部署DeepSeek,AI芯片爆单
近日,AI芯片厂商Cerebras CEO Andrew Feldman在接受采访时表示,公司已经被运行DeepSeek-R1大语言模型的订单压垮。
2024年3月, Cerebras推出了其第三代芯片 WSE-3,性能达到了上一代WSE-2的两倍,可用于训练业内一些最大的人工智能模型。
WSE-3依然是采用了一整张12英寸晶圆来制作,基于台积电5nm制程,芯片面积为46225平方毫米,拥有的晶体管数量达到了4万亿个,拥有90万个AI核心,44GB片上SRAM,整体的内存带宽为21PB/s,结构带宽高达214PB/s。使得WSE-3具有125 FP16 PetaFLOPS的峰值性能,相比上一代的WSE-2提升了1倍。
与英伟达的H100相比,WSE-3面积将是H100的57倍,内核数量是H100的52倍,片上内存是H100的880倍,内存带宽是H100的7000倍,结构带宽是H100的3715倍。据悉,它在Llama3.1-8B上的推理速度比微软等公司使用英伟达 H100快了20倍。
Feldman 称,WSE-3通过使用 44GB片上SRAM,使得其能够以 16 位精度运行 Llama 3.1 8B 时,每秒能够生成超过1800个Token,而性能最好的基于英伟达H100的实例每秒只能生成超过 242 个Token。
其中,WSE-3 CS-3 系统凭借其至高1.2PB的内存容量,可训练比 GPT-4 和 Gemini 大 10 倍的下一代前沿模型。其可在单个逻辑内存空间中容纳 24000T 参数规模的模型,大大简化了开发人员的工作。另外,CS-3 适合超大规模 AI 需求,紧凑的四系统集群可以在一天内微调 70B 模型,而在使用最大规模的 2048 个 CS-3 系统集群时,可以在一天内完成 Llama 70B 模型的训练。
Cerebras 表示 CS-3 系统具有卓越的易用性,大模型训练中所需代码相较 GPU 减少 97%,仅需565行代码就可达成 GPT-3 大小模型的标准实现。
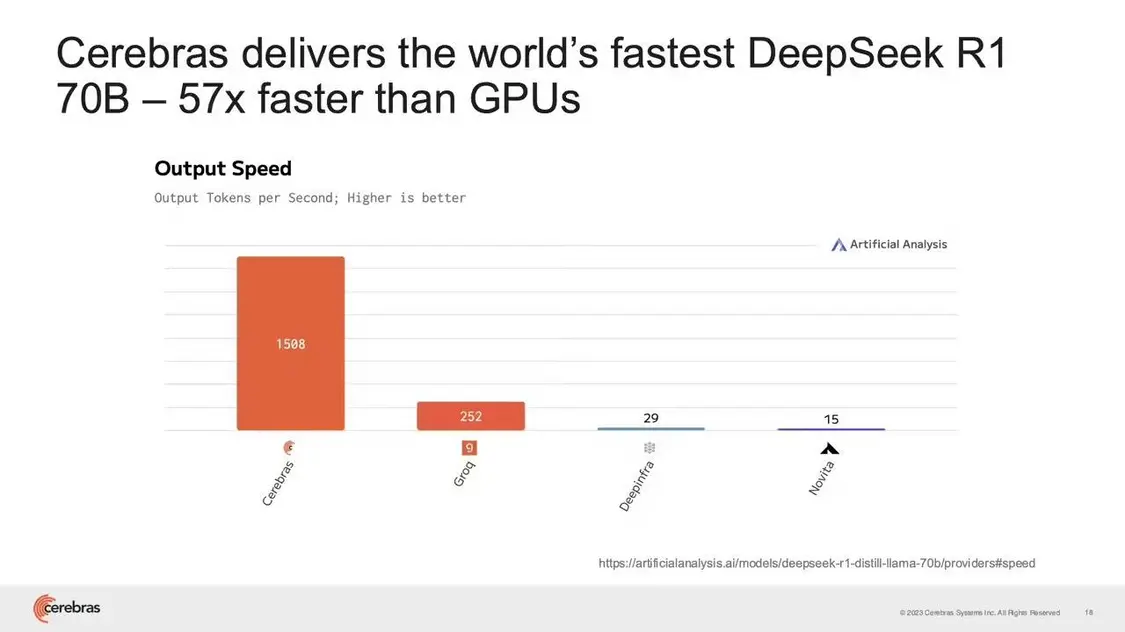
根据Cerebras显示,其AI芯片部署DeepSeek-R1 70B可以达到1508 tokens/s的性能,比 GPU 快很多。
用户在使用包括 DeepSeek-R1 等“推理模型”时,输入提示词后需要时间等待是一大痛点。而Cerebras因为采用了名为 Chain-of-thought(CoT)的方法来增强模型的推理能力,将多步问题分解为中间步骤,允许模型在需要时执行额外的计算。推理时逐字进行推理,对整段提示词的推理需要进行多次,需要大量算力。
客户可以通过蒸馏将大模型的“知识”转移到小模型来缓解痛点,大模型通常被称为教师模型,较小的模型被称为学生模型。
为了改善使用 DeepSeek 模型的体验,Cerebras 为客户提供的标准做法是利用 DeepSeek 开源在 Hugging Face 的模型参数(权重)作为教师模型,蒸馏出一个较小的学生模型用于实际部署,Cerebras 在官网表示 DeepSeek R1 蒸馏到 Llama 70B 后精度几乎没有下降。
Feldman 表示,DeepSeek 是第一个顶级的开源推理模型,是开源 AI 的重大胜利。通过蒸馏技术,开源模型只需要公开模型参数(权重),研究人员不需要访问源码也可以复制新 AI 模型的进步。他认为,DeepSeek 的经济性不仅震惊整个人工智能行业,更可以使尖端 AI 芯片和网络技术获得更多投资。
有些人认为计算成本的下降将导致市场萎缩,但在过去50年,无论是电脑还是手机,价格的降低都推动了普及,这无一不证明了降低成本反而会扩大市场份额。
Cerebras 从去年 8 月开始提供公共推理服务,自称是“世界上最快的人工智能推理服务提供商”。该公司目前只提供蒸馏后的 70B 模型,Feldman 表示,405B 的模型太贵了,客户更青睐价格实惠的模型,当然也有一部分客户认为准确性的提升值得更高的成本而选择更大的模型。
除了Cerebras,多家芯片初创公司及行业专家认为,DeepSeek加速了 AI 从训练到推理阶段的技术迭代,将推动新型芯片技术应用。随着客户采用并基于 DeepSeek 的开源模型进行开发,市场对“推理”芯片和计算资源的需求显著增加。
人工智能芯片初创公司 d-Matrix 的首席执行官西德・谢斯表示:“DeepSeek 已经证明,较小的开源模型也可以通过训练达到甚至超越大型专有模型的能力,而且成本仅为其零头。随着高性能小模型的广泛普及,推理时代已经到来。”他还透露,近期全球客户对加速“推理”模型计划的兴趣激增。
人工智能芯片制造商 Etched 的联合创始人兼首席运营官罗伯特・瓦亨也表示:“自 R1 发布后数十家企业寻求合作。企业正在将支出从训练集群转向推理集群。DeepSeek-R1 证明了推理计算已成为每个主要模型供应商的尖端技术方向,而思考并不廉价,我们需要越来越多的计算能力来为数以百万计的用户扩展这些模型。”
本文转自媒体报道或网络平台,系作者个人立场或观点。我方转载仅为分享,不代表我方赞成或认同。若来源标注错误或侵犯了您的合法权益,请及时联系客服,我们作为中立的平台服务者将及时更正、删除或依法处理。




联系电话:
010-61853490
新闻投稿:
server@icviews.cn
商务合作:
business@icviews.cn
问题反馈:
19800315212(微信同号)


半导纵横公众号

半导纵横小程序