高通如何抢占数据中心市场?
早在 2017 年,高通就推出了一款名为“Amberwing” Centriq 2400 的 Arm 服务器 CPU 。这是一款 48 核芯片,与当时的“Broadwell”和“Skylake” Xeon SP 相比表现相当不错。有传言称谷歌是 Centriq 项目的支持者,不知出于什么原因,当谷歌没有大量购买 Centriq 时,高通在 2018 年 5 月加大了服务器 CPU 项目的投入。2021 年 1 月,高通收购了 Arm 服务器芯片设计公司 Nuvia,但高通不是为了做服务器,而是为了获得其“Phoenix”内核,也就是现在的 Oryon 内核,与高通自己设计的骁龙内核形成对比。
高通在 5 月份与 Humain 联合发布的公告中明确表示,它正在再次开发数据中心服务器 CPU。高通的声明称,AI 250“将首次搭载基于近内存计算的创新内存架构,通过提供超过10倍的有效内存带宽和更低的功耗,为AI推理工作负载带来效率和性能的跨越式提升。”
高通表示,它已赢得 200 兆瓦的部署订单。如果一张 AI 200 Ultra 卡配备四个 SoC,其功耗为 250 瓦,那么需要 80 万张卡。
高通希望每个机架提供 160 千瓦的功率,因此假设 AI 200 Ultra 卡的功耗为该功率的 80%,即 128 千瓦。这意味着每个机架可容纳 512 台设备,总共需要 1250 个机架。如果每张卡的成本为 4000 美元,那么总成本为 32 亿美元,此外可能还需要 20 亿美元用于机架及其冷却、网络和存储。即每机架 520 万美元,如果高通公司摆脱张量核心上的整数运算,只进行浮点运算,并将张量核心上的精度降低到 FP4,那么机架中 320 万美元的计算能力将达到 983 petaflops,即每 petaflops 2,604 美元,每千瓦每 petaflops 16.30 美元。
Nvidia B300 NVL72 每机架成本是多少?其功耗在 120 千瓦到 145 千瓦之间,具体取决于询问对象和具体条件。不包括存储,仅包括扩展网络和主机计算。GB300 NVL72 机架在 FP4 精度下可执行每秒 1100 千万亿次浮点运算(真正针对推理而非训练进行调整),成本约为 40 亿美元。按照每机架 145 千瓦计算,每千万亿次浮点运算的成本为 3636 美元,每千瓦功耗为 25.08 美元。这比高通的每瓦功耗高出约 35%。
如果AI 200 Ultra 的单价为 6,150 美元,那么 GB300 机架式处理器和 AI 200 Ultra 机架式处理器的每瓦性能相同。高通可以根据市场情况在此基础上进一步降价,甚至可能由于供应短缺和希望拥有多家供应商而根本不需要大幅降价。
在沙特阿拉伯利雅得举行的未来投资倡议2025大会期间,Humain与高通从谅解备忘录正式签署,并宣布两款未来AI加速器正在开发中,Humain是其首家客户。与博通至少拥有两家XPU客户一样,高通也为Humain提供完整的机架式系统,而不仅仅是芯片,后者需要将芯片提供给广达、富士康、英维思、捷普、天弘或WiWynn等原始设计制造商,
由后者将其转化为服务器并集群化成系统。
尽管因为沙特阿拉伯的Humain AI初创公司已成为高通数据中心AI雄心的“金主”,投资界对此充满信心。但高通缺乏的是能够大幅蚕食英伟达AI推理工作负载的技术。同时,高通还没有在AI训练领域与英伟达抗衡的产品;而推理是英伟达产品重要的收入来源。
高通最初的 AI 100 XPU 早在 2019 年就已发布,并于 2021 年上半年某个时候发货。但唯一一次公开它们是在晶圆级系统供应商 Cerebras Systems 调整其软件堆栈以进行推理之前。
在 2024 年 3 月,当 WS-3 计算引擎及其 CS-3 系统首次亮相时,Cerebras 将推理任务转移到高通的 AI 100 加速器机架上,以比当时使用自己的系统更便宜的方式进行推理。到2024年 9 月,Cerebras 已经调整了其软件以运行推理工作负载,之后AI 100 XPU 就没有了后续。
高通早在2021年9月就发布了一系列关于AI 100加速器的基准测试,测试结果表明这些设备在ResNet-50图像处理测试中与低端和高端Nvidia“Ampere”GPU以及其他适合边缘计算的推理引擎不相上下。与Nvidia A100 GPU相比,AI 100在每秒每瓦推理性能方面表现尤为出色。
随着生成式AI的出现,推理技术已经取得了长足进步,计算负载也随之大幅提升。与此同时,人们也渴望找到一种更经济的替代方案去替代在 Nvidia 机架式 CPU-GPU 混合处理器上运行推理。
2024 年 10 月,高通开始发售 AI 100 的低配版,称为 AI 80,同时还打造了一款 PCI-Express 卡,将四块 AI 100 芯片互连在一个封装中,称为 AI 100 Ultra。(此外还增加了 AI 80 卡的 Ultra 版本。)高通还开始提高 XPU 上 SRAM 的良率,并将容量从每芯片 126 MB 提升到每芯片 144 MB。
加州大学圣地亚哥分校的研究人员对 AI 100 Ultra 进行了基准测试,并与搭载 4 个和 8 个 A100 GPU 的系统进行了对比,结果显示高通 XPU 表现出色。在 GPT-2 和 Granite 3.2 测试中,4 个 A100 的单位功耗比搭载 4 个高通芯片的单个 AI 100 Ultra 降低了 60%,而 A100 在 Neomtron-70B 型号上的表现略胜一筹。但除此之外,相同数量的高通显卡比相同数量的英伟达显卡的单位功耗表现更佳。
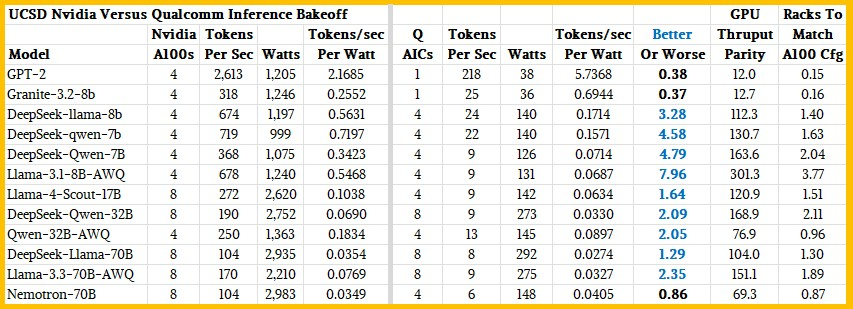
论文中没有提到计算密度和达到给定吞吐量所需的设备数量。本文计算了需要多少个 AIC(高通有时将其称为卡)才能匹配四个或八个 A100 的性能。
假设可以将 16 个 AIC 卡放入一个 5U 服务器中(这个密度相当高),那么在 AI 100 Ultra 在效率上击败 GPU 的领域,需要一到四个高通加速器机架才能匹配四个或八个 A100 GPU 的性能。要匹配精度更低的 Nvidia “Hopper” H100 或 H200 或 “Blackwell” B100、B200 或 B300 GPU 的性能,分别需要 2 倍或 4 倍到 6 倍的机架数量。
下表比较了高通AI XPU 的五种现有版本以及对未来 AI 200 和 AI 250 加速器的 Ultra 版本的估计,这些数据是在与 Humain 交易的一部分发布的:
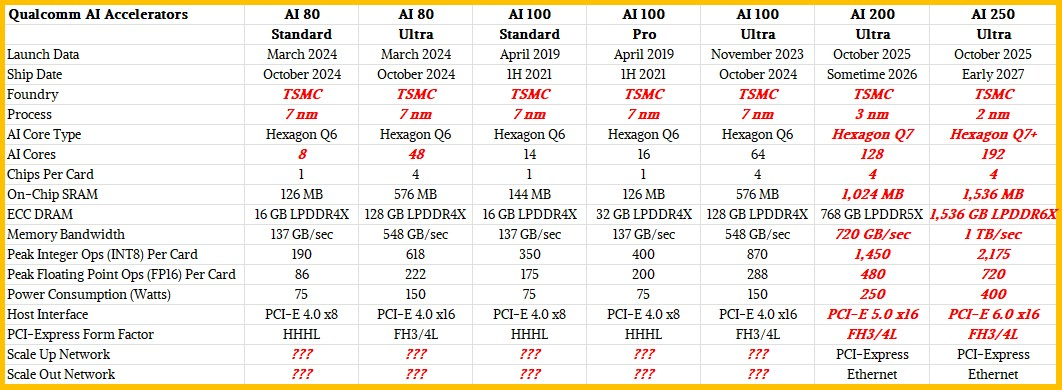
AI 200 将于明年上市,Humain 是其主要客户,它将配备 768GB 的 LPDDR5 主内存,并使用 PCI-Express 实现机架内扩展网络,并使用以太网实现跨机架扩展。
AI 100 系列芯片支持 FP16 浮点和 INT8 整数处理,其性能与 AI 100 卡的性能以及板级 SRAM 和主内存的芯片数量和 AI 核心数量相关。AI 100 架构基于高通智能手机 CPU 中的 Hexagon 神经网络处理器 (NNP),在某些 Linux 文档中也称为 Q6。
高通AI架构
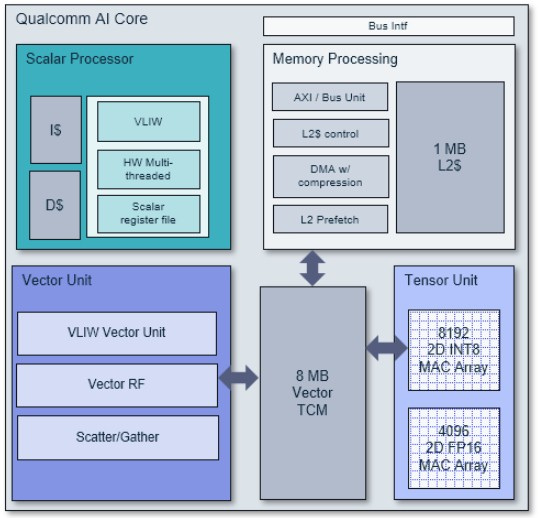
高通 AI 核心架构图
该架构在同一核心上集成了标量单元、矢量单元和张量单元。它代表了高通为其智能手机开发的第七代神经网络处理器。标量芯片采用四路 VLIW 设置,拥有六个硬件线程;它拥有超过 1,800 条指令。标量电路具有指令和数据缓存,尽管图中没有显示,但标量单元和内存子系统之间存在连接,标量单元通过内存子系统将工作卸载到核心上的矢量单元和张量单元。该内存子系统拥有一个 1 MB 的 L2 缓存,该缓存将数据输入到由矢量单元和张量单元共享的 8 MB 暂存器中。
张量单元拥有超过 125 条适用于 AI 运算的指令,并拥有一个 8,192 个 2D 乘法累加器 (MAC) 阵列用于执行 INT8 运算,以及另一个 4,096 个 2D MAC 阵列用于执行 FP16 运算。这些张量扩展被称为 HMX,即六边形矩阵扩展 (Hexagon Matrix Extensions)。
矢量单元具有用于分散/聚集集体操作的加速器,并拥有超过 700 条用于人工智能、图像处理和其他内容操作功能的指令。它支持 8 位或 16 位整数运算以及 16 位或 32 位浮点运算。在 8 位整数模式下,该矢量单元每时钟可执行 512 次 MAC 运算;在 16 位浮点模式下,每时钟可执行 256 次 MAC 运算。这显然只是张量单元吞吐量的一部分,但有些算法需要矢量单元,而不是张量单元。矢量指令统称为 HVX,简称六边形矢量扩展。
如果将 16 个 AI 核心放在一个芯片上并在其周围包裹四个 LPDDR4X 内存控制器以及一个具有 8 个 I/O 通道以链接到主机系统的 PCI-Express 4.0 控制器时,AI 100 SoC 的外观如下:
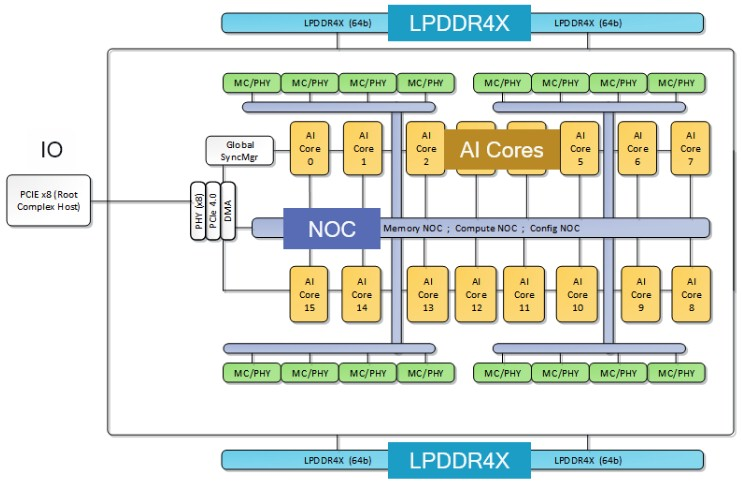
可以合理地假设,高通将发布具有更多指令和其他内容的 Hexagon 7 架构,并且它将通过 AI 200 这一代增加 SoC 上的 AI 核心数量。
本文转自媒体报道或网络平台,系作者个人立场或观点。我方转载仅为分享,不代表我方赞成或认同。若来源标注错误或侵犯了您的合法权益,请及时联系客服,我们作为中立的平台服务者将及时更正、删除或依法处理。

联系电话:
010-61853490
新闻投稿:
server@icviews.cn
商务合作:
business@icviews.cn
问题反馈:
19800315212(微信同号)


半导纵横公众号

半导纵横小程序