利用3D堆叠内存计算攻克 AI“记忆墙”
人工智能革命催生了对训练前沿模型的处理能力的巨大需求,而英伟达正用其高端 GPU 来满足这一需求。然而,2025 年人工智能突然转向推理和代理人工智能,暴露出内存管道方面的缺口,d-Matrix 希望通过其创新的 3D 堆叠数字内存计算 (3DIMC) 架构来解决这个问题,该架构已于上周在 Hot Chips 大会上进行了展示。
甚至在2022 年底ChatGPT 的推出引发人工智能革命之前, d-Matrix的人们就已经发现了对更大、更快内存的需求,以满足大型语言模型 (LLM) 的需求。d-Matrix 首席执行官兼联合创始人 Sid Sheth 已经预测,由于OpenAI和谷歌的 LLM 项目前景光明,人工智能推理工作负载将激增,这些项目已经在人工智能领域及其他领域引起了关注。
“我们认为这将会持续很长一段时间,”Sheth在 2022 年 4 月接受BigDATAwire采访时谈到了LLM 的变革潜力。“我们认为,未来 5 到 10 年,人们基本上会倾向于使用 Transformer,而这将成为未来 5 到 10 年 AI 计算的主要工作。”
Sheth 不仅准确预测了 Transformer 模型的变革性影响,还预见到它最终将导致 AI 推理工作负载激增。这为 Sheth 和 d-Matrix 带来了商机。问题在于,基于 GPU 的高性能计算架构虽然能够很好地训练规模越来越大的 LLM 和前沿模型,但却并非运行 AI 推理工作负载的理想之选。事实上,d-Matrix 发现,这个问题一直延伸到 DRAM,它无法高效地以所需的高速传输数据来支持即将到来的 AI 推理工作负载。
内存增长落后于计算增长(来源:d-Matrix)
d-Matrix的解决方案将技术创新的重心放在内存层,这一方向的选择基于对AI推理场景内存需求的针对性考量。在AI推理过程中,传统DRAM内存的性能表现存在局限,其数据读写速度与带宽难以适配高频次、大规模的数据调用场景,可能成为制约整体效率的因素。而SRAM(静态随机存取存储器)虽成本相对较高,但具备更快的访问速度和更低的延迟,在满足AI推理对实时性的需求方面展现出适应性。
d-Matrix采用数字内存计算(DMIC)技术,该技术的核心设计是将处理器与SRAM模块进行直接融合。其Nighthawk架构的实现方式为,将DMIC芯片嵌入SRAM卡,这些SRAM卡可直接接入PCI总线,在硬件适配层面具有一定的便利性。另一架构Jayhawk则具备die-to-die功能,通过芯片间的直接互联支持处理能力的横向扩展,以应对不同规模的计算需求。
上述两种架构均被整合至d-Matrix的旗舰产品Corsair中。该产品采用最新的PCIe Gen5规格,以提升接口层面的数据传输效率,同时具备150 TB/s的内存带宽,这一指标使其在数据处理速度上具备显著特点。从应用场景来看,Corsair的性能参数使其能够适配大模型推理等对内存带宽要求较高的任务,为相关领域的硬件部署提供了一种可选方案。
快进到2025年,Sheth的许多预测都已成真。我们正处于从AI训练到AI推理的重大转变之中,代理AI将在未来几年推动巨额投资。d-Matrix一直紧跟新兴AI工作负载的需求,并于本周宣布其采用三维堆叠DMIC技术(或3DMIC)的下一代Pavehawk架构目前正在实验室中运行。
Sheth 相信 3DMIC 将提供性能提升,帮助 AI 推理突破内存壁垒。
Sheth在 LinkedIn 的一篇博文中写道:“AI 推理的瓶颈在于内存,而不仅仅是 FLOP(浮点运算)。模型发展迅速,传统的 HBM 内存系统成本高昂、功耗高且带宽受限。3DIMC改变了游戏规则。通过三维堆叠内存并将其与计算更紧密地集成,我们显著降低了延迟,提高了带宽,并释放了新的效率提升。”
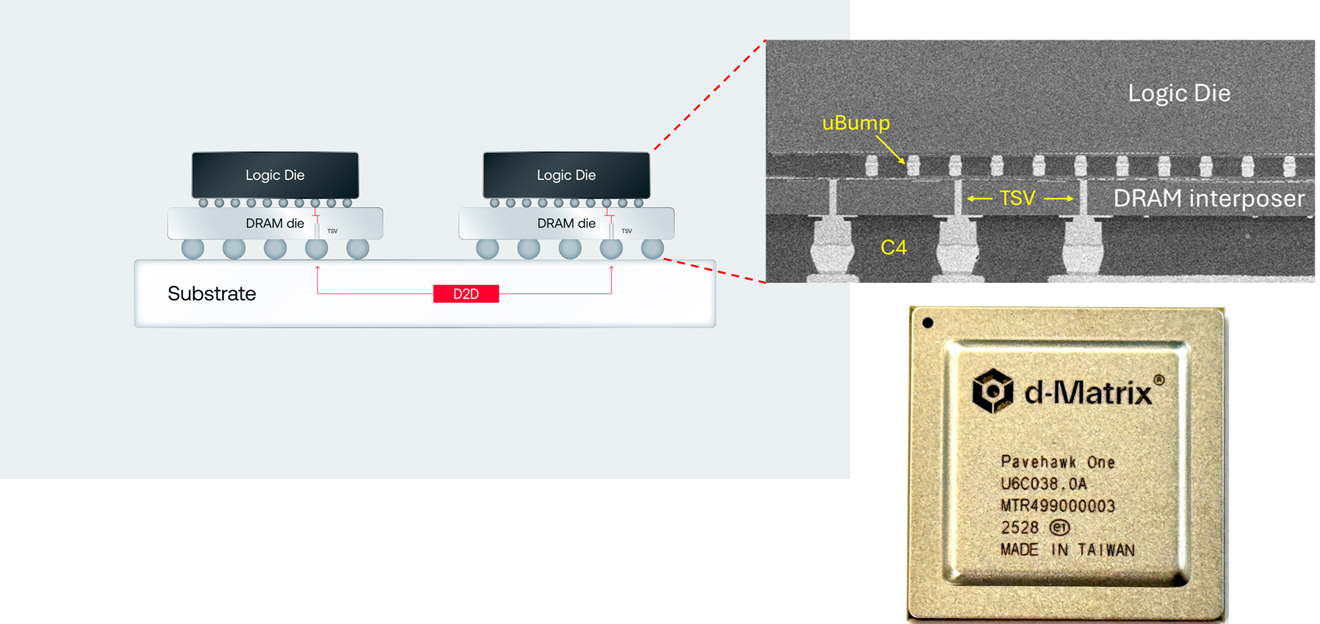
d-Matrix全新Pavehawk架构支持3DMIC技术(图片来源:d-Matrix)
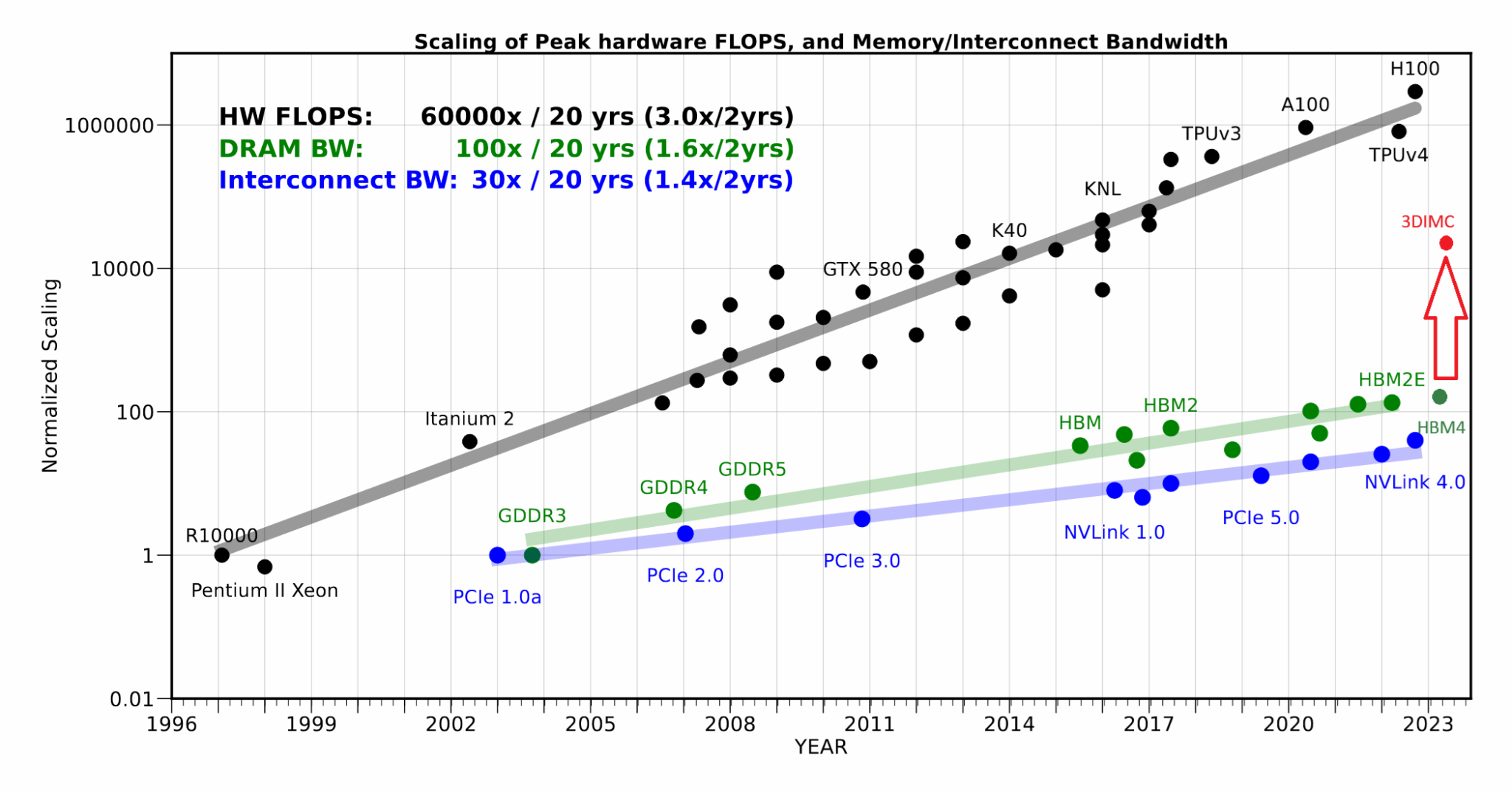
内存壁垒问题多年来一直存在,其根源在于内存和处理器技术进步的不匹配。d-Matrix 创始人兼首席技术官 Sudeep Bhoja 在本周的一篇博客文章中写道:“行业基准测试显示,计算性能每两年增长约 3 倍,而内存带宽却仅落后 1.6 倍。结果就是差距越来越大,昂贵的处理器只能闲置,等待数据到来。”
Bhoja写道,虽然3DMIC技术无法完全弥补与最新GPU的差距,但它有望缩小差距。随着Pavehawk的上市,该公司目前正在开发利用3DMIC的下一代内存处理架构,名为Raptor。
Bhoja写道:“Raptor……将把3DIMC融入其设计中——这将受益于我们和客户在Pavehawk测试中积累的经验。通过垂直堆叠内存并与计算芯片紧密集成,Raptor有望突破内存壁垒,并释放全新的性能和TCO水平。”
究竟好多少?据 Bhoja 称,d-Matrix 希望在使用 3DIMC 运行 AI 推理工作负载时,与 HBM4 相比,内存带宽和能效分别提高 10 倍和 10 倍。
Bhoja 写道:“这些并非渐进式的提升,而是阶跃式的改进,重新定义了大规模推理的可能性。” 通过将内存需求置于我们设计的核心——从 Corsair 到 Raptor 乃至更远的未来——我们确保推理速度更快、更经济,并且在大规模下更具可持续性。
本文转自媒体报道或网络平台,系作者个人立场或观点。我方转载仅为分享,不代表我方赞成或认同。若来源标注错误或侵犯了您的合法权益,请及时联系客服,我们作为中立的平台服务者将及时更正、删除或依法处理。




联系电话:
010-61853490
新闻投稿:
server@icviews.cn
商务合作:
business@icviews.cn
问题反馈:
19800315212(微信同号)


半导纵横公众号

半导纵横小程序