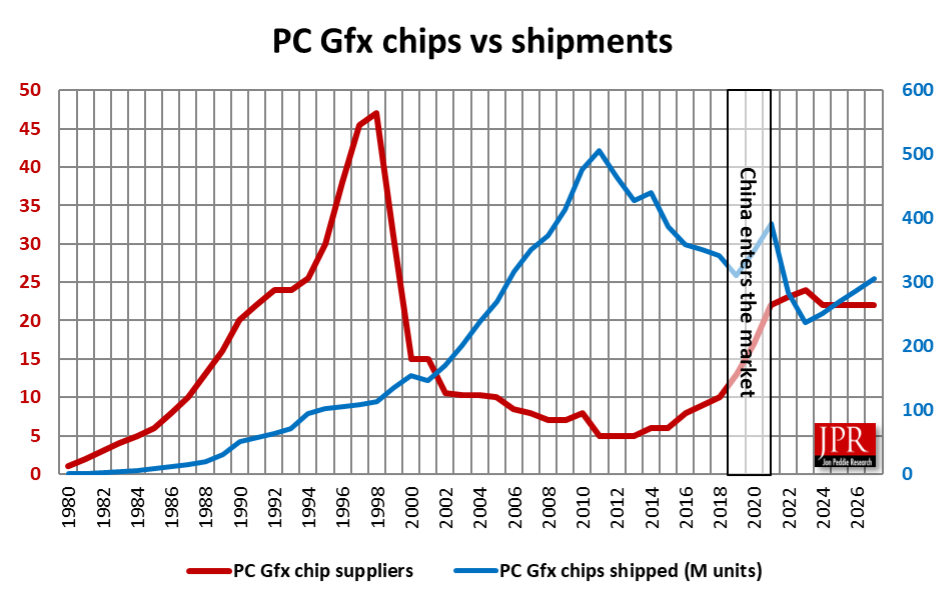
2024年GPU出货量将超过2.51亿块
根据IDC 的数据,2024 年 PC 出货量较 2023 年增长 1%,总计约2.627 亿台。因此,根据Jon Peddie Research 的数据,集成和独立图形处理器 (GPU) 的销量同比增长 6% 并超过 2.51 亿台也就不足为奇了。
GPU 的出货量通常超过客户端 CPU 的出货量,因为几乎所有台式机和笔记本电脑的处理器都配备了集成 GPU,而 AMD 和 Nvidia 等公司通常每年为客户端 PC 销售数千万个独立显卡处理器,这些处理器最终会用于也配备 iGPU 的系统。但是,看起来 CPU 和 GPU 的出货量在 2024 年都有所增加。
台式机独立 GPU 的出货量而言,2024 年的最终数字还有待观察。
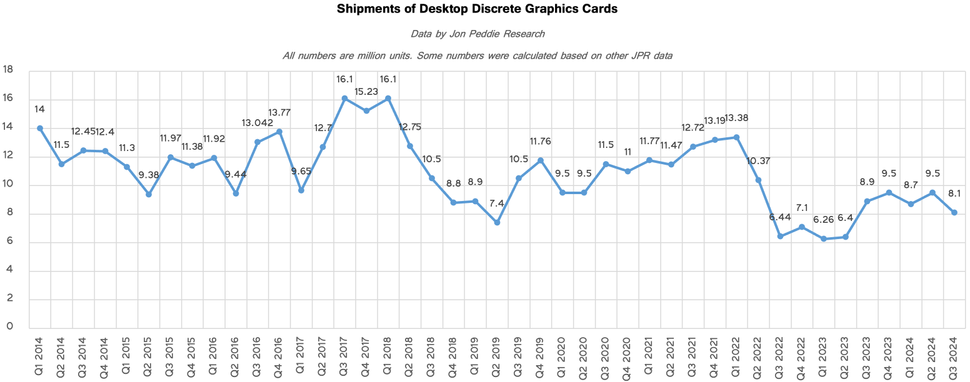
JPR 的数据显示,今年上半年,该行业为台式机系统出货了 1820 万张显卡,比 2023 年同期增长 46%。然而,2024 年第三季度显卡出货量总计 810 万台,低于 2023 年第三季度的 890 万台。
据悉,这是 AMD 库存调整以及Ada Lovelace和RDNA 3生命周期结束的结果。虽然独立 GPU 的销量通常会在第四季度回升,因为游戏玩家正在为新游戏的发布做准备,但去年可能并非如此。
鉴于上半年的强劲表现,2024 年显卡的出货量可能会与 2023 年持平,甚至可能超过 2023 年。然而,它们不太可能接近2022 年或 2021 年显卡的销量。
您可能会注意到,根据 IDC 的数据,2024 年系统的出货量超过了 JPR 报告的集成和独立 GPU 的出货量。这并不矛盾,因为 PC 制造商在系统内发货这些组件的几个月前就购买了 CPU 和 GPU。在第四季度,尽管销量很高,但他们往往会放慢购买速度——因为第一季度通常是客户端 PC 销售的疲软季度。
Nvidia Blackwell 架构深度解析
新的 Nvidia Blackwell GPU 架构将为即将推出的RTX 50 系列 GPU提供动力。接下来本文主要介绍 Blackwell RTX 50 系列 GPU 的架构变化。
Nvidia 没有提供关于新架构某些方面的大量细节,但从高层次来看,很多东西似乎与 RTX 40 系列 Ada Lovelace 架构相比没有太大变化。

Blackwell 的目标:针对新的神经工作负载进行优化、减少内存占用、新的服务质量功能和能源效率。这些听起来都是好事,但除了 RTX 5090 的 GPU 芯片明显更大(744 平方毫米,而 4090 为 608 平方毫米)之外,很多升级感觉更像是渐进的。
第四代 RT 核心的射线三角形相交率是 Ada 的两倍。它们还为 Mega Geometry 而打造,这可以帮助未来的虚幻引擎 5 游戏运行得更好。GPU 着色器也针对神经着色器进行了增强,并且还有一些其他新功能。
Blackwell将成为第一个超越 DisplayPort 1.4a 的 Nvidia GPU 系列,完全支持 DisplayPort 2.1 UHBR20(80 Gbps)。它们还将支持 PCIe 5.0,这是第一个实现这一转变的消费级 GPU。
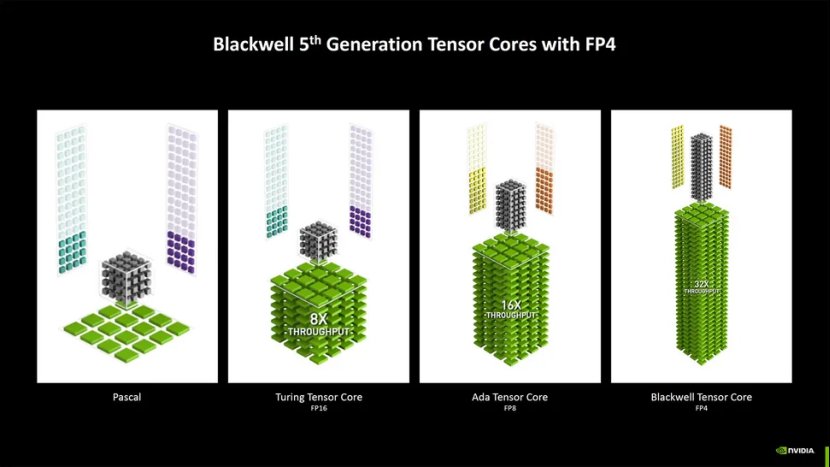
回到数字上,如果你采用“高达 4,000 AI TOPS”(每秒万亿次操作),那么在 5090 上会缩减到 3,400 TOPS(准确地说是 3352)。然后,你会发现提升的很大一部分来自原生 FP4 支持。因此,如果进行同类比较,RTX 5090 拥有 1,676 TFLOPS 的 FP8,而 RTX 4090 提供 1,321 TFLOPS FP8。这只是 27% 的增长——仍然相当可观,但并不大。
类似的扩展也适用于其他地方,例如 FP32 着色器计算。5090 提供高达 104.8 TFLOPS 的 FP32,而 RTX 4090 提供 82.6 TFLOPS。同样,这是一个 27% 的改进。让我们来看一下。与 RTX 3090 相比,RTX 4090 的 GPU TFLOPS 增加了 132%。这是一次令人兴奋的升级。
毫无疑问,5090 将比 4090 更快、更好,但它不会完全摧毁上一代——至少除非你想考虑多帧生成,我们对它的迷恋程度远不及 Nvidia 的营销部门。顺便说一句,在相同的台积电 4N 工艺节点上,5090 芯片也大 22%,晶体管数量增加了 21%。
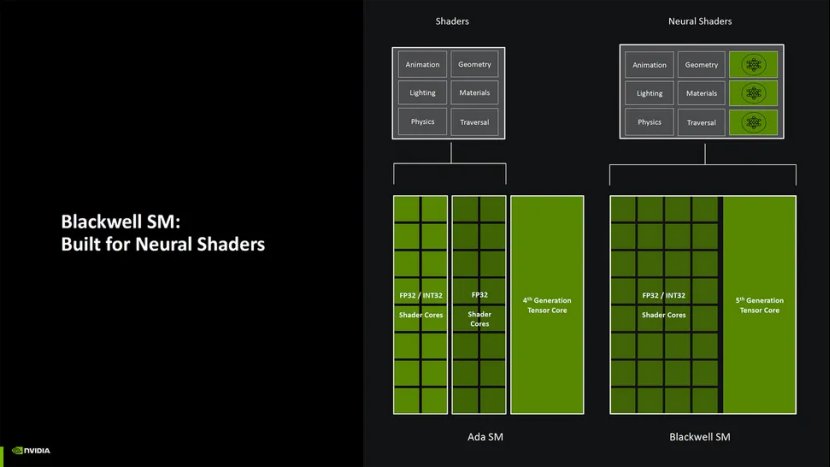
从架构上看,还有一些其他值得注意的变化。随着人工智能的使用和整数在此类工作负载中的使用增加,Nvidia 已使 Blackwell 中的所有着色器核心完全兼容 FP32/INT32。因此,在 Ampere(RTX 30 系列)中,Nvidia 将 FP32 CUDA 核心的数量增加了一倍,但一半仅用于 FP32,而另一半可以执行 FP32 和 INT32——INT32 通常用于内存指针计算。Ada 保持不变,现在 Blackwell 再次使所有 CUDA 核心统一,只是数量是 Turing 的两倍。
Nvidia还改变了着色器渲染管道中的某些内容,以允许更好地混合着色器和张量核心操作。它将其归类为神经着色器,虽然听起来其他 RTX 代仍然可以运行这些工作负载,但它们的速度会比 Blackwell GPU 慢。这似乎部分归功于 SER(着色器执行重新排序)的改进,其在 Blackwell 上的速度比在 Ada 上快两倍。
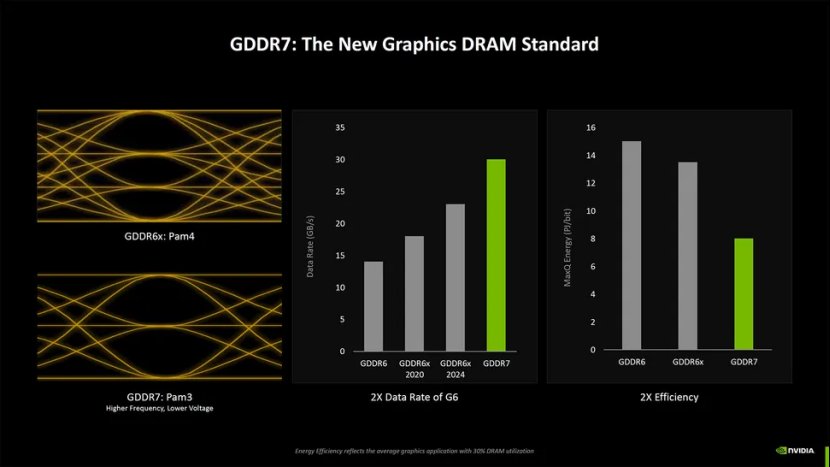
Blackwell 的内存也进行了升级,从 Ada 一代的 GDDR6 和 GDDR6X 升级为完整的 GDDR7。我们不知道这是否适用于所有 RTX 50 系列 GPU,但考虑到即使RTX 5070 笔记本电脑 GPU也有 8GB 的GDDR7,我们假设它是通用的。这是自 2018 年 RTX 20 系列首次推出 GDDR6(时钟频率仅为 14 Gbps)以来,我们在图形内存方面看到的首次全面转变。
大多数 Blackwell RTX 50 系列 GPU 将以 28 Gbps 的速度运行 GDDR7,速度是原始 GDDR6 芯片的两倍,但仅比许多高规格 RTX 40 系列 GPU 中使用的 21 Gbps GDDR6X 芯片快 33%。 RTX 5080 的速度提升至 30 Gbps GDDR7,几乎是 2080 Super 15.5 Gbps 内存的两倍。
内存接口宽度没有变化,RTX 5090 除外。它将在发布时获得一个巨大的 512 位接口和 32GB GDDR7 内存。未来的 3GB GDDR6 芯片为产品周期后期可能的 48GB 更新或专业/数据中心 GPU(翻盖模式下最高可达 96GB)留有余地,但 Nvidia 暂时不会正式评论或宣布此类事情。
RTX5080 仍然具有 256 位接口和 16GB,因此虽然它的带宽比 RTX 4080 Super 多 30%,但容量保持不变。 5070 Ti (与 5070 Ti Super 相比) 和 5070 (与 4070 相比) 也是如此,只是它们的带宽增加了 33% — — 28 Gbps 对 21 Gbps。
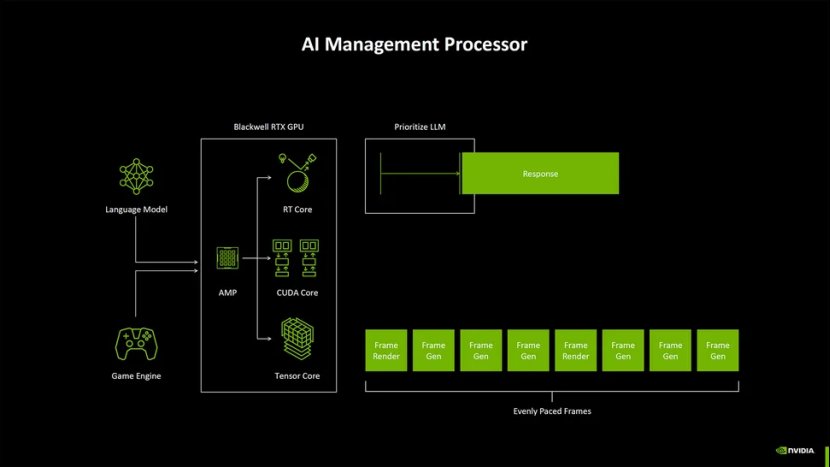
Blackwell 架构的另一个新功能是 AI 管理处理器。这里需要说明的是,Nvidia 根本没有提到光流加速器(又名 OFA),它是 Ada 一代的新产品,但现在可能已停产并由更强大的张量运算取代。
随着AI 工作负载的复杂性不断增加,以及更多 AI 模型同时运行的可能性(想象一下一个游戏进行升级、神经纹理、帧生成和 AI NPC),Nvidia 希望更好地调度资源。AI 管理处理器旨在做到这一点,并且显然可以提示正在运行哪种工作负载以及需要先完成哪些工作负载。因此,进行文本生成的 LLM 可能会稍微延迟一下,以便先完成 MFG(多帧生成)。Blackwell还改进了电源门控和能源管理,能够比前几代更快地进入和退出深度睡眠模式。
本文转自媒体报道或网络平台,系作者个人立场或观点。我方转载仅为分享,不代表我方赞成或认同。若来源标注错误或侵犯了您的合法权益,请及时联系客服,我们作为中立的平台服务者将及时更正、删除或依法处理。



联系电话:
010-61853490
新闻投稿:
server@icviews.cn
商务合作:
business@icviews.cn
问题反馈:
19800315212(微信同号)


半导纵横公众号

半导纵横小程序