度,因此其上市设计中包含了一些低成本的重定时器,以降低设计风险。在成功完成初始生产部署后,AWS 可以考虑优化设计,并有可能移除部分重定时器。
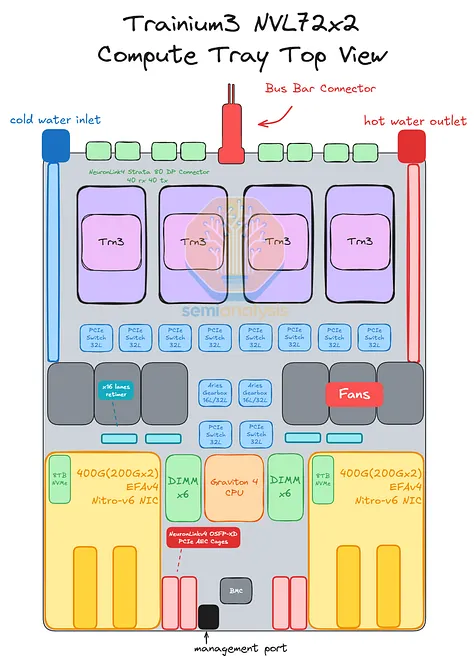
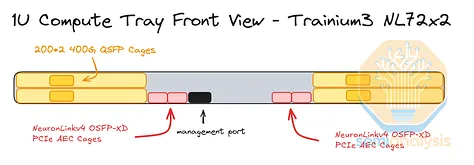
如上所述,Trainium3 NL32x2 Switched 和 Trainium3 NL72x2 Switched 的主要区别在于散热方式:Trainium3 NL72x2 Switched 采用液冷散热,而 Trainium3 NL32x2 Switched 采用风冷散热。液冷散热用于冷却 Trainium3 模块、NeuronLinkv4 x32 通道 PCIe 6.0 交换机和 Graviton4 CPU。计算托架中的其他组件,包括 PCIe 6.0 x16 重定时器、Nitro-v6 网卡、PCIe 6.0 x16 AEC 硬盘笼、DIMM 内存条和 2 块 8TB 本地 NVMe 硬盘,则采用风扇进行风冷散热。
就主机CPU而言,Graviton4将是Trainium3 NL72x2 Switched目前唯一可用的CPU选项。在Trainium3的生命周期内,用户可以将CPU升级到下一代Graviton处理器。理论上,x86 CPU也受支持,因为它们也可以通过PCIe与其他组件连接,但我们认为厂商不会推出x86版本的Trainium3 NL72x2 Switched,而只会提供x86版本的Trainium NL32x2 Switched。由于Trainium3使用PCIe 6.0,而Graviton4使用PCIe 5.0,因此需要在CPU旁边放置两个PCIe转换器,以实现CPU和GPU之间的PCIe 6.0到PCIe 5.0的转换。CPU内存方面,CPU旁边设有12个DDR5 DIMM插槽,主流版本将使用64GB和128GB容量的DDR5 DIMM内存条。每个计算托架将使用两块 8TB 本地 NVMe 硬盘作为本地存储。
Trainium3 NL72x2 交换式横向扩展网络
Trainium3 NL72x2 Switched 将具有与 Trainium3 NL32x2 Switched 相同的横向扩展网络配置,即每个 Trainium3 芯片可以选择 400G 或 200G 的横向扩展带宽:
- 方案一:每个装有四颗 Trainium3 芯片的 JBOG 托架配备两个 Nitro-V6 (2*200G) 400Gbps 网卡模块:每颗 Trainium3 芯片提供 200Gbps 的 EFA 带宽。
- 方案二:每个 JBOG 托盘包含四个 Trainium3 芯片,每个芯片配备四个 Nitro-V6 (2*200G) 400Gbps Nitro NIC 模块:每个 Trainium3 芯片提供 400Gbps 的 EFA 带宽。
与 Trainium3 NL32x2 交换式交换机一样,绝大多数 Trainium3 NL72x2 产品将采用方案一。每两个 Trainium3 芯片配备一个 Nitro-v6 400G 网卡,每个 Trainium3 芯片的横向扩展带宽为 200Gbps。
不过,Trainium3 NL72x2 交换机版与普通版的区别在于,主机 CPU 位于计算托架上,而专用于 CPU 的 Nitro-V6 (2*200) 400Gbps 网卡模块也位于该托架内。此外,借助 PCIe 交换机,CPU 还可以使用 Trainium3 专用网卡与外部网络通信。
Trainium3 NL72x2 Switched 是 AWS 针对 Nvidia Oberon 机架式架构推出的解决方案。Trainium3 NL72x2 Switched 架构的功率密度远高于其前代产品。由于其高功率密度以及对液冷数据中心的需求,我们预计 Trainium3 的部分产品将采用 Trainium3 NL72x2 Switched SKU,但大部分产品仍将采用 Trainium3 NL32x2 Switched。了解了机架布局和计算托架布局/拓扑结构之后,现在是时候深入了解 Trainium3 NL32x2 Switched 和 Trainium3 NL72x2 Switched 的真正核心优势——交换式纵向扩展网络拓扑结构。
扩展网络架构
2D/3D 环形网络与交换式扩展网络
在详细介绍新型交换式横向扩展网络的具体拓扑结构之前,我们先来解释一下 AWS 为何选择从 2D/3D 环面架构转向交换式架构。Trainium2 NL26 2D 环面服务器和 Trainium2 NL32x2 3D 环面服务器的 NeuronLinkv3 横向扩展拓扑结构分别是 2D 网状环面和 3D 网状环面。然而,对于需要全连接集合的MoE模型而言,保持环面拓扑结构并非最优。相比之下,密集模型并不大量使用全连接集合,这意味着交换式架构在与密集模型配合使用时性能优势并不明显,但总体拥有成本 (TCO) 却更高。
采用 3D Torus 架构时,由于扩展域内芯片间的过载,当消息大小从 16KB 增长到 1MB(即批处理大小增加)时,扩展网络会因过载而突然面临带宽瓶颈。相比之下,Trainium3 独特的交换式拓扑结构,即使其第一代交换式网络并非扁平的单层交换式拓扑,也不会出现过载现象。
对于预填充而言,更大的Trainium3 NL72x2 Switched扩展拓扑结构并不能带来显著优势,因为预填充通常受限于计算能力,而更大的拓扑结构主要适用于解码阶段的大规模专家并行计算。对于参数总数为2-3的前沿MoE模型,Trainium3 NL32x2 Switched的扩展网络足以满足解码阶段的需求;但对于参数总数超过4万亿的前沿MoE模型,将这些模型部署在更大的Trainium3 NL72x2 Switched扩展网络上则能带来显著的性能提升。
Trainium3 NL32x2 交换式交换机和 Trainium3 NL72x2 交换式交换机旨在最终提供全对全的纵向扩展交换解决方案,但 AWS 秉持着以低 TCO 实现快速上市的理念,决定构建一种与当时可用的不同代纵向扩展交换机兼容的网络架构。
在深入探讨不同的机架架构和交换机世代之前,我们将首先分解 Trainium3 的 NeuronLinkv4/芯片间互连 (ICI) 带宽的组成部分。
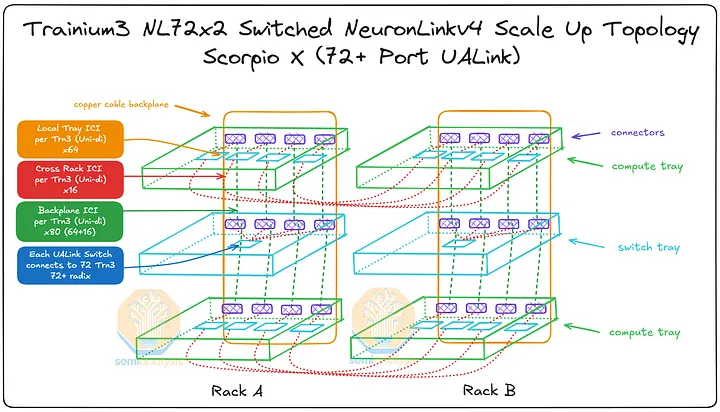
用于 Trainium3 的 NeuronLinkv4 服务器内扩展网络使用三种不同的连接介质连接 XPU:通过 PCB、背板和跨机架连接。我们将详细介绍扩展网络连接,但为了便于参考,我们在本节末尾提供了一个简要表格进行总结。
Trainium3 在所有三种介质上共提供 160 条 PCIe NeuronLinkv4 连接通道,其中 144 条为活动通道,16 条为背板上的冗余通道。每台 Trainium3 的 160 条通道分布如下:背板:共有 80 条通道,其中 64 条处于活动状态,16 条为冗余通道。每条通道通过一个 Strada Whisper 背板连接器连接到背板,每个 Trainium3 芯片支持 160 对差分信号(DP,即 80 个 Tx DP 和 80 个 Rx DP)。AWS 利用冗余通道来应对背板电缆故障、交换机托盘级故障和端口托盘级故障,从而实现容错。
他们没有将这 16 条额外的通道用作额外的带宽,主要原因如下:
对于解码等延迟密集型工作负载,增加通道数并不会带来任何好处。这就像使用更大的管道并不会影响一滴水从管道一端流到另一端的速度一样。
即使启用全部 80 条通道,像训练这样通信密集型的工作负载也无法获得任何显著的性能提升,这是因为存在“掉队效应”。在任何大型训练运行中,至少会有几个机架的某些通道出现故障。如果只有一个 Trainium3 机架出现故障通道,那么整个训练作业将只能有效使用 80 条通道中的 64 条,因为所有其他机架都会等待速度最慢的机架。
PCB:通过 NeuronLinkv4 PCB 走线,为相邻的 Trainium3 芯片提供 64 条通道。对于 Trainium3 NL32x2 Switched 芯片,PCB 直接连接到相邻的 Trainium3 芯片;而对于 Trainium3 NL72x2 Switched 芯片,PCB 连接则通过八个 PCIe 6.0 32 通道交换机(或四个 64 通道交换机或两个 128 通道交换机)实现。这种设计的优势在于,AWS 可以在制造时选择每通道成本最低的方案。由于 PCB 芯片间互连 (ICI) 故障率远低于背板,因此无需在 PCB 上设置冗余通道。
跨机架:16 条通道从每个 Trainium3 通过 PCB 连接到 OSFP-XD 笼,然后通过 PCIe 有源电缆 (AEC) 连接到相邻的机架。
NeuronLink PCIe PHY 和 UALink 交换机
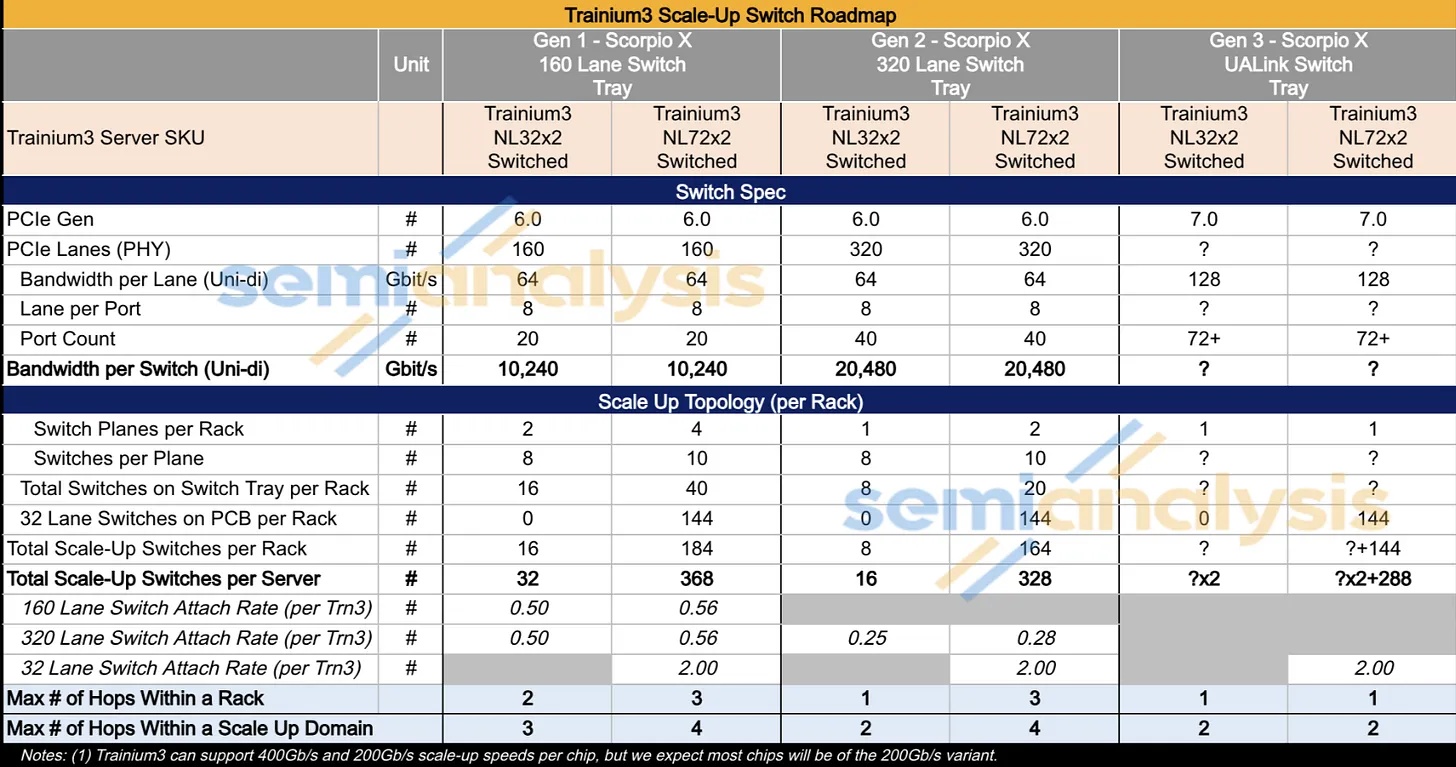
AWS 的NeuronLink目标是在尽可能实现供应链多样性的前提下,以最快的速度和最低的总体拥有成本将产品推向市场。其设计横向扩展网络架构的方法也遵循同样的原则。在 Trainium3 的生命周期内,共推出了三代横向扩展交换机:首先是 160 通道的 Scorpio X PCIe 6.0 交换机,然后是 320 通道的 Scorpio-X PCIe 6.0 交换机,最后还可以选择升级到更高基数的 72+ 端口 UALink 交换机。160 通道的 Scorpio-X 交换机可以实现快速上市,但缺点是它强制采用一种非理想的横向扩展网络拓扑结构,并非全连接,并且在同一 Trainium3 NL72x2 交换机架内的两个 Trainium3 芯片之间最多需要三个跳才能连接。然而,使用 320 通道的 Scorpio-X 交换机或 UALink 交换机可以改善这种情况。
前两代交换机托架采用多平面扩展交换架构,理论上无法在不经过多次跳转的情况下实现机架内所有设备间的完全通信。第一代交换机很快就会被更高带宽和更高基数的交换机所取代。下表展示了两种机架 SKU 和三种不同交换机托架代数下六种不同组合的扩展特性。
交换机托架
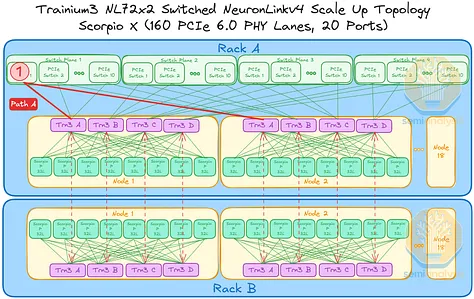
Trainium3 NL32x2 交换型交换机将首先在第一代交换机托架中使用 160 通道 PCIe 交换机来实现扩展拓扑结构。每个机架包含两个交换平面,每个平面由 8 台交换机组成。由于每台 PCIe 交换机的端口数量有限,每台 Trainium3 只能连接到同一平面上的 8 台 PCIe 交换机,而不能连接到所有其他 PCIe 交换机。因此,并非所有 Trainium3 都能直接与其他 Trainium3 通信,而是需要经过多个跃点。
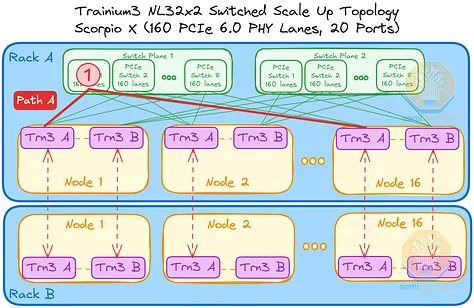
例如,节点 1 中的 Trainium3 A 可以通过一个交换机跳与所有其他节点中的 Trainium3 A 通信。节点 1 中的 Trainium3 B 也同样可以通过一个交换机跳与所有其他节点中的 Trainium3 B 通信。
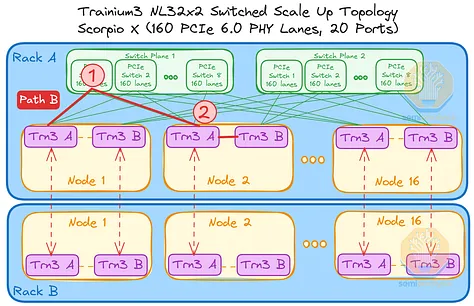
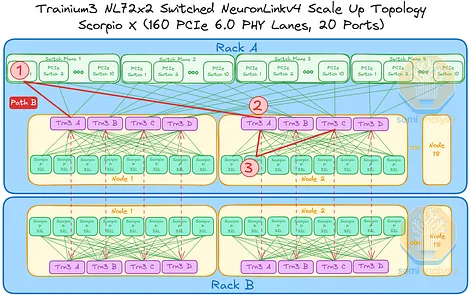
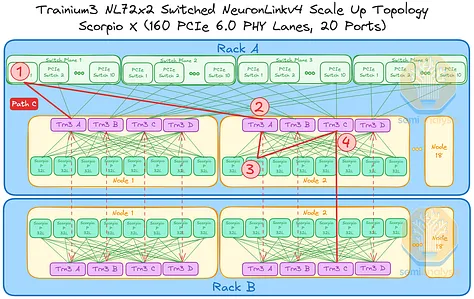
然而,考虑以下三种情况:位于不同交换平面或机架上的 Trainium 芯片进行通信。在每种情况下,数据都可以通过多条路径在两个 Trainium3 芯片之间传输,以下列出一些可能的路径:
- 路径 A:从机架 A 的节点 1 中的 Trainium3 A 到机架 A 的节点 16 中的 Trainium3 A,总共 1 跳。
- 路径 B:从机架 A 节点 1 中的 Trainium3 A 到机架 A 节点 2 中的 Trainium3 B,总共需要 2 跳。
- 路径 C:从机架 A 节点 1 中的 Trainium3 A 到机架 B 节点 2 中的 Trainium3 B,总共需要 3 跳。
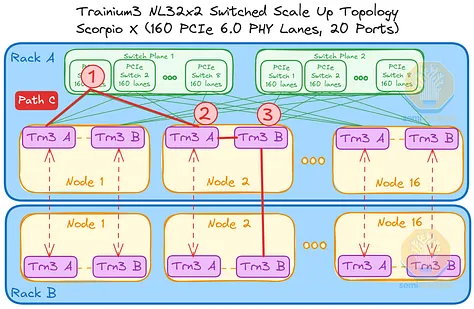
由于 Trainium3 芯片具备自动转发功能,且集合延迟基于 SBUF 到 SBUF 的数据传输,AWS 声称这种多跳传输不会造成延迟问题。我们认为,与 Nvidia GPU 相比,这种延迟可以忽略不计,因为 Nvidia GPU 的集合传输需要从 HBM 开始或结束。但最终,性能机器学习工程师需要根据纵向扩展拓扑结构,协同优化模型并行性,以尽可能减少通信跳数,同时还要考虑到跨机架连接的带宽不到机架内背板带宽的 10%。
最直接的方法是在机架内部署专家并行(EP),然后通过AEC将机架上的Trainium3实例“配对”,并在配对的机架之间使用张量并行(TP)。另一种显而易见的并行策略是,在机架内使用专家并行,并在机架对之间使用上下文并行。
另一种潜在的并行策略是在两个机架上都使用完整的EP(扩展并行),但要考虑到额外的跃点。这种策略对于非常稀疏的模型可能非常有效,因为这类模型由于d_model维度太小而无法跨机架实现TP(并行并行)。因此,即使通过直接连接的Trainium3进行额外跃点带来的延迟也是值得的。
接下来是 Trainium3 NL72x2 交换机 SKU,其扩展拓扑结构更为复杂。它包含四个平面,每个平面配备 10 个 160 通道 PCIe 交换机,每个机架的交换机托架上共有 40 个交换机;此外,18 个计算托架上每个托架还配备 8 个 32 通道 PCIe 交换机,这意味着每个机架的计算托架上总共有 144 个较小的 PCIe 交换机。因此,每个机架总共有 184 个扩展交换机,或者说,144 台 Trainium3 扩展机架共计 368 个扩展交换机。为了便于跟踪交换机配置,我们在此重现之前的汇总表:
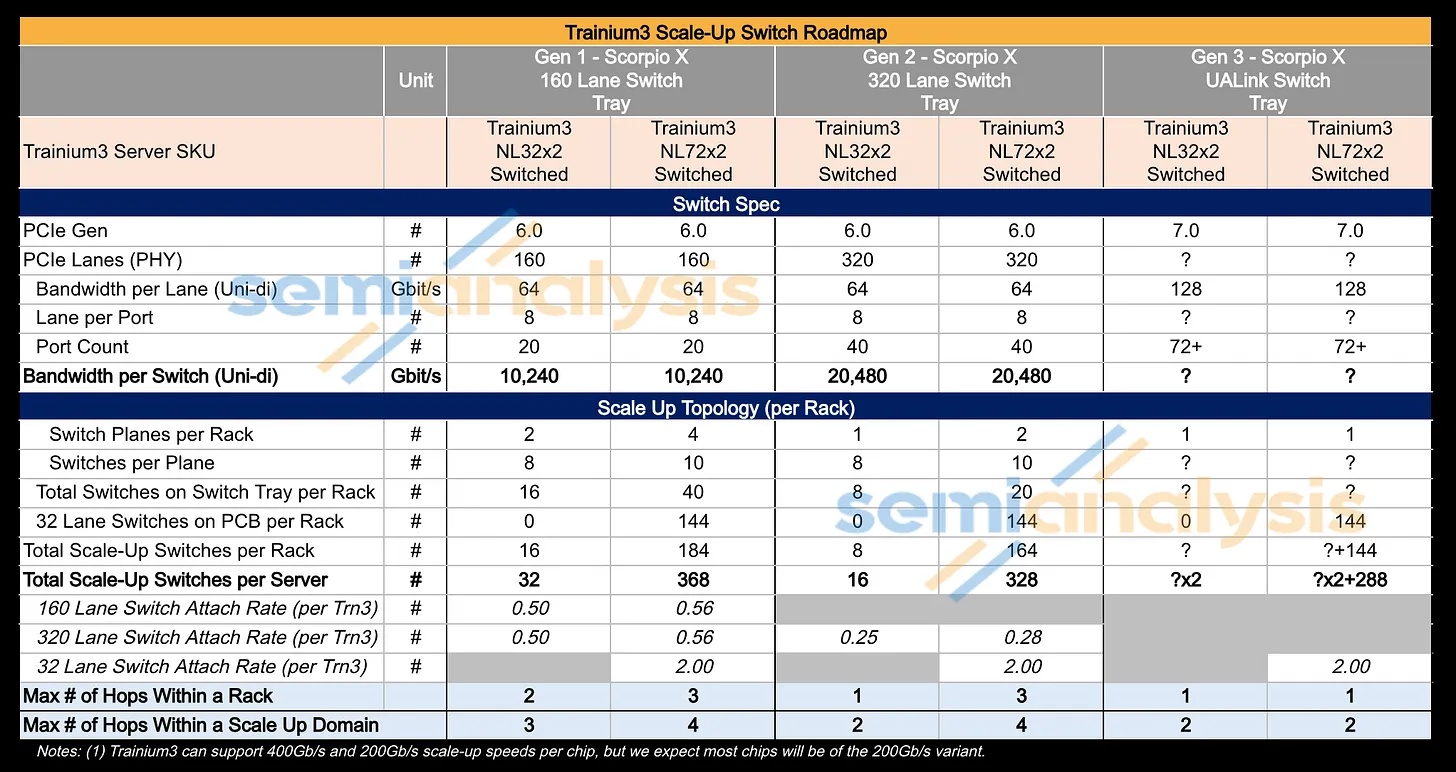
与同样在交换机托架中采用 160 通道 PCIe 交换机的 Trainium3 NL32x2 交换式设计类似,这种扩展设计也受到每个交换机托架上 PCIe 交换机仅有 20 个端口的限制,这意味着每个交换机每个节点只能连接到四个 Trainium3 芯片中的一个(这 20 个端口中有两个未使用或用于管理)。在同一交换平面内,每个 Trainium3 芯片之间仅相隔一个交换机跳数。
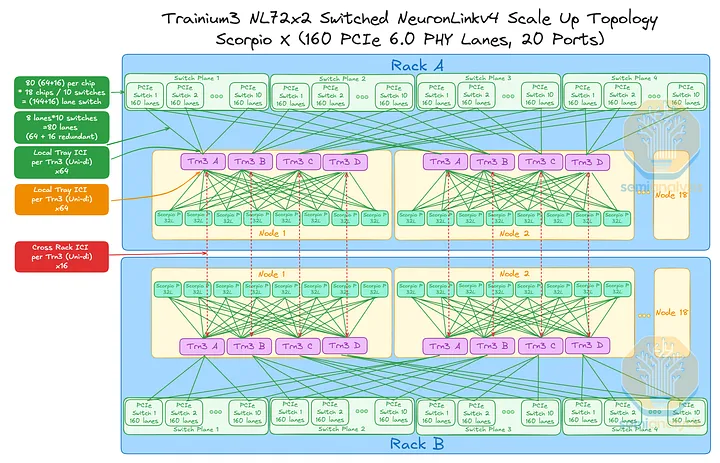
与每个 JBOG 仅包含两个 Trainium3 的 Trainium3 NL32x2 交换式设计不同,Trainium3 NL72x2 交换式设计在同一计算托架板上集成了四个 Trainium3。同一板上不同交换平面上的每个 Trainium3 芯片通过 8 个 32 通道 Scorpio-P PCIe 交换机进行通信,这意味着位于不同交换平面上的 Trainium3 芯片之间的芯片间通信需要额外的交换机跳转。
当 Trainium3 设备不在同一交换平面上时,交换跳数大于 1。请考虑以下三种不同的情况:
- 路径 A:从机架 A 的节点 1 中的 Trainium3 A 到机架 A 的节点 2 中的 Trainium3 A,总共需要 1 跳。
- 路径 B:从机架 A 节点 1 中的 Trainium3 A 到机架 A 节点 2 中的 Trainium3 C,总共需要 3 跳。
- 路径 C:从机架 A 节点 1 中的 Trainium3 A 到机架 B 节点 2 中的 Trainium3 C,总共需要 4 跳。
Trainium3 NL72x2 已开启 Gen1 备用交换机托架
AWS 也针对各种场景进行了配置。如果 Scorpio X 160 通道 PCIe 交换机不可用,则可以使用 Broadcom PEX90144 交换机作为备用方案,该交换机具有 144 条通道和 72 个最大可用端口。然而,这种具有更高基数(每个端口 2 条通道,最大端口数为 72)的替代方案并不意味着可扩展交换平面的数量会减少。
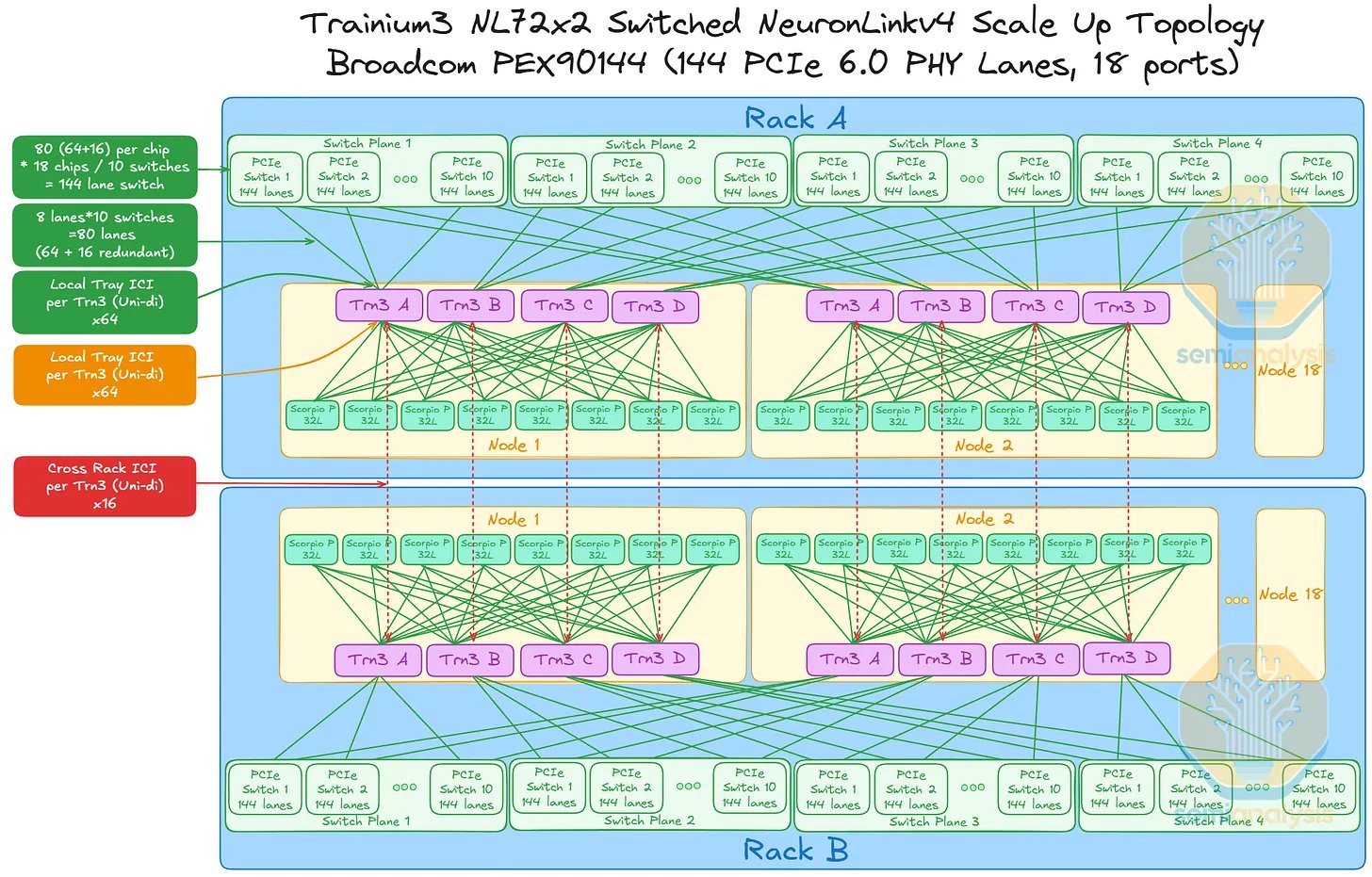
由于潜在的高串行延迟,从 Trainium3 延伸出的 ICI 通道可能不适合每个端口拆分成两条通道。这意味着,对于 144 通道的 PEX90144 扩展交换机,AWS 将使用每个交换机 36 个端口(每个端口 8 条通道)或 18 个端口(每个端口 4 条通道)作为备份。下图展示了一种这样的扩展拓扑结构,其中每个 PCIe 交换机有 18 个端口,每个端口使用 8 条通道的 PEX90144。
第二代交换机托架
Trainium3 NL32x2 交换机版 SKU 也兼容 320 通道 PCIe 扩展交换机,一旦 320 通道 PCIe 交换机上市,即可替换现有的 160 通道 PCIe 交换机。由于 320 通道 PCIe 交换机的端口数量是 160 通道交换机的两倍,因此每个机架只需 8 台交换机即可构建扩展网络,机架内的每个 Trainium 芯片之间也仅需经过一个交换机即可连接。由于扩展拓扑结构已实现全连接,PCB 上相邻 Trainium3 芯片之间的直接连接成为一项额外优势。
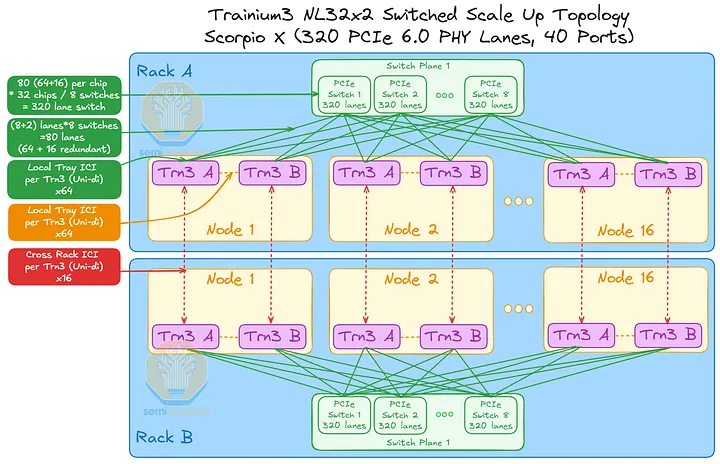
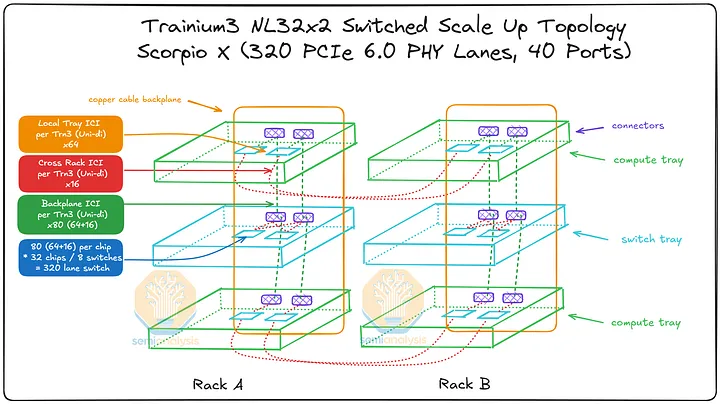
在此设计中,机架中任意 Trainium3 芯片之间的最大跳距仅为一跳——与 Trainium3 NL32x2 交换式 SKU 的 Gen1 设计最坏情况下的两跳距离相比,这是一个很大的改进,当 SKU 升级到使用 Gen2 交换机托架时,可提供延迟优势。
对于 Trainium3 NL72x2 交换式芯片,从 160 通道 Scorpio X PCIe 交换机升级到 320 通道 Scorpio X PCIe 交换机意味着交换平面数量从四个减少到两个。JBOG 托架上相邻的 Trainium3 芯片仍然需要通过 Scorpio P 交换机进行通信。

最终目标:第三代交换机托架
UALink 上线后,即可在数据中心内安装 72+ 端口的 Scorpio X UALink 交换机,替换原有的 320 通道 Scorpio X 交换机(每台交换机 40 个端口)。UALink 交换机的延迟低于基于 PCI 的交换机,并且将使用 UALink 协议。
下图展示了安装了基于 Gen3 UALink 的交换机托架的 Trainium3 NL32x2 交换式 SKU 的拓扑结构。借助 UALink 交换机,Trainium3 NL32x2 交换式 SKU 将继续支持全连接,就像 320 通道 Scorpio X PCIe 交换机一样。每个逻辑端口的具体端口数量和通道数尚未确定,但每个机架的整体扩展带宽将保持不变。
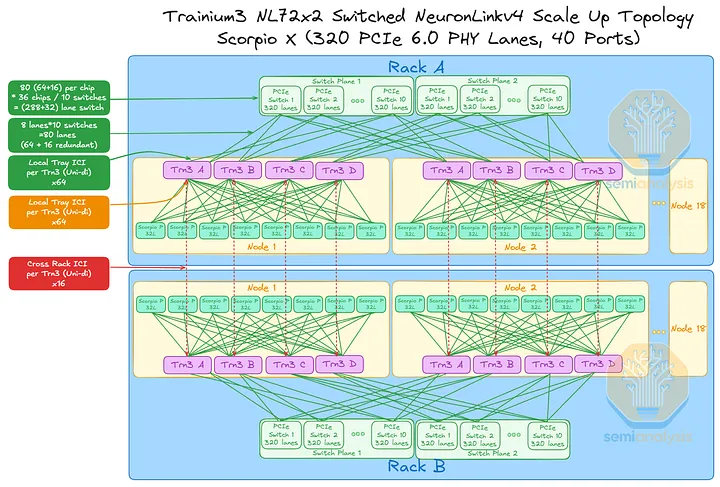
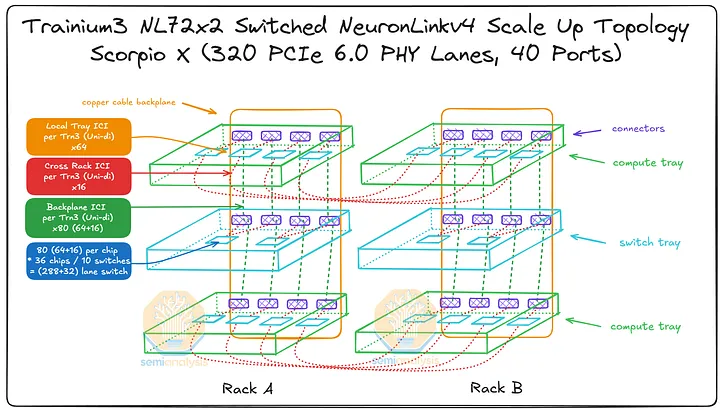
对于 Trainium3 NL72x2 交换式架构,每个机架的扩展拓扑结构将变为全连接,因为每个 UALink 交换机都可以连接到机架内的每个 Trainium3 芯片。通过 8 台 32 通道 Scorpio P 交换机实现的本地计算托架连接现在体现了剩余带宽。
所有这些加起来就意味着需要大量的 PCIe 交换机,即使只考虑一代产品也是如此!
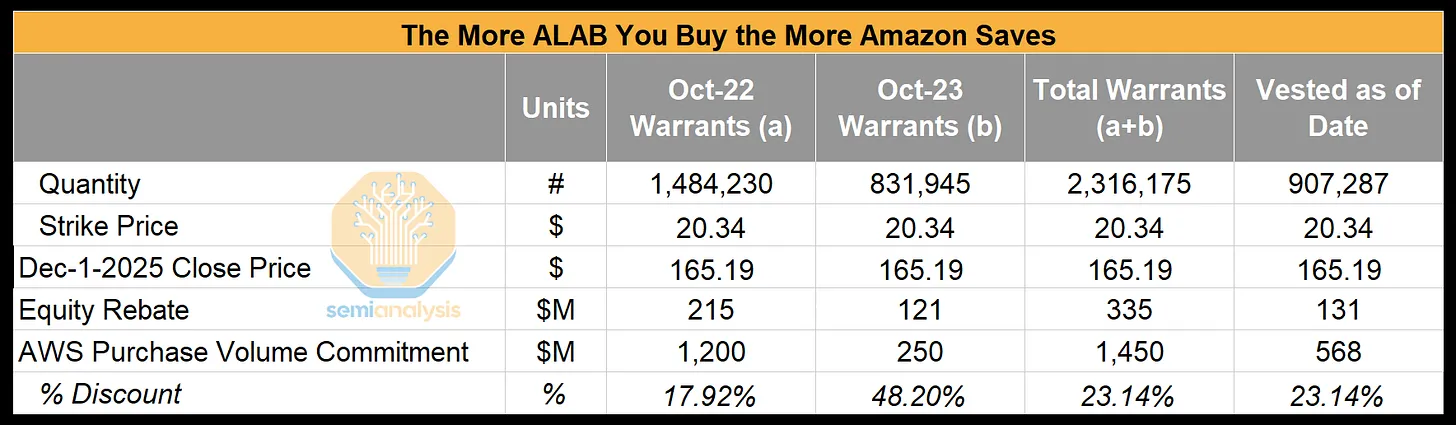
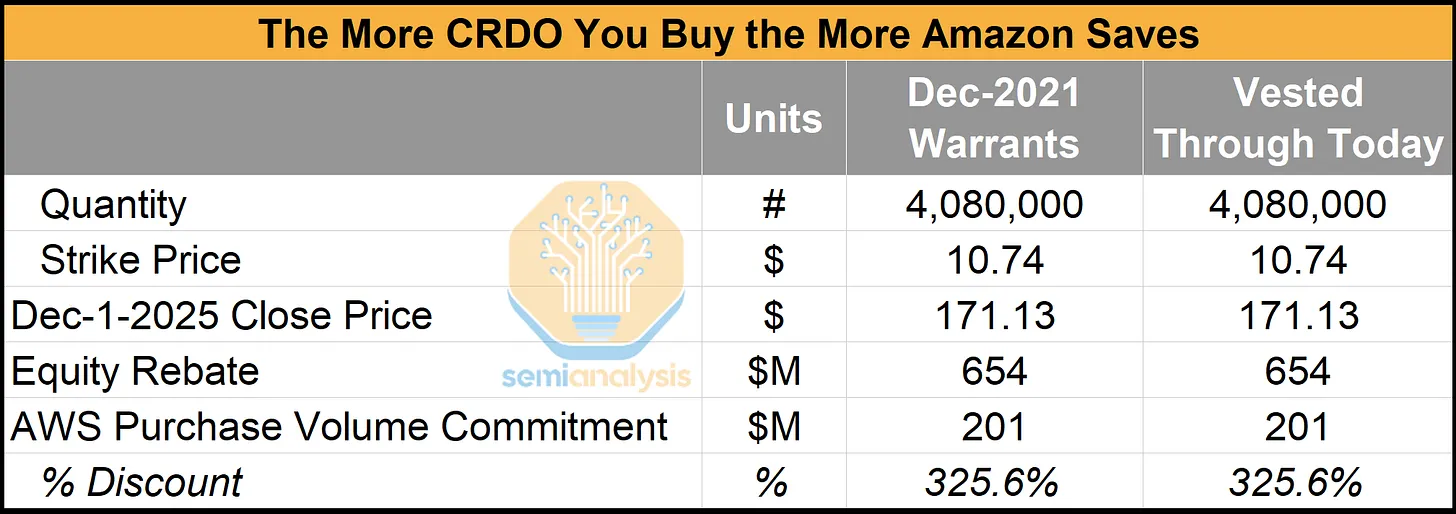
幸运的是,亚马逊与 Astera Labs 建立了战略合作伙伴关系。事实证明亚马逊购买得越多,节省得就越多!
如果 AWS 达到其对 ALAB PCIe 交换机和重定时器的采购量承诺,它将获得与这些产品采购挂钩的 ALAB 股票认股权证。这些股票认股权证会在 AWS 达到采购里程碑时逐步生效,由于行权价格仅为 20.34 美元,任何高于该价格的市场价格都会立即为 AWS 带来价值。这种结构实际上为 AWS 提供了基于股权的组件采购“返利”。在以下示例中,截至 9 月 25 日生效的股票认股权证相当于约 23% 的有效折扣。
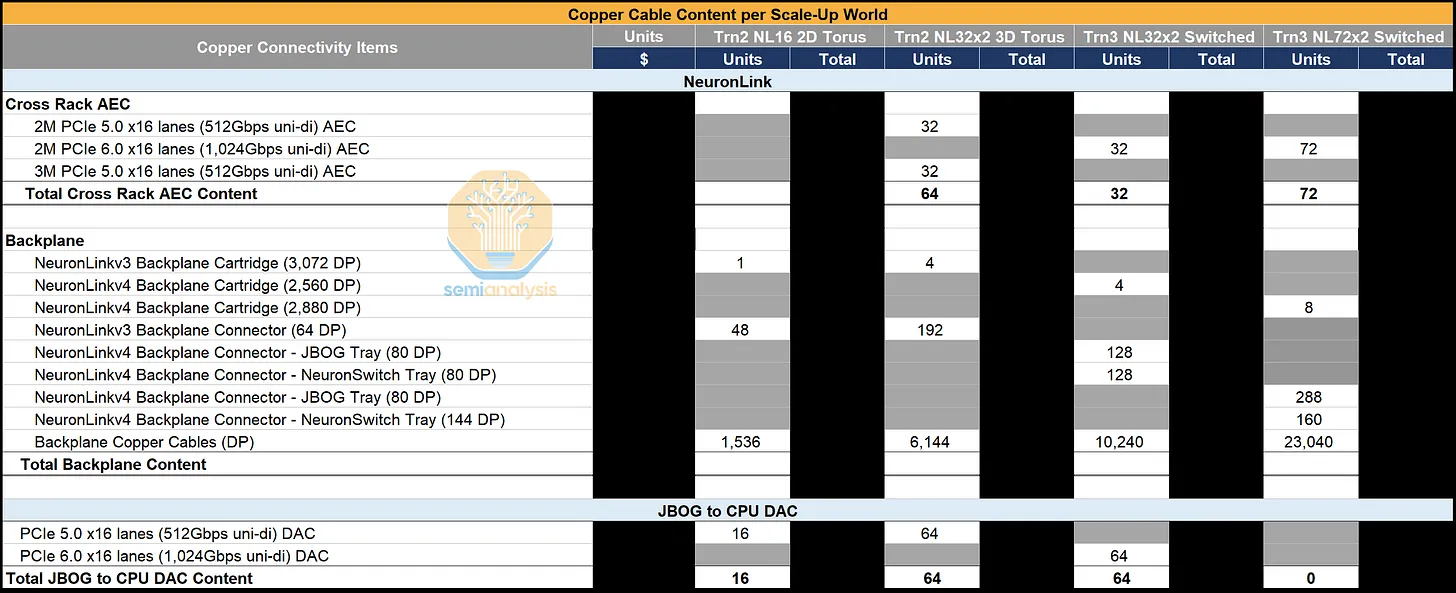
由于不同 SKU 的扩展拓扑结构(交换机或网状网络)和 NeuronLink 通道数量不同,Trainium 各代产品的铜缆数量也各不相同。Trainium2 NL16 2D Torus 采用单背板和相对较少的 AEC 链路,而 Trainium NL32x2 3D Torus 则增加了通道数量,需要四个 NeuronLink 背板以及约 6,100 根铜缆来支持更密集的 3D Torus 拓扑结构。Trainium3 NL32x2 Switched 保持了类似的背板数量和约 5,100 根铜缆,而 Trainium3 NL72x2 Switched 则进一步扩展了扩展范围,每个服务器组可容纳 144 个芯片(Trainium3 NL32x2 为 64 个),铜缆数量也因此增加到 11,520 根。
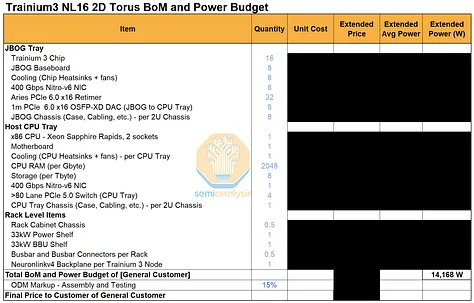
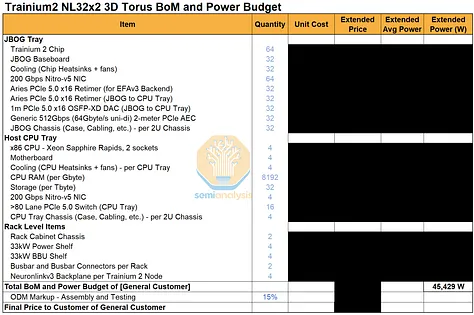
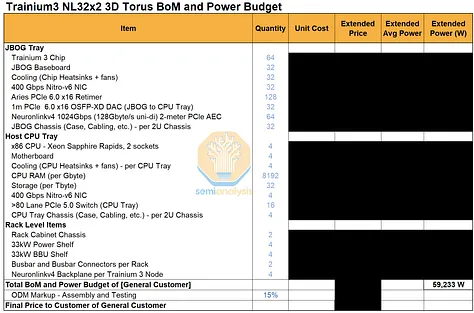
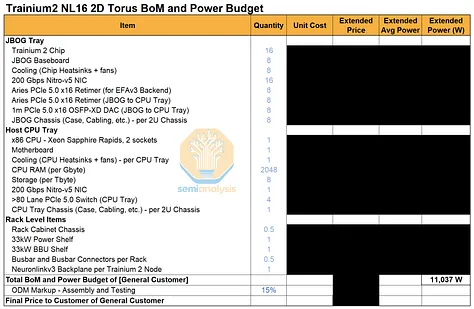
Trainium3 机架功率预算和物料清单
我们已针对不同 Trainium 系统中的主要组件组,编制了一份详细的零件清单和主要功耗预算。订阅我们AI 总拥有成本 (TCO) 模型和 AI 硬件物料清单 (BoM) 模型的用户,可以查看有关数量、平均售价 (ASP) 和系统总成本的详细信息。
Trainium3 NL72x2 开关系统的总系统功耗自然更高,因为它在两个机架上部署了 144 个芯片,而 Trainium3 NL32x2 开关系统在两个机架上仅部署了 64 个芯片。然而,一旦将功耗标准化为每个芯片的功耗,64 个芯片的 Trainium3 NL32x2 开关系统和 144 个芯片的 Trainium3 NL72x2 开关系统实际上每个芯片的功耗非常接近,因为 Trainium3 芯片的热设计功耗 (TDP) 是影响整体功耗预算的最大因素。 Trainium3 NL72x2 Switched 的机架功率密度自然更高,因为它在一个机架中可以容纳 64 个芯片,而 Trainium3 NL32x2 Switched 只能容纳 32 个芯片。
Trainium3 实现盈利的时间策略
考虑到其雄心勃勃的机架架构,AWS 在机架设计中做出了战略性决策,以优化 Trainium3 机架的货币化时间。我们相信这是 Trainium3 的一项巨大优势,部署 Trainium3 的客户将从中受益。货币化时间的优化对领先的 AI 实验室的代币经济投资回报率 (ROIC) 有着显著影响。下文我们将探讨 AWS 在 Trainium3 的设计和部署方面所做的创新和战略决策,以优化货币化时间。
在供应链方面,AWS自2024年底以来,已通过Trn2项目提升了供应链和产能一年多。尽管从晶圆厂出厂到2025年上半年机架交付之间存在较长的延迟,但我们预计机架ODM和数据中心供应链目前已做好准备,能够以更短的CoWoS到机架交付周期应对Trainium3的产能提升。我们观察到,平均交付周期已缩短至一个季度以内,并且还在持续缩短。
除了为产能爬坡做好供应链准备外,AWS 还针对 Trainium 机架架构的设计做出了多项战略决策。正如我们在文章前面提到的,Trainium 服务器采用无线缆设计理念,所有信号都通过 JBOG 或节点内的 PCB 传输,以优化组装效率。虽然通过飞线传输信号性能更佳,但线缆在组装过程中也可能成为潜在的故障点。GB200 组装的一大挑战在于内部线缆数量庞大,因此,Nvidia 实际上正在效仿 Trainium,为 Vera Rubin 平台采用无线缆计算托架设计,以提高生产效率。这种设计的缺点是需要额外的 PCIe 重定时器,但考虑到 AWS 每次购买 PCIe 重定时器时都能从 ALAB 获得有效的返利,这仍然是一个相对经济的解决方案,尤其对于 AWS 而言,能够缩短盈利时间,因此非常值得。
这种理念的另一个例子是连接到背板的扩展链路的冗余设计。如上所述,每个 Trainium3 都配备了 80 条专用于背板的 NeuronLinkv4 通道,其中 16 条通道用于冗余。这样做的目的是为了弥补背板潜在的不可靠性。鉴于英伟达 GB200 的背板可靠性较差,需要花费时间进行调试和更换,Trainium3 中设计的冗余通道有望实现热插拔扩展交换机托架,而不会中断整个机架的工作负载。
最后,AWS 灵活的硬件方案也使其能够在诸如高密度机架液冷数据中心尚未就绪和 UALink 交换机不可用等限制条件下部署 Trainium3。同时拥有风冷(Trainium NL32x2 交换式)和液冷(Trainium NL72x2 交换式)全交换式扩展机架的优势在于,即使液冷数据中心尚未准备就绪,AWS 也可以在其原有的低密度数据中心部署 Trainium NL32x2 交换式机架。这种灵活性避免了单个设施的延迟导致收入延迟,正如我们最近在 CoreWeave 的 Denton 数据中心所看到的那样。关于扩展型 Neuron 交换机,我们讨论了 AWS 计划如何部署低基数交换机以缩短产品上市时间。这再次展现了他们的灵活性和优化盈利时间的决心。
英伟达应该注意产品变现时间,因为从芯片生产到客户产生收益的变现时间,GB200 NVL72 已经延长,而 Vera Rubin Kyber 机架式显卡的变现时间还会更长。这将给 OEM/ODM 厂商和终端云平台带来巨大的营运资金压力,增加其总体拥有成本 (TCO) 并降低盈利能力。
横向扩展和横向扩展网络
理解 EFA 首先要了解弹性网络附加 (ENA)。在 AWS 中,启动虚拟机时,系统会通过 ENA 分配一定的网络容量。ENA 用于集群中的实例之间通信,以及连接到其他资源,例如 S3 和 EFS 等存储服务或负载均衡器等网络服务。ENA 还可以通过 Nitro 系统用于 EBS,并提供上行链路/广域网连接以及互联网连接。
ENA 为上述服务提供了足够的容量,但众所周知,AI 服务器需要来自无阻塞网络拓扑结构的更大容量。这就是 EFA 的作用所在。它是后端网络或“东西向”网络,而 ENA 是前端网络或“南北向”网络。
EFA 是一种网络接口,它使用自身定制的可扩展可靠数据报 (SRD) 传输层来降低延迟,并提供拥塞控制和负载均衡。这些特性对于人工智能至关重要,因为缺少这些特性,大规模通信将无法扩展。
EFA并非以太网的直接替代品,因为它构建于以太网之上,分别负责第1层(物理层)和第2层(数据链路层),但它是RoCEv2的替代方案,RoCEv2是对以太网的扩展。在许多方面,AWS声称EFA超越了RoCEv2和InfiniBand,因为它还包含许多更高层的功能。
AWS 声称 EFA 具有以下优势:
安全性:在安全特性方面,EFA 构建于亚马逊 VPC 控制平面之上,这意味着它继承了 VPC 的核心云安全特性。例如,Nitro 强制执行实例隔离,用户空间不允许一个租户访问另一个租户的内存。EFA 还使用线速加密(AES-256),这意味着流量将进行端到端完全加密。
可扩展性:SRD 发送器支持多路径并具备拥塞感知能力,它会将内存数据包分散到网络中的多条路径上,同时避开拥塞热点。AWS 声称,这种处理拥塞并利用新路径而不出现瓶颈的能力,使得 AWS 能够在无需大型缓冲区交换机的情况下,跨区域构建大型网络架构。这与 Nvidia 的 Spectrum-XGS 和 OpenAI 的 MRC 协议类似,它们也声称无需大型缓冲区交换机即可实现跨区域传输。
通用性:Libfabric 应用程序编程接口 (API) 将网卡 (NIC) 和系统参考数据 (SRD) 暴露给 MPI 实现,例如 Nvidia 集体通信库 (NCCL)。通过 Libfabric,EFA 的通用性得以提升,因为许多网卡都在开发中使用相同的 API 接口,这意味着更多网络通过 Libfabric 实现了 EFA 兼容。然而,由于 Nvidia 拥有许多常用的高级技术,这种通用性的说法在实践中并不成立。
在 AWS Nvidia GPU 上,由于用户体验持续不佳,我们仍然认为 EFA 相较于 Spectrum-X、InfiniBand 或配备 Connect-X 的 Arista 交换机,性能并无提升。然而,Trainium 的用户体验要好得多,这得益于 AWS 能够控制 Trainium 的整个堆栈。
为了支持 EFA,AWS 构建了定制的网络接口卡 (NIC)。下表显示了每一代 EFA 与特定 EC2 服务器的映射关系:
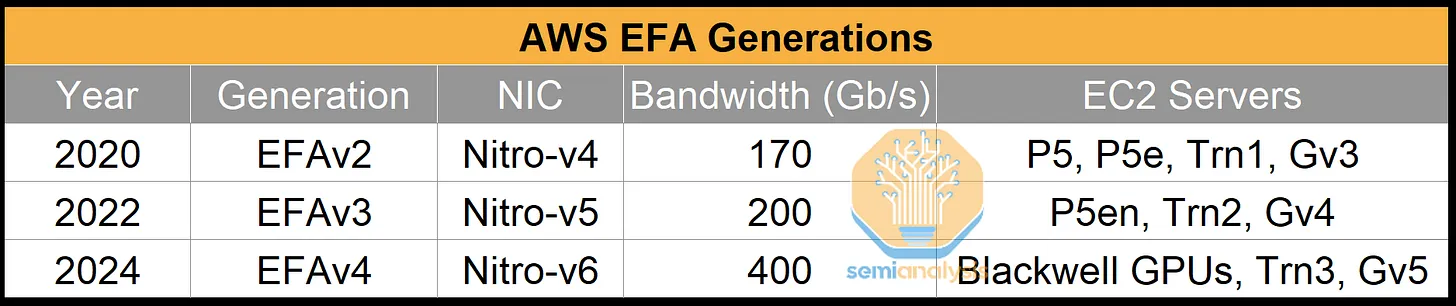
与我们之前关于 Trainium2 的说明(其中假设前端和后端网络是分开的)相反,AWS 和 Google 一样,将两种类型的流量汇聚到同一个网络上。他们通过将 Trainium 托架和 CPU 托架上的 Nitro-v6 网卡连接到同一个机架顶部 (ToR) 交换机来实现这一点。
对于 Trainium3 上的 EFAv4,有两种横向扩展网络速度可供选择:每颗 Trainium3 芯片配备一个 400G Nitro-v6 网卡,实现 400G 网络速度;或者两个 Trainium3 芯片共享一个 400G Nitro-v6 网卡;或者每颗 Trainium3 芯片实现 200G 网络速度。大多数机架将采用每颗 Trainium3 芯片 200G 的方案,我们将在下文中讨论并绘制此方案的示意图。无论采用哪种方案,Nitro-v6 网卡都将连接到两个 200G OSFP 插槽。
在每台 Trainium3 芯片支持 200G 带宽的版本中,每块 400G Nitro-v6 网卡将支持两颗 Trainium3 芯片。AWS 采用双机架顶部 (ToR) 设计,其中一块 Nitro-v6 网卡支持两条 200G 链路,分别连接到位于计算托架上方的两台 ToR 交换机。网卡端的 56G SerDes 通道通过一根带齿轮箱的 400G Y 型有源铜缆 (AEC) 转换为 ToR 端的 112G SerDes 通道,用于 Trainium 托架;而两台 CPU 托架则通过一根直连 AEC 或直接有源铜缆 (DAC) 连接到同一对 ToR 交换机。
对亚马逊来说幸运的是,由于获得了 Credo 的股票返利,他们在 AEC 方面的交易比在 PCIe 交换机和重定时器方面更划算。Credo 的股票返利结构与 AWS 与 ALAB 的交易类似,但由于 AWS 在此协议中获得的认股权证数量远高于 ALAB,且此后 Credo 的股价大幅上涨,因此实际返利金额要高得多。这意味着亚马逊获得的 Credo 认股权证的价值超过了授予这些认股权证所需的支出。Credo 实际上是付钱给亚马逊,才让亚马逊购买了 AEC!
尽管英伟达 InfiniBand 或 Spectrum Ethernet 参考网络架构采用轨道优化的 Clos 拓扑结构来减少 GPU 之间的交换机跳数,但 AWS 仍尽可能优先选择 ToR 交换机作为第一层交换层。这样,通过用铜缆代替芯片和第一层交换层之间的光纤链路,可以降低整体网络成本。此外,如果 ToR 交换机的额外上行链路端口可用于上层链路的欠载,从而实现容错、虚拟轨道或与其他服务的连接,则还能提供更多选择。AWS 认为这种权衡是值得的。
大多数Neocloud和超大规模数据中心的默认网络配置采用每个逻辑端口400G或800G的带宽,与网卡带宽相匹配。例如,Nvidia针对2000个GPU的H100集群的参考架构将使用25.6T QM9700 InfiniBand交换机,这些交换机配备64个400G的逻辑端口,与CX-7网卡提供的每个GPU 400G的带宽相匹配。交换机的带宽限制意味着,由64端口交换机构建的两层网络最多只能服务2048个GPU。
为了增加网络上的最大GPU数量,越来越多的网络采用高基数网络(即将链路拆分成更多更小的逻辑端口),这表明坚持使用较大的默认逻辑端口尺寸会浪费大量的网络优化和成本节约空间。
在微软的文章中,我们也讨论了超大规模数据中心如何在大型人工智能实验室的推动下,开始部署高基数网络。下图展示了一个例子——OpenAI 在 Oracle 的网络,该网络可以使用 100G 逻辑端口连接两层共 131,072 个 GPU。
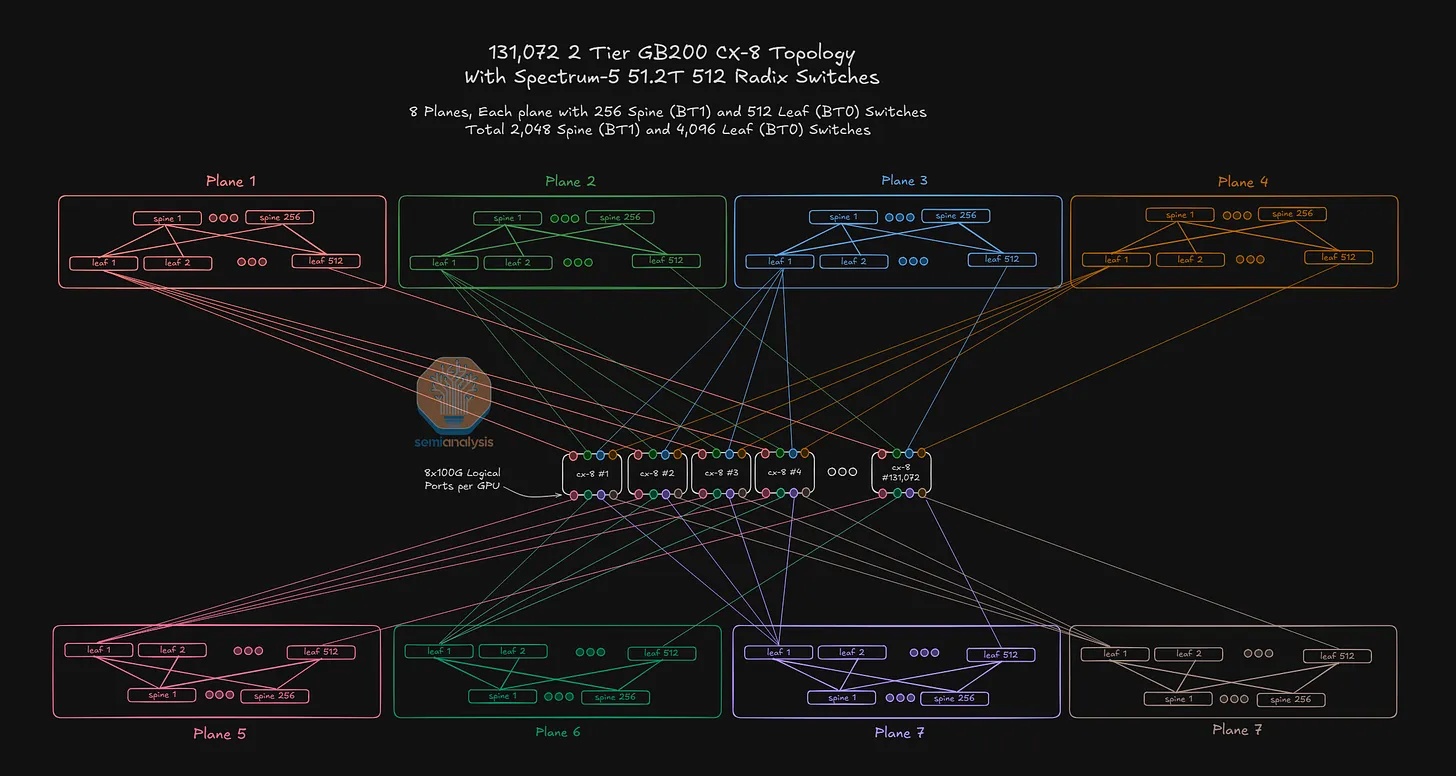
AWS 的 AI 网络方案已经直奔主题,默认使用 100G 逻辑端口。这有两个主要优势:
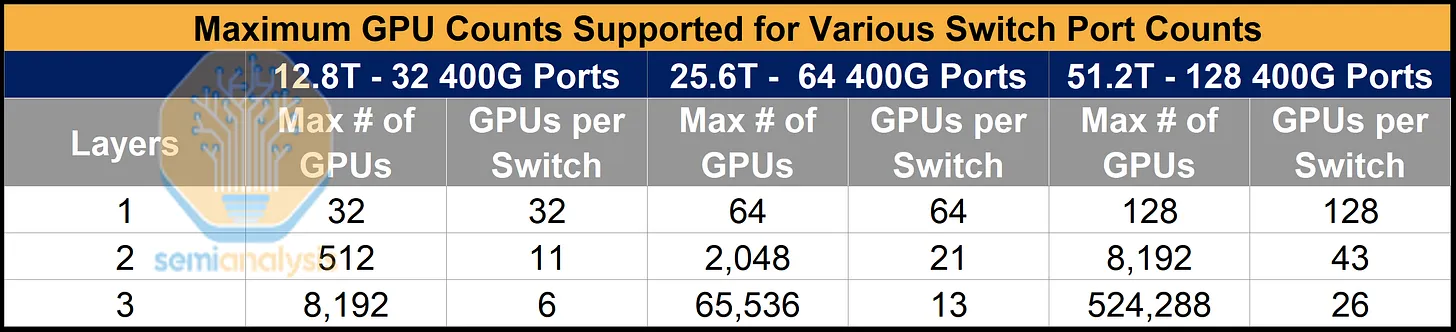
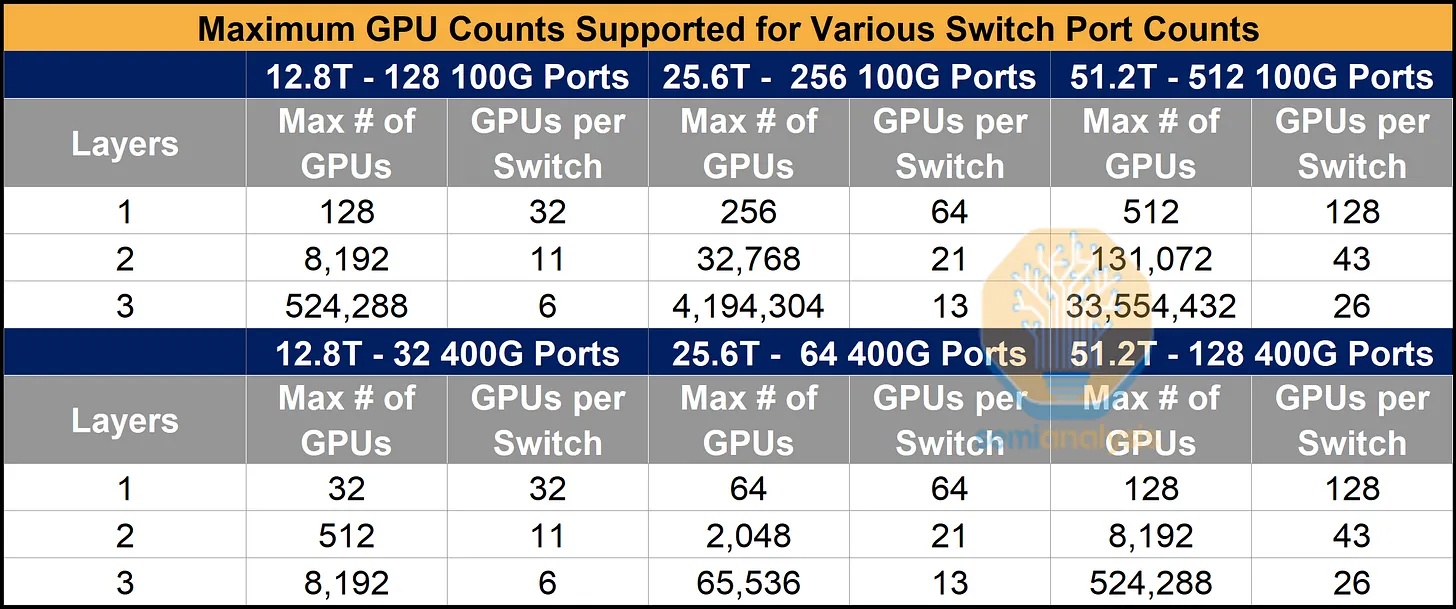
1. AWS 仅需 12.8T 交换机即可构建大型网络。
如果我们沿用传统方法,使用与GPU网卡规格相匹配的逻辑端口(通常为400G),那么仅使用12.8T交换机构建的网络规模将非常有限。对于完全由12.8T交换机组成的两层网络,我们最多只能连接512个GPU。然而,如果我们改用100G逻辑端口,两层网络可以连接8192个GPU,三层网络可以连接524288个GPU——足以满足目前最大规模的多建筑集群的需求。
来源:SemiAnalysis AI 网络模型
但为什么要用 12.8T 交换机构建网络呢?实际上,AWS 并没有这样的目标。AWS 的宗旨是最大限度地降低总体拥有成本,并围绕这一核心目标灵活调整采购决策。打个比方,对 AWS 来说,猫是黑是白并不重要,重要的是它能抓到老鼠。因此,只要能降低总体拥有成本,AWS 会选择任何交换机方案,无论是 12.8T、25.6T 还是 51.2T,亦或是 400G DR4、800G DR8 光模块。
2. 如果我们引入 25.6T 和 51.2T 交换机,AWS 仅需两层即可实现更大的规模。
按照同样的计算方法,如果AWS引入25.6T和51.2T的交换机,就能实现巨大的规模——如果我们简单地假设默认的400G或800G逻辑端口大小,那么实际规模会被低估。下表显示,对于双层网络,在51.2T交换机上使用100G端口可以连接的GPU数量是使用400G端口的16倍。对于三层网络,这个比例会扩展到GPU数量的64倍。
使用 100G 端口的缺点在于连接极其复杂——运营商通常需要使用配线架、跳线板或笨重的八爪鱼线缆才能将这些 100G 链路路由到正确的目的地,而且对布线错误的容忍度很低。亚马逊则使用定制的光纤网络 ViaPhoton 来支持这种布线,从而最大限度地降低了这种复杂性带来的影响。
Trainium3 横向扩展网络
每个 Trainium pod 内的 ToR 交换机在叶层和脊层被分割成多个平面,并针对特定网络进行了优化。所有 Trainium pod(均为独立的可扩展单元)均通过脊层连接。在下图所示的示例中,我们假设在一个三层网络中,每个平面上配备 12.8T 带宽的交换机,并以此为基础计算最大集群规模。
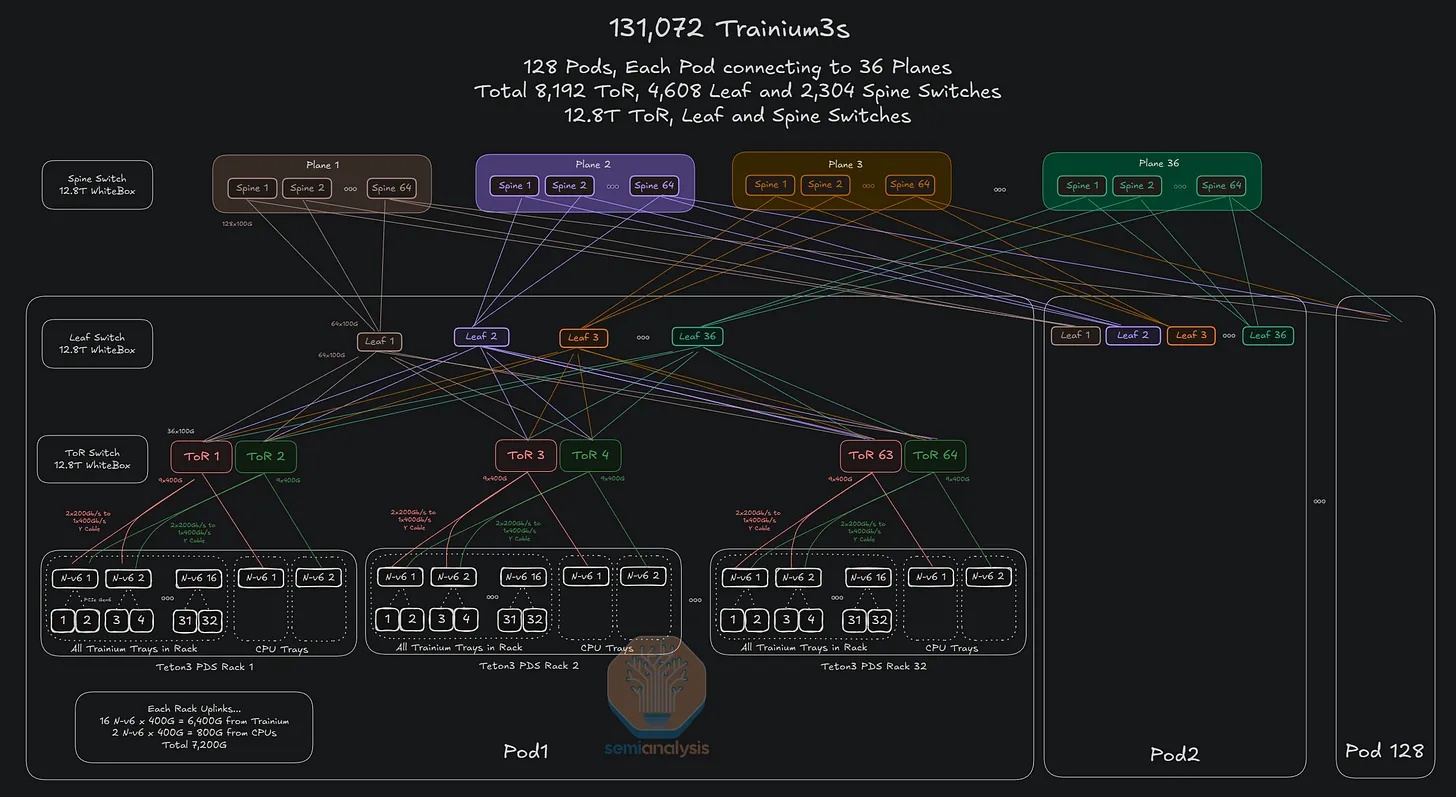
将叶脊层交换机替换为 25.6T 交换机,而非 12.8T 交换机,意味着在相同的三层网络中可支持的 Trainium3 芯片数量将增加 4 倍,同时 pod 数量和每个 pod 的机架数量也将翻倍。如果将叶脊层交换机升级到 51.2T,则该网络中的芯片数量将再次增加四倍。
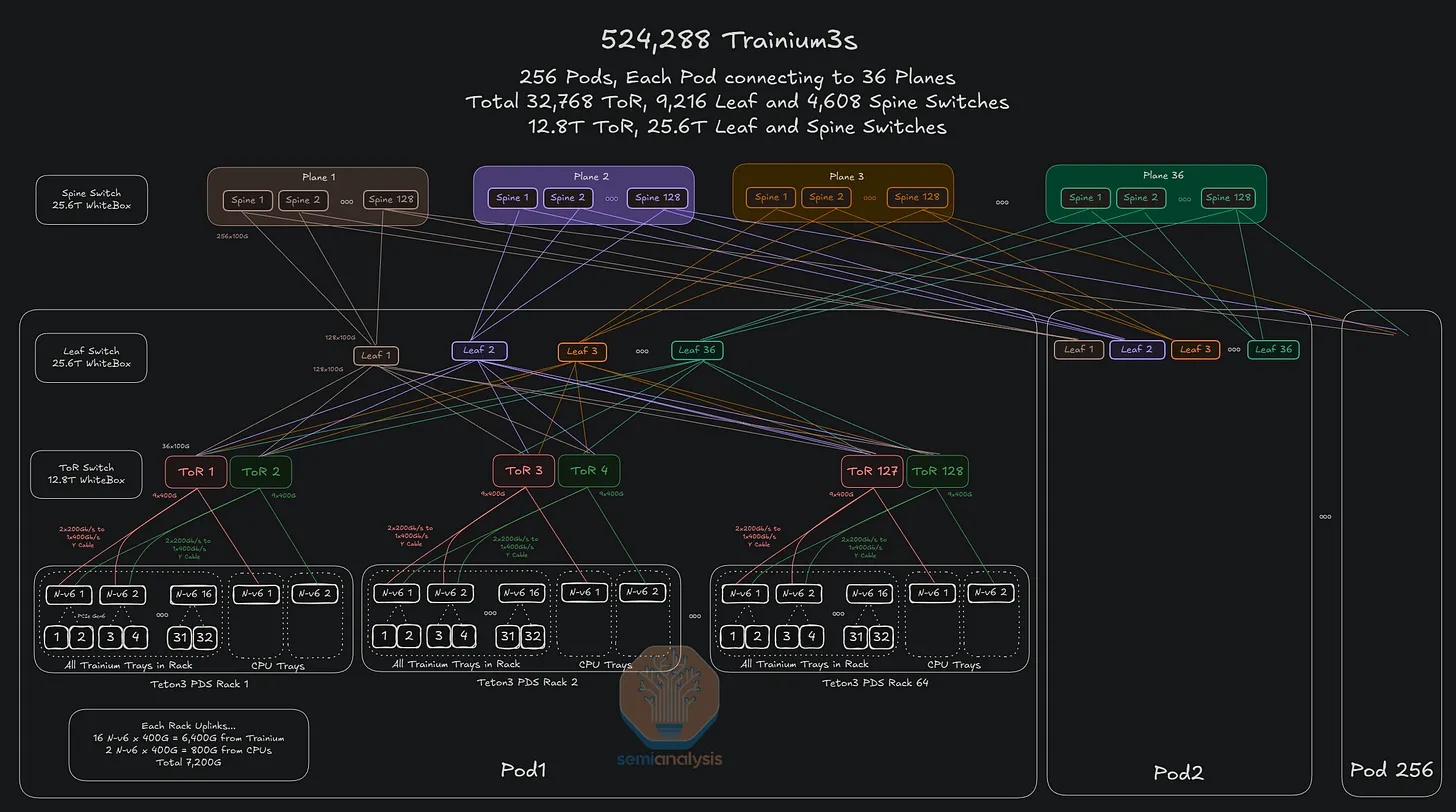
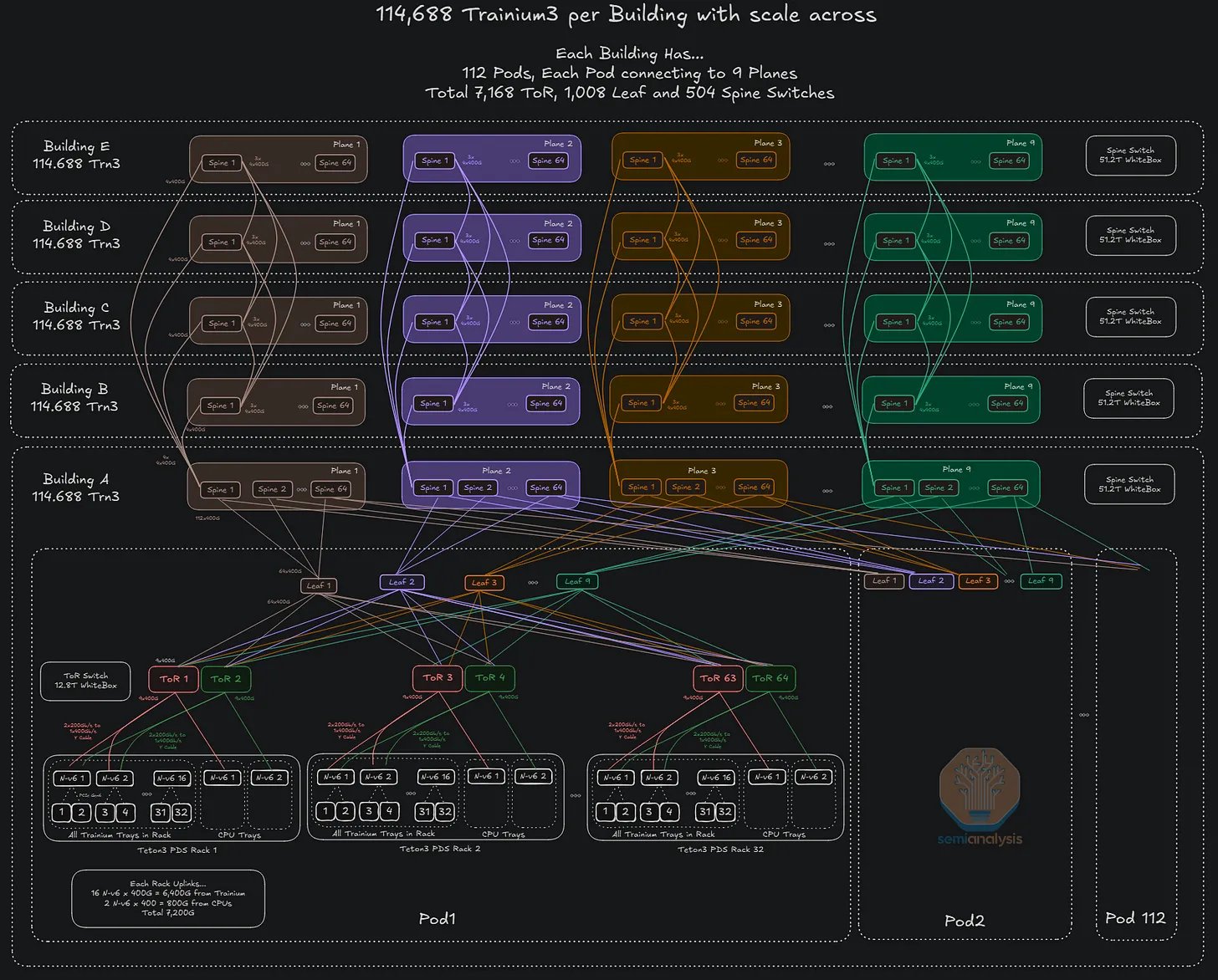
这种横向扩展网络可以跨越多栋建筑物。FR 光模块可用于几公里的距离,而 ZR 光模块可用于数百公里的距离。秉承让网卡和网络架构管理长距离传输带来的延迟的理念,AWS 将放弃使用深度缓冲交换机,直接将不同建筑物的骨干层连接在一起。
确切的跨尺度拓扑结构尚不清楚——但下图表示了一种已用于各种超大规模数据中心之间跨尺度扩展的拓扑结构。
最后,在横向扩展网络设备采购方面,由于 OpenAI 在 AWS 上的集群完全没有使用 EFA,许多人对 AWS 为 Trainium 使用的网络架构感到困惑。相反,该集群使用 GB300 交换机,并运行 CX-8 协议,该协议运行 OpenAI 的自定义协议 MultiPath Reliable Connection (MRC)。OpenAI 甚至可能使用 OCS 来连接不同的集群。这可能导致整个供应链对 AWS 的网络构建方式产生一些困惑,我们希望本节内容能够帮助那些有兴趣了解其核心原理的人厘清思路。
Trainium3 微架构
Trainium3 采用了与 Trainium2 和 Google 的 TPU 类似的设计思路,芯片由少量的大型 NeuronCore 构成。这与 Nvidia 和 AMD 等 GPU 架构形成鲜明对比,后者通常使用大量较小的 Tensor Core。大型核心通常更适合 GenAI 工作负载,因为它们的控制开销更小。与 Trainium2 一样,Trainium3 每个封装包含 8 个 NeuronCore,每个 NeuronCore 包含以下四个引擎:
- 张量引擎
- 矢量引擎
- 标量引擎
- GPSIMD
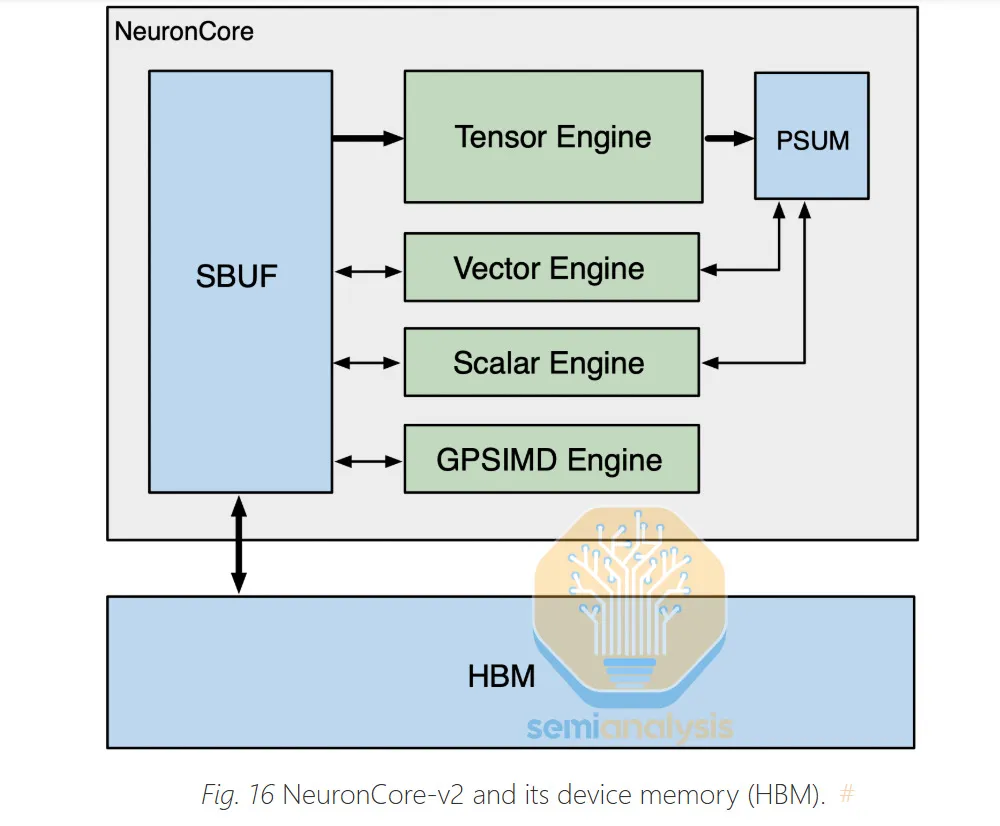
来源:AWS
张量引擎
张量引擎采用 128x128 BF16 脉动阵列和 512x128 MXFP8/MXFP4 脉动阵列。Trainium3 上的 BF16 脉动阵列大小与 Trn2 的 BF16 阵列大小相同,但在 FP8 平台上,其大小是 Trnium2 的两倍。
脉动阵列从名为“SBUF”的SRAM缓冲区获取输入,并将结果输出到名为“PSUM”的部分和SRAM缓冲区。张量引擎可以遍历矩阵乘法(matmul)的K维,并将每个结果的部分和相加,从而得到最终结果。现代LLM工作负载中超过80%的算力和浮点运算能力(FLOPS)都将用于张量引擎/脉动阵列。张量引擎还支持MXFP8 4:8和4:16结构化稀疏性,其浮点运算能力是同等稠密模式的4倍,但我们怀疑会有客户使用此功能。
MXFP4/MXFP8 的 512x128 脉动数组也可以拆分成 4 个 (128x128) 脉动数组,这样每个周期就可以将四个结果推送到 PSUM 缓冲区。在某些 GEMM 指令集中,有一些优化方法可以使 4 个 (128x128) 脉动数组在更高的 MFU 下获得比使用 512x128 脉动数组指令集更好的性能。
通常情况下,即使对于 BF16/MFP8,GEMM 也完全以 FP32 格式累加(在 Nvidia Hopper 中仅为 FP22),但某些工作负载可以容忍略低的累加精度。对于 Trainium3 张量引擎,可以选择以 FP32 格式累加 128 个元素,然后在最后将其向下转换为 BF16 格式。
张量引擎支持的数字格式和每瓦性能优化
Trainium3 团队通过专注于提升 MXFP8 的性能,同时保持 BF16 的性能不变,并结合其他物理优化措施(例如采用 3nm 工艺、优化布局设计以及使用定制单元库),在相同的芯片面积和功耗预算下实现了 MXFP8 性能翻倍。为了获得更高的 MXFP8 每瓦 FLOPS,他们还采用了与 Trn2 相比更新的垂直供电系统。许多关键的物理设计工作都是在内部完成的,而不是外包给供应商。为了将通常精度较高的主权重转换为精度较低的计算权重,Trainium3 在芯片中集成了硬件加速单元,用于加速 MXFP8/MXFP4 的量化/去量化。
遗憾的是,只专注于 MXFP8 的弊端在于 BF16 的性能并没有提升。像 Anthropic 这样的高级 L337 用户不需要 BF16 进行训练,他们具备使用 MXFP8 进行训练的技能,但普通机器学习训练师只知道如何使用 BF16 进行训练。
此外,Trainium3 的 MXFP4 性能与 MXFP8 相同,但与 AMD/Nvidia 的 GPU 相比,它在推理方面优化得不够好,因为它们能够以略低的质量换取更快的推理速度。
然而,对于推理解码等内存密集型工作负载而言,这一点影响不大,因为亚马逊/Anthropic 可以将权重存储在自定义的 4 位块大小的存储格式中,同时使用 MXFP8 进行计算。这种技术通常被称为 W4A8。对于内存密集型操作,使用 W4A8 可以实现从 HBM 加载和存储数据的速度提升一倍,因为从 HBM 到芯片的传输将以 4 位而非 8 位进行,并且在输入到张量引擎之前会在芯片上进行反量化。
此外,Trainium3 不支持 NVFP4(块大小 16,块缩放格式 E4M3),仅硬件支持 OCP MXFP4(块大小 32,块缩放格式 E8M0)。这意味着与 Nvidia GPU 相比,Trainium3需要更高级的 QAT/PTQ 技术。E8M0 块缩放比 E4M3 块缩放更差的原因在于,E8M0 会将缩放因子精确到最近的 2^n,从而导致更严重的量化误差。虽然 Trainium3 在技术上支持 NVFP4 作为存储格式(或任何 4 位任意存储格式),并且可以支持在线解量化到 OCP MXFP8,但它本身并不提供硬件加速的 NVFP4 到 OCP MXFP8 解量化支持,必须通过软件驱动的方式实现。
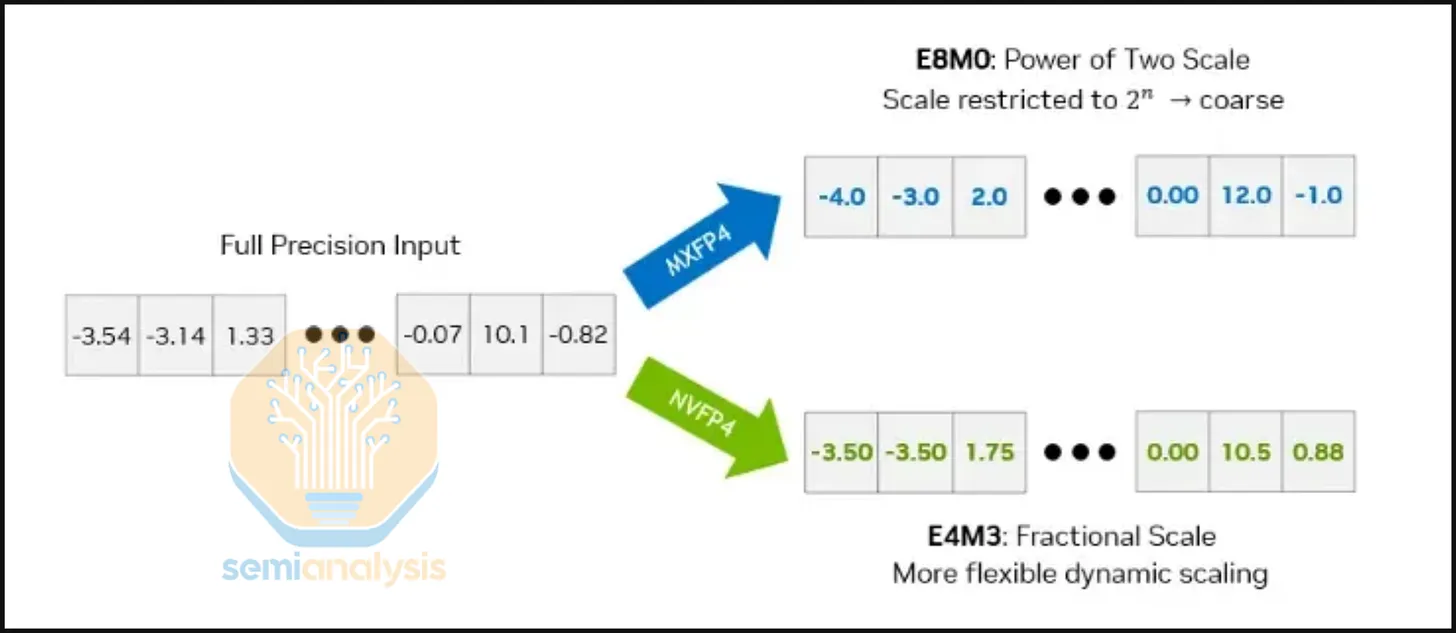
Trainium3 不支持 NVFP4 使得 4 位训练变得更加困难。英伟达研究院(以及英伟达市场部)最近发布了一篇关于 NVFP4 训练的研究论文,其中展示了一种实验性的训练方案,该方案在前向传播和反向传播中都使用了 4 位浮点运算。我们认为,在未来 12 个月内,西方前沿实验室不太可能在前向传播和反向传播中都采用 4 位浮点训练,但我们认为,随着训练方案的成熟,他们最终可能会转向 4 位训练。
尽管如此,一些西方前沿实验室已经在前向训练阶段采用了NVFP4格式,但反向训练阶段目前仍使用更高精度的数字格式,而且这种方法似乎效果良好,没有造成明显的质量损失。一些使用4位浮点数进行前向训练的前沿实验室已经将这些模型部署到生产环境中,拥有数百万活跃用户。
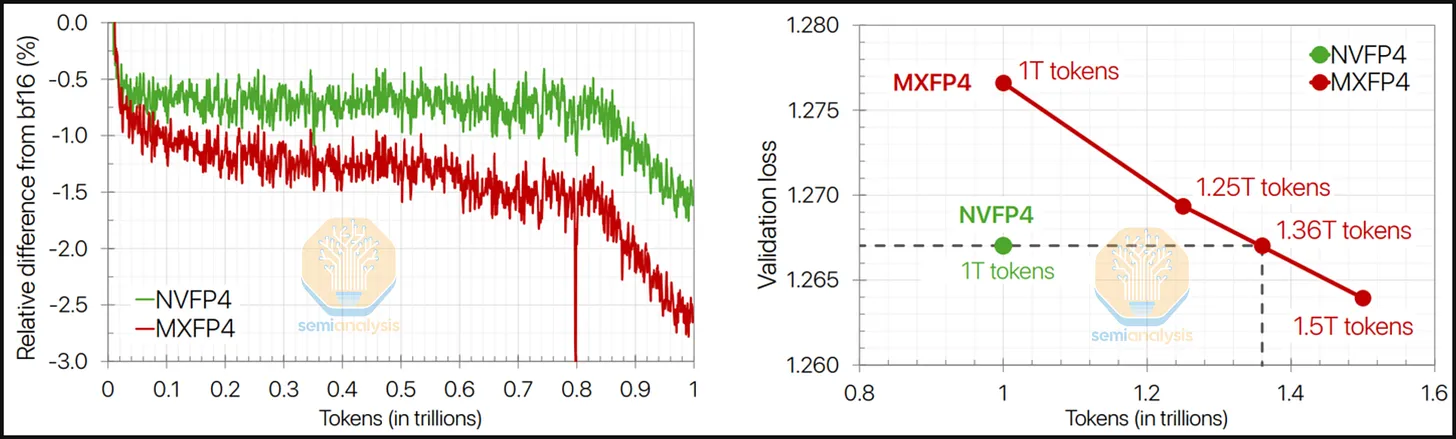
AWS Trainium3 的缺点是,如果 4 位前向传播训练继续在高级用户中得到广泛应用,那么 Trainium3 可能由于不支持 NVFP4(块大小 16,块缩放格式 E8M0)并且仅启用与 OCP MXFP8 相同的 OCP MXFP4(块大小 32,块缩放格式 E4M3)计算能力而表现不佳。
本文转自媒体报道或网络平台,系作者个人立场或观点。我方转载仅为分享,不代表我方赞成或认同。若来源标注错误或侵犯了您的合法权益,请及时联系客服,我们作为中立的平台服务者将及时更正、删除或依法处理。




{kind=link}
联系电话:
010-61853490
新闻投稿:
server@icviews.cn
商务合作:
business@icviews.cn
问题反馈:
19800315212(微信同号)


半导纵横公众号

半导纵横小程序