ISSCC 2025:中科院微电子所存算一体芯片论文入选
当前,边缘智能计算设备部署神经网络时,往往需要通过训练微调以提升网络精度。但基于远程云端训练的方法存在高延迟、高功耗以及存在隐私泄露风险等缺点,因此,实现支持本地训练的存算一体技术至关重要。
传统的存算一体宏仅支持网络推理,无法进行网络训练所需要的转置运算。现有方案无法对训练中的前向与反向传播过程中的乘累加电路进行有效的复用,造成了功耗和面积上的浪费,且仅支持定点数制的模拟存算方案,在精度上也存在较大的缺陷。如何有效实现支持转置操作的高能效、高精度的存算一体宏,是当前存算一体领域亟须解决的问题。
针对以上问题,集成电路制造技术全国重点实验室张锋研究员团队设计出可转置的近似精确双模浮点存算一体宏芯片。通过提出的循环权重映射SRAM方案,芯片可在前向与反向传播时复用乘加单元,在实现了转置功能的同时,相对之前的转置存算一体宏单元大大提升了能效与算力密度。
通过提出的有符号定点尾数编码方式与向量粒度预对齐方案,芯片实现了多种浮点、定点数制的兼容支持,相较于传统的粗粒度浮点预对齐方案有着更小的精度损失。
通过提出的近似精确双模的乘加电路设计,芯片可在精度要求低的推理环节时开启近似模式,从而获得12%的速度提升与45%的能耗降低,可在精度要求高的训练环节时开启精确模式确保没有精度损失。
该存算一体宏芯片在28nm CMOS工艺下流片,可支持BF16、FP8浮点精度运算以及INT8、INT4定点精度运算。BF16浮点矩阵-矩阵-向量计算均值能效达到48TFLOP/W,峰值能效达到100TFLOPS/W;FP8浮点矩阵-矩阵-向量计算均值能效达到192.3TFLOP/W,峰值能效达到400TFLOPS/W。这一研究结果为应用于边缘端训练的存算一体架构芯片提供了新思路。
上述工作以“A 28nm 192.3TFLOPS/W Accurate/Approximate Dual-mode Transpose Digital 6T-SRAM Compute-in-Memory Macro for Floating-Point Edge Training and Inference”为题入选 ISSCC 2025。微电子所博士生袁易扬为第一作者,张锋研究员与北京理工大学李潇然助理教授为通讯作者。该研究成果得到了科技部重点研发计划、国家自然科学基金、中国科学院战略先导专项等项目的支持。

图1. 28nm 基于外积的数模混合浮点存算一体宏芯片:(a)芯片显微镜照片,(b)芯片特性总结表。
ISSCC 2025:中国论文入选数量第一
2024年11月,ISSCC2025中国区发布会介绍了ISSCC 2025的论文入选情况以及最新研究动向。
据介绍,ISSCC2025共收到914篇论文,创论文投稿新高度,较ISSCC2024的873篇增长4.70%;经过技术委员会评审,有14个国家的96个机构的246篇论文入选(不包括4篇主题演讲和8篇特邀报告),其中来自高校的193篇,占比78.5%;来自工业界的48篇,占比19.5%;来自研究机构的为5篇,占比2%。
从大区来看,远东区有165篇,其中来自中国的有86篇,韩国有49篇,日本有11篇,新加坡和印度各有1篇;美洲区有53篇;欧洲区28篇。
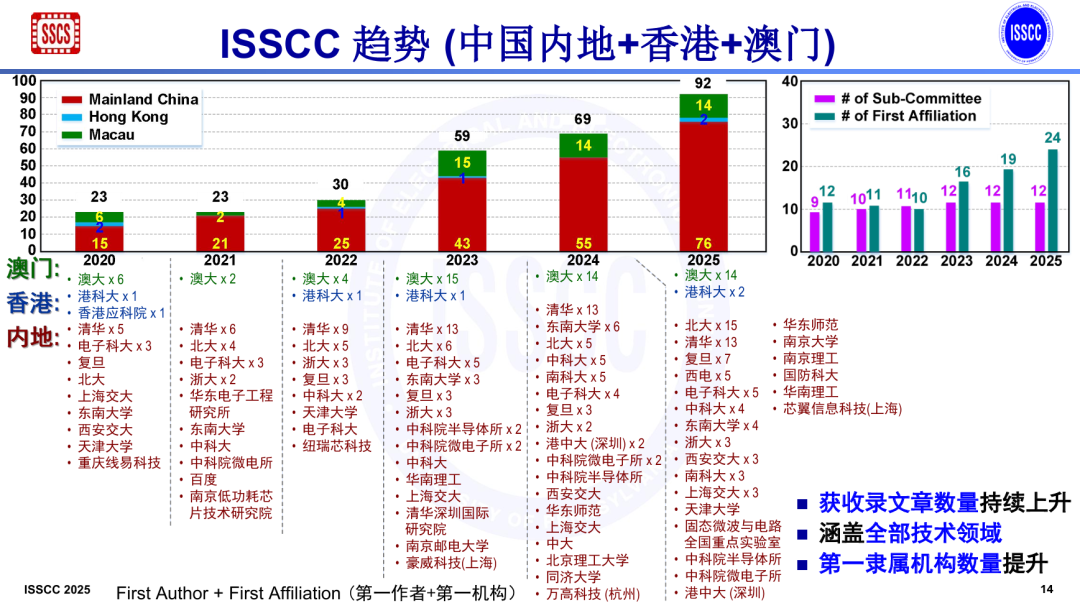
其中,中国论文入选数量继续保持第一,从2024年的86篇(中国内地55篇,中国澳门14篇,中国台湾17篇)增至ISSCC 2025的112篇(中国内地76篇,中国香港2篇,中国澳门14篇,中国台湾20篇)。
值得注意的是,中国内地在ISSCC发表论文的高校增至21所,同时ISSCC 2025共评出57篇亮点文章,中国内地有15篇。
本文转自媒体报道或网络平台,系作者个人立场或观点。我方转载仅为分享,不代表我方赞成或认同。若来源标注错误或侵犯了您的合法权益,请及时联系客服,我们作为中立的平台服务者将及时更正、删除或依法处理。




联系电话:
010-61853490
新闻投稿:
server@icviews.cn
商务合作:
business@icviews.cn
问题反馈:
19800315212(微信同号)


半导纵横公众号

半导纵横小程序