新型AI处理器将开发成本降低40倍
2025年2月,东京大学工学研究科讲师小菅敦武、研究生申在元、项目教授滨田元嗣等的研究小组宣布,开发出了“结构化ASIC型AI处理器”,实现了高能效,同时将开发成本降低至传统的四十分之一。
所开发的AI处理器采用结构化ASIC技术。他们开发出“通孔可编程神经元阵列”技术,即将预先实现运算电路和布线的基底芯片制作至上层布线的中间,仅使用一层通孔布线构建出适用于特定AI处理的AI处理器电路。
结构化ASIC是一种各项特性表现皆介于FPGA与ASIC间的订产型芯片,它在量产成本、逻辑门利用率、功耗用电、效能速度等表现上优于FPGA,但又不如纯ASIC表现的优异,同时也具有FPGA的可编程化逻辑功效,以及加速芯片的研发设计速度与修改弹性,使芯片能更快完成并投入市场,以及减省日后修改电路的成本耗费。
结构化ASIC依然要开制光罩、依然要透过晶圆厂代产,但开制的光罩数目低于ASIC,且因具有一定的电路修改弹性,在弹性范畴内可不用再开制与修改光罩,也能够满足新修改需求,即弹性高于ASIC,不过若修改幅度过大,超过弹性范畴,依然需要编修光罩电路,即是开制新光罩来取代旧光罩。
目前提供结构化ASIC的知名厂商主要有Altera、AMI Semiconductor、Fujitsu、NEC、ChipX(也称为Chip Express)、LSI Logic等,其中LSI Logic已在2006年4月宣布淡出结构化ASIC业务。
到目前为止,制造一个人工智能处理器需要数十个光掩模。利用东京大学研究小组开发的技术,仅用一层VIA布线即可完成布线的定制。这意味着只需要准备一个光掩模,大大降低了开发光掩模的成本。
他们还开发出了“位神经元时序电路”技术,通过时分方式重用电路和信号布线以减少电路面积,以及“功能选择性非线性神经网络”技术,将深度神经网络的加权系数从16位减少到三个值(+1,-1,0),同时保持较高的准确率。通过使用三个加权系数,所需的信号线数量减少了。
通过结合这些技术,信号布线数量可以减少 1024 倍,从而节省空间。他们成功在小于10 mm2的小电路面积的结构化ASIC中实现AI功能。
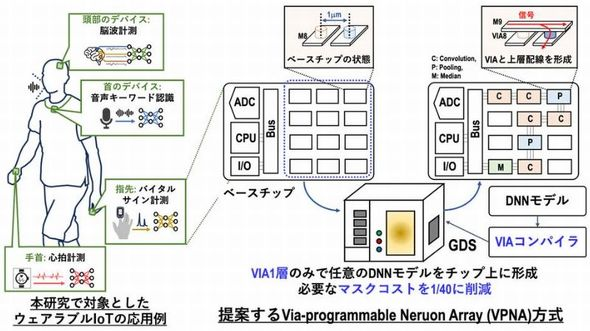
新开发的AI处理器概述。来源:东京大学
此外,该公司还开发了“VIA Compile”技术,该技术以任意深度神经网络作为输入,半自动地将其转换为VIA布局信息,并将其转化为半导体设计图。相信此举将减轻设计工程师的开发负担,并节省开发成本。
研究小组采用40纳米CMOS工艺制作了外形尺寸为3×3毫米的原型芯片,并对其特性进行了评估。结果显示,当电源电压为0.5V时,整个深度神经网络的功率效率为2.2 TOPS/W。据称该值的节能效果比 FPGA 高 8.4 倍。
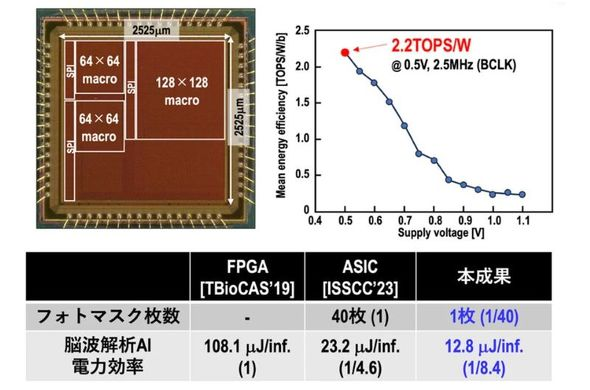
原型芯片外观及性能评估数据。来源:东京大学
至于,在哪些应用场景下会选择结构化ASIC?如今,无线网络、云服务提供商和其他企业希望能实现高性能,降低功耗和总拥有成本,硬件加速正帮助满足这一快速增长的需求,尤其是通过定制逻辑实现的硬件加速。例如,在高带宽无线服务中,5G 需要在有限的功率预算内提高时钟速率。
在早期阶段,尤其是随着网络的不断发展,面向无线设备的可编程产品在加速某些功能方面比固定硬件更具设计优势。在云数据中心,定制逻辑可以加速与存储、安全等功能相关的算法。边缘和嵌入式应用可能会受益于 AI 推理加速。在具有挑战性的散热预算条件下,还可以通过加速过渡到最新的 8K 高清视频标准。
在硬件设计方面,系统架构师有多种类型的定制逻辑解决方案可供选择。FPGA、结构化 ASIC 和 ASIC 均属于定制逻辑连续体。为了平衡灵活性、性能、功耗和总拥有成本需求,以及面市时间要求,架构师需要选择最适合所在环境的硬件类型。
本文转自媒体报道或网络平台,系作者个人立场或观点。我方转载仅为分享,不代表我方赞成或认同。若来源标注错误或侵犯了您的合法权益,请及时联系客服,我们作为中立的平台服务者将及时更正、删除或依法处理。


联系电话:
010-61853490
新闻投稿:
server@icviews.cn
商务合作:
business@icviews.cn
问题反馈:
19800315212(微信同号)


半导纵横公众号

半导纵横小程序