AMD、高通旗下硬件支持OpenAI gpt-oss开放推理模型
OpenAI以Apache 2.0许可证的形式推出了两款gpt-oss系列开放推理模型,其中参数规模较小的gpt-oss-20b模型可在仅配备16GB内存的边缘设备上运行、参数更多的gpt-oss-120b 则能在单个80GB GPU上高效运行。
AMD 与高通均宣布旗下硬件支持 gpt-oss 系列开放模型,具体是 AMD 锐龙 AI Max+ 395 处理器支持 gpt-oss-120b、AMD Radeon RX 9070 16GB 显卡支持 gpt-oss-20b、高通旗舰骁龙平台支持 gpt-oss-20b。
AMD 宣称锐龙 AI Max+ 395 是全球首款能运行 gpt-oss-120b 模型的消费级 AI PC 处理器。锐龙AI Max+395处理器凭借128GB统一内存架构,将96GB分配给GPU的方案,成功突破gpt-oss-120b模型61GB显存的需求瓶颈。30 Token/s的推理速度虽不及顶级数据中心GPU,但在消费级市场已属突破。Radeon RX 9070显卡对gpt-oss-20b的优化,则瞄准了中端推理市场。
高通则充分发挥移动端优势,根据早期测试 gpt-oss-20b 可在端侧实现出色思维链推理表现,开发者可通过 Hugging Face 和 Ollama 等热门平台在搭载骁龙芯片的设备上访问 gpt-oss-20b 模型并充分发挥其功能。
从技术参数看,AMD方案在内存带宽管理上采用GGML框架的MXFP4量化技术,将模型精度控制在可接受范围内。高通则依靠长期积累的AI加速器IP,在能效比方面建立优势。
有评论称,AMD和高通此举是挑战英伟达AI霸主地位的重要尝试。竞争将围绕三个核心维度展开:首先是边缘计算场景的渗透率。医疗、工业等对数据隐私要求高的领域可能成为突破口。其次是成本效益比,采用开放模型的TCO(总体拥有成本)优势需要实际案例验证。最后是软件生态的成熟速度,PyTorch等框架的适配进度将直接影响开发者迁移意愿。
未来12-18个月将是关键窗口期。如果AMD和高通能实现:在3个以上主流行业落地标杆案例;开发者工具下载量突破百万级;建立可持续的商业模式,那么AI加速器市场有望形成三足鼎立格局。否则,开放模型可能仅停留在技术演示阶段,难以真正动摇现有市场结构。
OpenAI发布开源模型GPT-OSS
近日,OpenAI发布两款开放权重AI推理模型。其中参数量达到1170亿的gpt-oss-120b能力更强,可以由单个英伟达专业数据中心GPU驱动;参数量210亿的gpt-oss-20b模型,则能够在配备16GB内存的消费级笔记本电脑上运行。
两款模型都以宽松的Apache 2.0许可证发布,企业在商用前无需付费或获得许可。
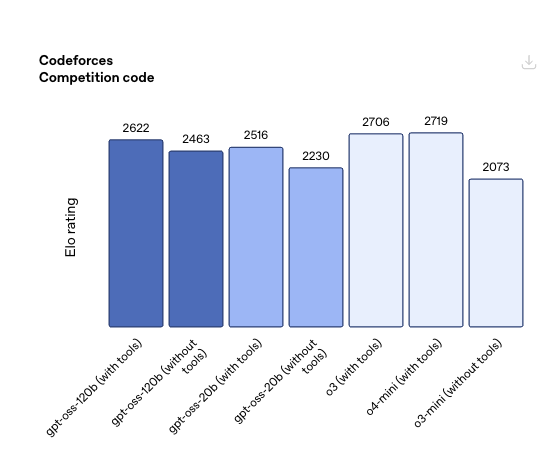
就模型性能而言,GPT-OSS大致位于开源模型的第一梯队,但整体略逊于自家的GPT-o3和o4-mini。例如在Codeforces(带工具)的编程测试中,gpt-oss-120b和gpt-oss-20b的“跑分”分别为2622和2516分,虽然高于一些头部开源模型,但依然比不过头部闭源推理模型。而在“人类最后的考试”测试中,两款开源模型的得分分别为19%和17.3%,同样比不过o3。
与闭源模型类似,两款开放模型都采用了混合专家(MoE)技术,处理问题时只会激活较少的参数。对于1170亿参数量的gpt-oss-120b,处理每一个token时仅激活51亿个参数。
值得注意的是,相较o3和o4-mini模型,两款开放模型也会出现更多的幻觉。OpenAI解释称,由于较小的模型拥有的世界知识比大型前沿模型少,所以更容易产生幻觉也在意料之中。在OpenAI内部用于衡量模型对人物知识准确性的PersonQA基准测试中,gpt-oss-120b和gpt-oss-20b分别对49%和53%的问题产生幻觉,达到o1模型的3倍多,也高于o4-mini模型的36%。
本文转自媒体报道或网络平台,系作者个人立场或观点。我方转载仅为分享,不代表我方赞成或认同。若来源标注错误或侵犯了您的合法权益,请及时联系客服,我们作为中立的平台服务者将及时更正、删除或依法处理。

联系电话:
010-61853490
新闻投稿:
server@icviews.cn
商务合作:
business@icviews.cn
问题反馈:
19800315212(微信同号)


半导纵横公众号

半导纵横小程序